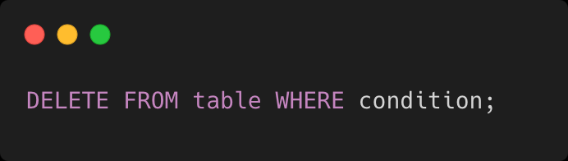
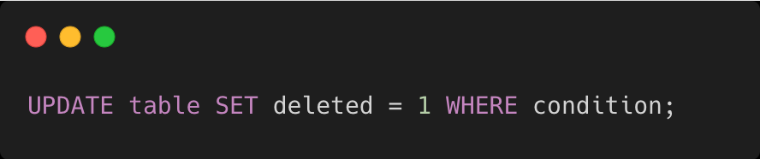
Hola, je vais vous présenter le début d'une nouvelle série d'articles dédiées à la construction d'un projet Web et Mobile en mettant à profit l'Architecture Hexagonale. Durant toute cette série, nous allons explorer comment la logique métier peut être partagée et gérée efficacement à travers différentes plateformes.
Nos objectifs
Nous allons avoir plusieurs objectifs à atteindre au fil de ce projet :
- Apprendre comment développer une application Web et Mobile à la fois en mettant à profit les technologies modernes (Nx, Expo, Remix, Vitest, etc.)
- Comprendre les principes de l'Architecture Hexagonale et comment l'appliquer pour optimiser le partage de la logique métier
- Gagner en compétence et en confiance pour lancer votre propre projet multi-plateforme, tout en développant une base de code propre et maintenable
La structure de la série
Comme je l'ai dis au début de ce premier article, ce projet donnera lieu à une série d'articles qui sera structurée de cette manière :
- Partie 1 (cet article) : présentation du projet et mise en place d'un monorepo avec Nx
- Partie 2 : développer sans UI avec l'Architecture Hexagonale
- Partie 3 : partager de la logique métier et des composants entre le Web et le Mobile
- Partie 4 : refactor serein avec les tests et l'Architecture Hexagonale
- Partie 5 : déploiement Web et Mobile avec Netlify et EAS
Le projet
Le projet qui va nous aider à mettre en avant l'Architecture Hexagonale est un outil de gestion de budget que l'on appellera broney (le bro qui t'aides à gérer ta money 😎). Cet outil sera composé de deux applications, une première, web, développée avec Remix et une deuxième, mobile, développée avec Expo. Nous aurons donc 2 applications React et React Native avec un package TypeScript qui contiendra la logique métier partagée entre ces 2 applications.
Stack
La Stack que j'ai choisi est très subjective, on y trouve quelques frameworks qui mérite selon moi plus de lumière (Remix notamment et Nx face à NextJS et Turborepo). Néanmoins il est important de comprendre que peu importe les frameworks et libraires utilisées, le coeur de l'application sera complètement agnostique et réutilisable dans n'importe quel contexte.
- Monorepo avec Nx
- Application mobile avec Expo
- Application web avec Remix
- Testing avec Vitest
- Style avec Tailwind pour le web et twrnc pour le mobile
- Animation avec Framer Motion pour le web et React Native Reanimated pour le mobile
- Déploiement de l'application web avec Netlify
- Base de données, authentification, etc. avec Supabase
- Formatage du code avec Prettier
- Validation du code avec ESLint
- CI/CD avec les GitHub Actions
- Gestion d'état avec Zustand
- Gestion des formulaires avec React Hook Form
- Validation des types avec Zod
- Logging avec Sentry
- Traductions avec FormatJS
- Utilitaire de date avec date-fns
Fonctionnalités
Pour mettre en avant l'Architecture Hexagonale nous allons avoir besoin de développer quelques fonctionnalités pour avoir de la logique métier. Nous allons nous focus sur les fonctionnalités suivantes :
- Mettre en place le storage : react native mmkv pour le mobile et localStorage pour le web
- Gérer les catégories : lister, ajouter, modifier et supprimer
- Gérer les portefeuilles : lister, ajouter, modifier et supprimer
- Gérer les transactions d'un compte : lister, ajouter, modifier et supprimer
- Authentification avec Supabase
- Dynamiser toute l'app avec Supabase
Modèle de données
Pour mettre en place les fonctionnalités nous allons avoir besoin des entités suivantes :
- Wallet, un portefeuille qui a un solde négatif ou positif (par exemple on peut avoir le portefeuille "Compte Principal Julien" qui a un solde positif de 1000€)
- Category, des catégories servant à préciser le contexte des transactions faites (par exemple on a les catégories "Maison", "Restaurants" et "Divertissements")
- Transaction, les transactions sont liées à un portefeuille et à une catégorie pour savoir où l'argent est transférée (par exemple on a une transaction du portefeuille "Compte Principal Julien" de 50€ sur la catégorie "Restaurants")
Mise en place du monorepo avec NX
Initialisation du projet
Nous allons utiliser les commandes de Nx pour initialiser notre projet.
➜ npx create-nx-workspace@latest
✔ Where would you like to create your workspace? · broney
✔ Which stack do you want to use? · none
✔ Package-based monorepo, integrated monorepo, or standalone project? · package-based
✔ Enable distributed caching to make your CI faster · Yes
Avec cette commande nous avons le projet Nx configuré de base et sans libs pour le moment. Nous allons travailler avec le style Package-Based Repos qui nous offre plus de liberté en limitant le couplage avec Nx si jamais on souhaite changer facilement d'outil de monorepo. Cela permet également d'avoir des node_modules différents pour chaque app ou lib du projet. En savoir plus sur les différents style d'implémentation de Nx.
Création de la lib core
Nous allons maintenant ajouter notre première lib, la plus importante : core. En effet, c'est dans cette lib que nous allons mettre notre Architecture Hexagonale et la logique métier qui sera utilisée par nos applications Web et Mobile.
➜ nx g @nx/js:lib libs/core
✔ Which unit test runner would you like to use? · vitest
✔ Which bundler would you like to use to build the library? Choose 'none' to skip build setup. · rollup
Cette commande nous a généré une lib avec le framework de test Vitest, une config eslint et prettier que l'on peut adapter à nos preferences que je ne détaillerai pas ici.
Il est possible de compiler notre lib avec la commande nx core build et d'executer les tests avec nx core test.
Mise en place de la CI
Maintenant que nous avons les tests setup ainsi que prettier et eslint, il est pertinent de mettre en place une CI pour avoir du feedback régulier sur la bonne tenue du code. Pour la CI nous allons simplement suivre la documentation de Nx et utiliser les GitHub Actions.
Nous allons donc simplement ajouter un fichier .github/workflows/ci.yml assez simple qui peut être étoffé.
name: CI
on:
push:
branches:
- main
pull_request:
jobs:
main:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
# Cache node_modules
- uses: actions/setup-node@v3
with:
node-version: 20
cache: 'yarn'
- run: yarn --no-progress --frozen-lockfile
- uses: nrwl/nx-set-shas@v4.0.4
- run: npx nx format:check
- run: npx nx affected -t lint,test,build --parallel=3
Cette simple CI permet vérifier le bon formatage prettier, d'effectuer les validations eslint et de build et de s'assurer que les tests sont sans erreurs.
Structure du projet
Rentrons plus en détails dans ce que l'on vise comme structure de projet une fois les apps mise en place et notre lib core développée avec l'architecture hexagonale.
- apps
- mobile : notre application React Native développée avec Expo
- web : notre application React développée avec React
- libs
- ui : nos composants React et React Native utilisés par les apps web et mobile
- tailwind : notre configuration tailwind utilisée par les apps web et mobile ainsi que la lib ui
- core : notre architecture hexagonale qui contient le coeur de notre application et toute la logique métier réutilisable par les apps web et mobile
Pour aller plus loin, on peut très bien envisager d'avoir une app en plus pour un Storybook.
La lib qui va nous intéresser et la lib core évidemment. Elle sera structurée de cette manière :
- libs
- core
- src
- wallet
- tests
- wallet.service.test.ts : la logique métier testées
- wallet.test.ts : les règles métiers testées
- domain
- wallet.ts : l'entité qui représente les portefeuilles et qui contient des règles métiers
- wallet.repository.ts: le contrat qui détermine comment manipuler l'entité pour lister, ajouter, etc.
- wallet.service.ts : le service qui consume une implémentation de contrat
- infrastructure
- in-memory-wallet.repository.ts : une implémentation du contrat
- local-storage-wallet.repository.ts : idem
- supabase-wallet.repository.ts : idem
- user-interface
- wallet.store.ts : un store zustand vanilla, utilisable dans n'importe quel environnement javascript et qui sera utilisé dans nos apps
- category
- ...
- ...
Nous verrons le contenu de chaque fichiers ainsi que les détails du fonctionnement de ces derniers dans le prochain article !
Conclusion
Nous avons terminé le premier article de cette série sur le développement d'une application web et mobile avec l'Architecture Hexagonale et le partage de la logique métier et des composants UI.
Dans cette première partie nous avons vu comment mettre un place un monorepo et nous avons pourquoi et comment ce monorepo va nous aider à partager la logique métier entre nos différentes applications. Nous avons également bien délimité le périmètre et les fonctionnalités attendues pour notre première version, le MVP, de broney.
Enfin, à la fin de cet article nous avons commencé à entrevoir la structure du projet en mettant en évidence l'Architecture Hexagonale, ce sera le thème de la deuxième partie : Développer sans UI avec l'Architecture Hexagonale.




.png)
.png)
.png)
.png)
.webp)
.png)
.png)