
L'origine
Le Test-Driven Development plus communément appelé TDD n'a pas été inventé par une seule personne mais par plusieurs développeurs. Kent Beck est souvent la personne la plus affiliée au TDD parce qu'il est celui qui l'a popularisé lors de ses travaux sur la méthodologie Extreme Programming à la fin des années 90. Néanmoins il est important de rappeler qu'il n'est pas le créateur de l'outil qu'est le TDD, il a été mis en place pour tout un tas de personne, dont notamment Martin Fowler (co-auteur du Manifeste Agile) ou encore Ward Cunningham et Ron Jeffries qui ont fondé l'Extreme Programming avec Kent Beck.

Un outil de travail
L'outil
Le TDD est un outil de travail qui permet au développeur de coder en étant guidé par les tests. Il permet d'avancer étape par étape, petit pas par petit pas, pour avancer vers une solution toujours plus fiable.
Cette solution plus fiable est notamment due à sa forte proximité avec les principes SOLID. En effet, le TDD facilite la mise en place des principes SOLID. En écrivant d'abord des tests, il est plus naturel de concevoir un code simple et cohérent qui respecte les principes tels que l'encapsulation, le découplage, la gestion des dépendances et la séparation des responsabilités. On se retrouve plus naturellement avec des modules indépendants et l'injection de dépendances, ce qui conduit à du code plus propre.
Le TDD et les principes SOLID vont donc de pair pour une conception logicielle de qualité.
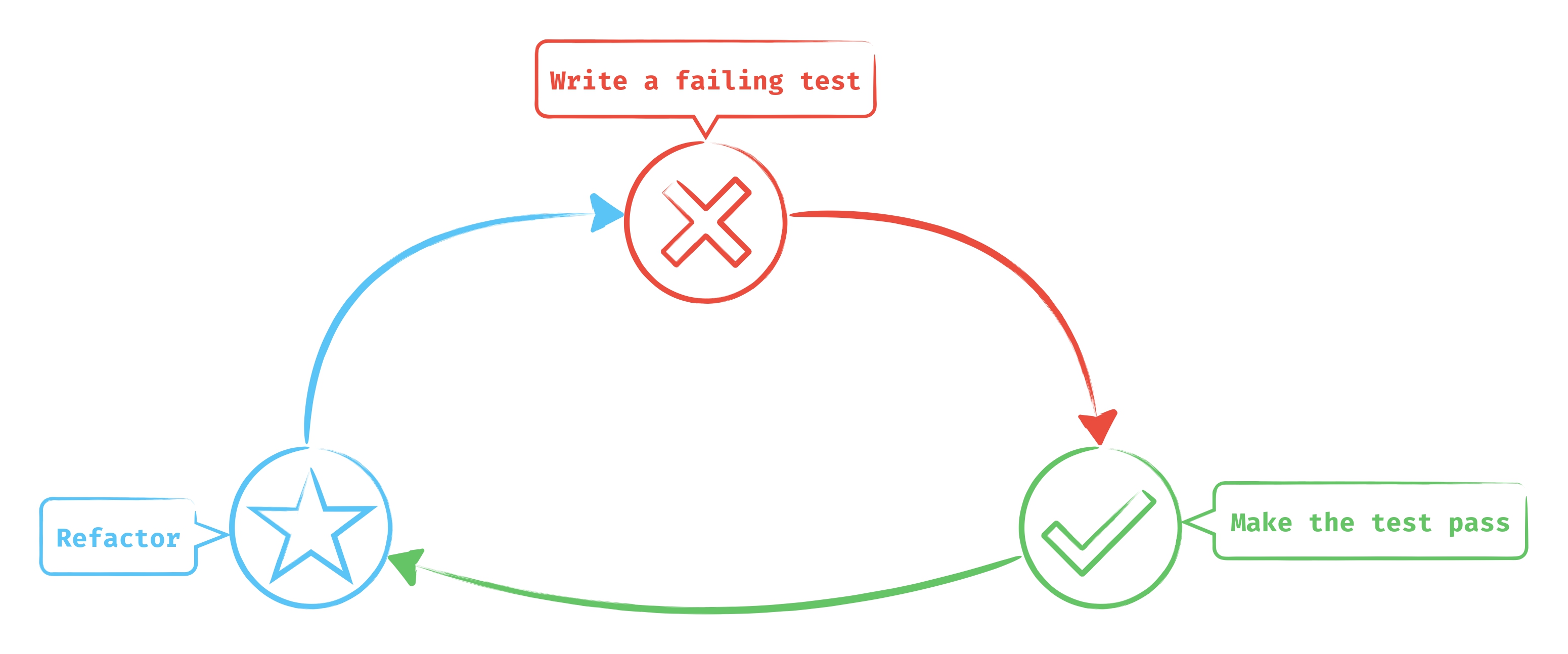
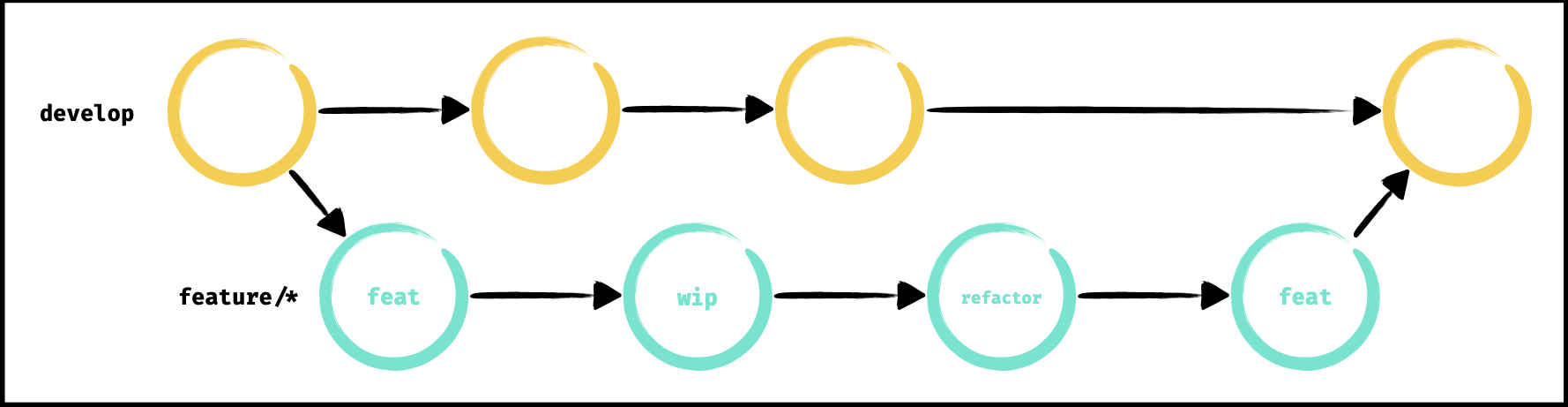
- Nous avons une première phase (rouge sur le schéma) où nous devons écrire un test qui échoue, basé sur une spécification. NB : on n'écrit pas de code de production (code final) tant que le test n'est pas en échec.
- La deuxième phase (verte sur le schéma) consiste à faire passer le test en succès en écrivant du code de production et tout en restant le plus simple possible. NB : on écrit uniquement le code nécessaire pour faire passer le test et sans retourner dans le code du test.
- La dernière phase (bleue sur le schéma) concerne le refactoring. On met à jour le code en appliquant les bonnes pratiques, le clean code, etc. Une fois que le refactoring est fait, si les tests passent toujours, on conserve le refactor et on passe aux prochaines spécifications, sinon, on annule le refactor et on essaye autre chose. NB : ne doit jamais effectuer de refactoring dans les autres phases, seulement ici.
L'approche TDD est un développement itératif et incremental qui met l'accent sur la qualité du code.
Le manifeste
Le TDD respecte certains principes qui sont :
- Baby steps instead of large-scale changes
On avance petit pas par petit pas pour avoir une boucle de feedback rapide et régulière.
- Continuous refactoring instead of late quality improvements
On améliore le code en continue, on s'en occupe tout de suite parce qu'un refactor annoncé pour plus tard n'arrive finalement en général jamais.
- Evolutionary design instead of big design up front
On développe ce qui est nécessaire et suffisant et on évolue progressivement.
- Executable documentation instead of static documents
Les tests mis en place pendant le TDD sont en réalité une documentation executable. L'idée est de lier la documentation avec le code pour s'assurer qu'elle est bien à jour et maintenue.
- Minimalist code instead of gold-plated solution
Un code simple et qui fonctionne plutôt qu'une solution surdimensionnées avec un niveau de complexité bien trop élevé et pas nécessaire.

Le test propre
Given When Then
L'approche Given When Then est basée sur une convention développée dans le cadre du Behaviour-Driven Development autrement appelé BDD. Il s'agit d'une approche de développement axée sur la collaboration et la spécification du comportement à travers ds scénarios clairs et compréhensibles.
En utilisant cette convention on divise le test en trois parties :
- Given, la condition préalable au test
- When, l'exécution du système testé
- Then, le comportement attendu
Exemple : Given user is not logged in When user logs in Then user is logged in successfully
Should When
L'approche Should When est une convention de nommage facile à lire et plus largement utilisée.
En utilisant cette convention on divise le test en deux parties :
- When, la condition préalable au test
- Should, le comportement attendu
Exemple : Should have user logged in When user logs in
Arrange Act Assert
Le modèle Arrange Act Assert autrement appelé AAA est un pattern descriptif et révélateur des intentions pour structurer le test.
Le test est alors organisé de la manière suivante :
- La partie Arrange contient la logique de configuration du test. C'est ici qu'on initialise le test.
- La partie Act execute le système que l'on souhaite tester. C'est ici qu'on fait l'appel d'une fonction, d'un composant, d'un call API, etc.
- La partie Assert, vérifie que le système testé se comporte comme prévu. C'est ici qu'on vérifie que le résultat obtenu correspond au résultat attendu.
Exemple :

F.I.R.S.T.
Le principe F.I.R.S.T. est un ensemble de principes qui définissent les caractéristiques d'un test propre et de qualité.
Ces caractéristiques sont les suivantes :
- Fast, un test doit être rapide et efficace de manière à pouvoir être exécuté fréquemment pour avoir un feedback régulier
- Independent, les tests doivent être indépendants les uns des autres afin d'être exécutable individuellement et efficacement
- Repeatable, un test doit être répétable dans n'importe quel environnement et à tout moment
- Self-Validating, les tests doivent retourner un succès ou un échec afin de vérifier lui même si l'exécution du test a réussi ou échoué sans évaluation manuelle
- Timely, les tests doivent être écrit avant ou en même temps que le code de production. ils doivent être maintenus et exécutés régulièrement
Quand l'utiliser ?
Quand ne pas l'utiliser plutôt !
Il n'est pas nécessaire et pas utile de faire du TDD quand on a pas de spécifications, quand les tests n'apportent rien, quand les tests sont trop lents, quand il n'y a pas de logique.
La démo
L'incontournable Fizz Buzz
Le Fizz Buzz est un exercice populaire qui permet d'appréhender la méthode TDD. Ce n'est qu'un échantillon et qu'un début de la méthode, mais ça reste intéressant.
Les spécifications sont les suivantes :
- On commence à compter à partir de 1 jusqu'à 100
- Lorsqu'on rencontre un nombre divisible par 3, on retourne "Fizz"
- Lorsqu'on rencontre un nombre divisible par 5, on retourne "Buzz"
- Lorsqu'on rencontre un nombre divisible par 3 et par 5, on retourne "Fizz-Buzz"
Nous allons utiliser le TypeScript pour mettre en place cet algorithme et le tester.
Première spécification
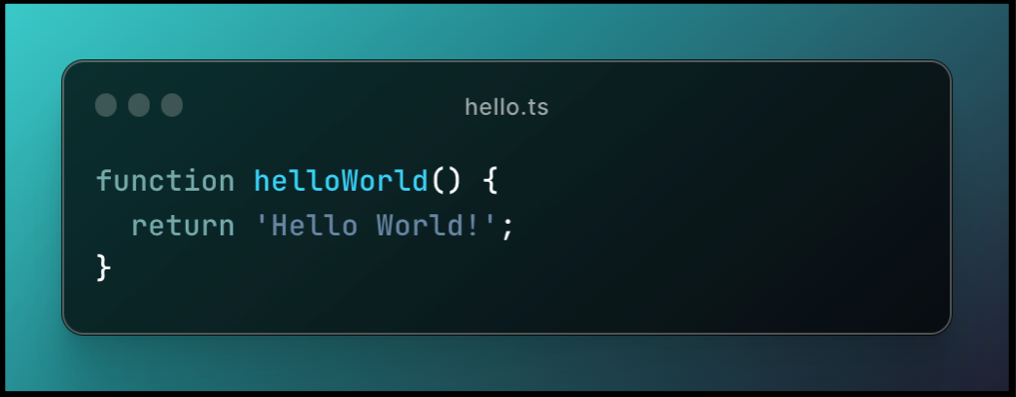
On créé un fichier test fizz-buzz.test.ts et on créé notre premier test qui va gérer la spécification où on teste le nombre 1.
.png)
Ici, le test ne passe pas parce qu'on a pas encore créé la fonction fizzBuzz() et encore moins l'algorithme associé. Nous sommes donc à la première phase du TDD, la phase rouge, celle où on écrit un test qui échoue.
On va maintenant passer à la deuxième phase du TDD, celle où on va faire passer le test au vert. Pour cela, on va créer le fichier fizz-buzz.ts et écrire le code permettant de gérer notre cas de spécification.
.png)
Ici, on pourrait avoir tendance à faire un return String(n) directement, mais TDD nous dit de commence par écrire le code le plus simple possible pour faire passer le test au vert, et en réalité le plus simple et rapide et de tout simplement retourner 1 directement.
On va passer au prochain test qui est de tester l'input 2.
.png)
Le test échoue parce qu'on a pas encore géré ce cas dans notre fonction. On retourne donc dans notre fonction et on essaye de résoudre ce cas de la manière la plus simple et rapide.
.png)
Ici, encore une fois, le plus rapide est de retourner 2 si on a 2 en input.
Maintenant on arrive à la troisième et dernière phase du TDD, celle du refactor. En effet, actuellement nos tests passent avec succès, le code est simple, mais il pourrait l'être encore plus en appliquant de bonnes pratiques.
On va donc revenir sur notre fonction fizzBuzz() sans modifier les tests.
.png)
Notre fonction est maintenant simple, propre et concise et les tests sont toujours verts. Notre refactor est donc réussit, on peut passer à la prochaine spécification.
Deuxième spécification
Nous devons maintenant faire en sorte de retourner Fizz si l'input est divisible par 3.
.png)
Le test échoue, on va maintenant gérer le cas du Fizz dans la fonction.
.png)
Le code le plus simple pour retourner Fizz quand on a 3 et de tester si n === 3.
On va maintenant gérer un deuxième cas où on a un nombre divisible par 3.
.png)
Le test échoue, on met à jour le code.
.png)
Le code le plus simple pour retourner Fizzquand on a 3 ou 6 et de faire un ||, mais on se rend bien compte qu'on peut améliorer le code en utilisant le modulo de 3. Les tests sont tous verts, donc on peut se permettre de passer à la phase de refactor en modifiant uniquement le code de la production.
.png)
Refactor terminé, tous les tests sont verts, on peut passer à la prochaine spécification.
Troisième spécification
Nous devons maintenant faire en sorte de retourner Buzz si l'input est divisible par 5.
On va aller un peu plus vite, mais le procédé est le même, on va d'abord faire un test avec un input 5 puis 10, puis refactor.
.png)
.png)
Dernière spécification
Nous devons maintenant faire en sorte de retourner Fizz-Buzz si l'input est divisible par 3 et par 5.
Comme pour les spécifications précédentes, on va faire un test avec un input 15 puis 30 et enfin refactor.
.png)
.png)
Et voilà !
Le mot de la fin
Stop aux amalgames ! Le TDD n'est pas un outil pour avoir une bonne couverture de code avec les tests, ce n'est pas simplement "faire des tests". Le TDD est un outil dont le but est de guider le développeur vers un objectif. Il permet de donner un feedback régulier afin de s'assurer qu'on est toujours sur la bonne voie. Il faut le voir comme un GPS, qui nous donne des directions à suivre (tourner à droite, aller tout droit pendant 2km, etc.) jusqu'à atteindre un objectif.
Les dédicaces
- Kent Beck - Wikipédia
- TDD Manifesto
- "Test-Driven Development by Example" de Kent Beck
- "Clean Code: A Handbook of Agile Software Craftsmanship" de Robert C. Martin
- Artisan Développeur - Benoit Gantaume
- Wealcome - Michaël Azerhad
- Craft Academy - Pierre Criulanscy




.webp)




