
Dans le domaine de la gestion des données, le choix entre Hard Delete et Soft Delete peut avoir un impact significatif sur la sécurité et la récupération des informations. Ces deux méthodes de suppression de données sont essentielles pour les développeurs et les administrateurs de bases de données.
Dans cet article, nous explorerons en détail ce qu'est le Hard Delete et le Soft Delete, leurs avantages respectifs, et comment choisir la meilleure approche en fonction des besoins spécifiques de votre projet. Nous fournirons également des exemples de code source pour illustrer leur mise en œuvre, afin que même les novices puissent comprendre ces concepts fondamentaux.
Comprendre la différence entre Hard Delete et Soft Delete
La gestion des données supprimées est une composante cruciale de toute application ou système de gestion de bases de données. Comprendre les distinctions entre le Hard Delete et le Soft Delete est le point de départ pour prendre des décisions éclairées.
Hard Delete : La Suppression Définitive (h3)
- Le Hard Delete, également connu sous le nom de suppression définitive, signifie que les données supprimées sont éliminées de manière permanente de la base de données.
- Cela signifie qu'une fois que vous avez effectué un Hard Delete, les données sont irrécupérables.
- Exemples de scénarios où le Hard Delete est approprié : suppression de données sensibles ou obsolètes, respect de la conformité légale.
Soft Delete : La suppression réversible
- Le Soft Delete, contrairement au Hard Delete, implique une suppression réversible.
- Les données supprimées sont marquées comme "supprimées" mais restent dans la base de données.
- Cela permet la récupération des données supprimées si nécessaire, offrant une couche de sécurité supplémentaire.
- Utilisation courante du Soft Delete : préservation de l'historique des données, récupération en cas d'erreur de suppression.
En comprenant la différence fondamentale entre le Hard Delete et le Soft Delete, vous pouvez commencer à évaluer quelle méthode convient le mieux à votre projet. La prochaine section examinera les avantages de chacune de ces méthodes pour vous aider à prendre une décision éclairée.
Les avantages du Hard Delete
Le Hard Delete est une méthode de suppression de données qui peut s'avérer essentielle dans certaines situations. Examinons de plus près les avantages qu'il offre :
L'un des principaux avantages du Hard Delete réside dans la sécurité qu'il offre. Lorsque vous effectuez un Hard Delete, les données sont supprimées de manière permanente de la base de données.
Cela garantit qu'aucune trace des données supprimées ne subsiste, réduisant ainsi le risque de divulgation d'informations sensibles.
Dans certains secteurs, comme la santé ou les finances, la conformité légale est cruciale. Le Hard Delete permet de répondre à ces exigences en supprimant irrévocablement les données.
En supprimant définitivement les données, le Hard Delete peut contribuer à améliorer les performances de la base de données en libérant de l'espace et en réduisant la charge de travail du système.
Le Hard Delete simplifie la gestion des données, car il n'est pas nécessaire de gérer un ensemble de données supprimées de manière réversible. Cela peut simplifier les processus de sauvegarde et de restauration.
Pour mieux comprendre la mise en œuvre du Hard Delete, voici un exemple de code SQL montrant comment effectuer une suppression permanente dans une base de données :
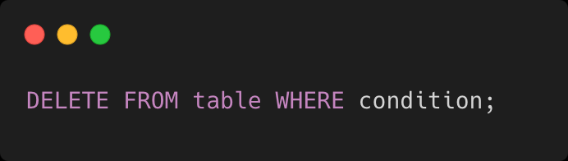
Les avantages du Soft Delete
Le Soft Delete, bien que différent du Hard Delete, présente des avantages significatifs dans certaines situations. Examinons en détail les avantages qu'il offre !
L'un des principaux avantages du Soft Delete est la capacité à récupérer des données supprimées par erreur. Les données marquées comme "supprimées" restent dans la base de données et peuvent être restaurées si nécessaire.
Le Soft Delete permet de conserver un historique complet des données, y compris celles qui ont été supprimées. Cela peut être utile pour l'audit, la conformité ou l'analyse des tendances historiques.
En évitant la suppression permanente des données, le Soft Delete offre une couche de protection contre les erreurs humaines, telles que la suppression accidentelle de données critiques.
Lors de la mise en œuvre de nouvelles fonctionnalités ou de modifications de la structure de la base de données, le Soft Delete permet une transition en douceur en conservant les données existantes.
Pour mieux comprendre la mise en œuvre du Soft Delete, voici un exemple de code SQL montrant comment marquer une ligne de données comme "supprimée" sans la supprimer définitivement :
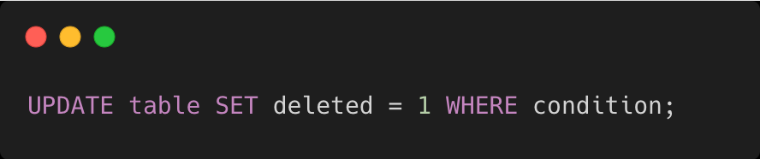
Quand utiliser chacune des méthodes
La décision entre Hard Delete et Soft Delete dépend largement des exigences particulières de votre projet. Voici des conseils pour vous aider à faire le choix approprié :
Choisissez le Hard Delete lorsque la sécurité des données est une priorité absolue. Par exemple, dans les applications de santé ou financières, il est préférable d'opter pour une suppression définitive.
Si la récupération des données supprimées est essentielle, le Soft Delete est la meilleure option. Cela s'applique notamment aux systèmes où les erreurs de suppression peuvent se produire.
Pour respecter les réglementations strictes qui exigent la suppression permanente de données, le choix du Hard Delete est nécessaire.
Si vous avez besoin de conserver un historique complet des données, optez pour le Soft Delete. Cela est particulièrement utile pour l'audit et la conformité.
Si vous souhaitez optimiser la performance de la base de données en réduisant la charge, le Hard Delete peut être plus approprié, car il libère de l'espace.
Envisagez le Soft Delete lorsque vous prévoyez d'introduire de nouvelles fonctionnalités ou des changements structurels dans la base de données, car il permet une transition en douceur.
En évaluant soigneusement les besoins de votre projet en fonction de ces critères, vous pourrez prendre une décision éclairée quant à l'utilisation du Hard Delete ou du Soft Delete. Gardez à l'esprit que dans certains cas, une combinaison des deux méthodes peut également être envisagée pour répondre aux besoins spécifiques de votre application.
Le choix entre Hard Delete et Soft Delete est une décision cruciale dans la gestion des données. Chacune de ces méthodes présente des avantages distincts, et le choix dépend des besoins spécifiques de votre projet.
Le Hard Delete offre une sécurité maximale en supprimant définitivement les données, ce qui le rend idéal pour les applications où la confidentialité et la conformité légale sont essentielles. Cependant, il faut être prudent, car les données sont irrécupérables.
Le Soft Delete, quant à lui, permet la récupération des données supprimées, préservant ainsi un historique complet et offrant une protection contre les erreurs humaines. Il est particulièrement adapté aux systèmes où la récupération des données est une priorité.
Le choix entre ces deux méthodes peut également dépendre des contraintes de performance de votre base de données et de la flexibilité nécessaire pour les futures modifications.
En fin de compte, il n'y a pas de réponse universelle. Il est essentiel d'évaluer les besoins de votre projet et de choisir la méthode qui répond le mieux à ces exigences spécifiques. Dans certains cas, une combinaison des deux méthodes peut également être envisagée pour une gestion des données supprimées plus complète.
Quelle que soit la méthode choisie, la gestion des données supprimées est une composante essentielle de tout système de base de données bien conçu. En comprenant les avantages du Hard Delete et du Soft Delete, vous êtes mieux préparé à prendre des décisions éclairées pour garantir la sécurité et la flexibilité de votre application.
N'hésitez pas à partager vos propres expériences et réflexions sur ce sujet dans les commentaires ci-dessous. La gestion des données supprimées est une discipline en constante évolution, et l'échange d'idées peut bénéficier à l'ensemble de la communauté de développement.












.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

