
Introduction
Aujourd'hui, comment parler de développement logiciel sans parler de Git ? Un bon système de gestion des versions est essentiel pour assurer un flux de travail efficace. Git est l'outil de gestion de versions par excellence et est le plus populaire. Néanmoins, avec Git, il s'est développé différentes stratégies pour structurer et gérer le flux de modifications de la codebase. Parmi toutes ces stratégies, aujourd'hui, deux vont nous intéresser : le Trunk-Based Development (TBD) et Git Flow.
D'un côté on a le TBD, une approche minimaliste qui préconise de travailler directement sur un tronc commun, autrement dit la branche principale. Tandis que Git Flow, lui, propose une structure plus complexe, avec des branches dédiées à des fonctionnalités, des corrections, des versions, etc.
Les deux approches ont des avantages et des inconvénients, leurs propres complexités et simplicités et c'est ce que nous allons voir maintenant.
L'objectif de cet article n'est pas simplement de fournir une explication de ces deux stratégies de gestion des versions, mais plutôt de démontrer pourquoi, dans de nombreux contextes, le TBD peut s'avérer une approche plus optimale que Git Flow.

Git Flow vs Trunk-Based Development
La stratégie Git Flow
Git Flow est une stratégie de gestion de versions populaire qui a été conçue pour aider les équipes à gérer les développements complexes, en tirant parti de la puissance et de la flexibilité des branches Git. Elle propose une structure organisée qui facilite le développement parallèle de différentes fonctionnalités et la gestion des versions.
Organisation
Avec Git Flow on organise nos branches de la manière suivante :
- main, la branche principale qui représente l'état actuel de la production
- develop, la branche où se trouve toutes les fonctionnalités, corrections et autres de la prochaine version prévue
- feature/xxx, les branches créées à partir de develop où se trouve le code d'une fonctionnalité qui sera fusionné avec develop une fois le développement terminé
- release/xxx, les branches créées à partir de develop où se trouve le code d'une nouvelle version du logiciel, potentiellement affiné avant le déploiement
- hotfix/xxx, les branches créées à partir de main pour des corrections critiques découvertes en production. Ces branches sont fusionnées dans main dès que le correctif est prêt et sont également fusionnées avec develop pour s'assurer que la correction perdurera dans la codebase

Les problèmes de Git Flow
La force de Git Flow réside dans sa structure qui permet de gérer facilement des tâches parallèles et suivre d'évolution du code à travers le temps.
Cette stratégie entraîne néanmoins un lot d'inconvénients :
- Complexité - Cette stratégie nécessite beaucoup de manipulation manuelle des branches qui demande une maîtrise totale de Git et de ce processus
- Intégration continue compliquée - L'intégration continue est plus complexe à mettre en place en raison du développement parallèle sur plusieurs branches
- Déploiement fréquent coûteux - Le déploiement continus/fréquents n'est pas impossible mais demande beaucoup plus de temps et d'énergie
- Problèmes de fusion - Le nombre parallèle de branches important entraîne de nombreux problèmes potentiels de merge
- Revues de code difficiles - La taille des pull requests a tendance à être plus importante avec Git Flow parce qu'elles contiennent des fonctionnalités complètes. La branche de feature a tendance à vivre trop longtemps, nécessitant des fusions fréquentes avec develop ce qui entraîne des retards dans le processus de livraison

La stratégie Trunk-Based Development
La stratégie Trunk-Based Development est une approche bien plus minimaliste dont le but est de simplifier le flux de travail en minimisant la fragmentation du code et en facilitant l'intégration continue. Pour cela on ne va travailler que sur une seule branche principale (main ou trunk) autrement appelé : le tronc commun.
Une seule source de vérité
Avec le TBD, cela signifie donc que toutes les modifications du code sont introduites et fusionnées directement dans la branche principale. Chaque développeur doit donc fusionner régulièrement ses modifications, plusieurs fois par jour. En conséquence, les versions sont gérées directement à partir de la branche principale, chaque développeur est constamment à jour et les problèmes de fusions sont considérablement réduits. Le cycle de développement est plus rapide et alimente l'intégration et le déploiements continus.
Quid des branches ?
Travailler avec l'approche TBD ne signifie pas qu'on a plus du tout de branche en plus de la branche principale. En effet, les branches peuvent encore être utilisées mais elles se doivent d'être de très courte durée et fusionnées dès que le travail est terminé.

Quid des revues de code ?
Quel que soit la stratégie adoptée, le processus de revue de code persiste et demeure une composante essentielle pour assurer la qualité du code qui est fusionné dans le tronc commun. La subtilité entre les deux stratégie est que avec le TBD, les modifications étant fréquemment fusionnées, elles sont généralement plus petites. Et si les modifications s'avèrent importante alors le TBD souhaite mettre en avant la collaboration et demanderait de faire ces modifications en pair ou en mob programming. Enfin, les revues de code se doivent d'être traitées rapidement (dans la demi-journée) et doivent durer que quelques minutes (15 maximum à peu près).
Quid des modifications importantes ?
Le TBD n'empêche pas le développement de fonctionnalités importantes qui demandent donc de lourdes modifications du code. En revanche, cette stratégie va favoriser la collaboration via du pair ou du mob programming mais ce n'est pas la seule solution. Il existe également les Feature Flags.
Un Feature Flag est une technique de développement logiciel permettant de masquer, activer ou désactiver une fonctionnalité dans un environnement de production sans avoir à redéployer le code. Cette technique offre un contrôle en temps réel des fonctionnalités, représente une sécurité contre les problèmes potentiels de nouvelles fonctionnalités et, surtout, permet de travailler sur de nouvelles fonctionnalités directement dans la branche principale sans interrompre le fonctionnement normal de l'application.
Dans le cadre de l'approche TBD, où toutes les modifications sont effectuées directement sur la branche principale, l'utilisation de Feature Flags de fusionner le code pour de nouvelles fonctionnalités qui ne sont pas encore terminées ou testées. La fonctionnalité peut être développée et fusionnée dans le tronc sans être exposée aux utilisateurs jusqu'à ce qu'elle soit prête, où le Feature Flag à ce moment-là, peut être activé.
Le recours à des Feature Flags apporte une flexibilité considérable au processus de développement et constitue une composante essentielle pour atteindre un déploiement continu et un flux de travail efficace dans le TBD.
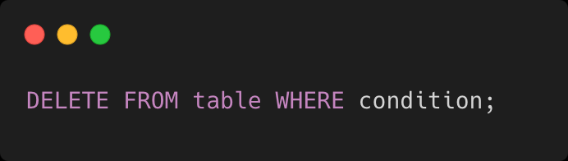
Mais à quoi ça ressemble concrètement ?
Ce sont ni-plus ni-moins des booléens :
.png)
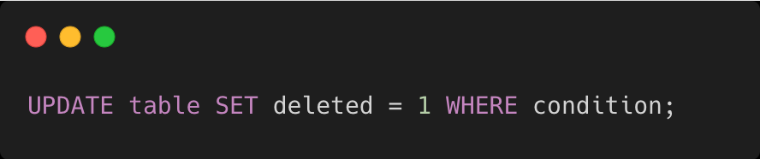
Et à l'usage, par exemple pour du React mais le principe est le même pour n'importe quel environnement :
.png)
Il est tout à fait possible de mettre en place un système de Feature Flags contrôlable à distance via un backoffice ou des outils tout prêt à l'usage qui existe sur le marché comme Firebase Remote Config, PostHog ou Harness par exemple.
Pré-requis
Pour une implémentation efficace du TBD, plusieurs éléments sont généralement requis :
- Intégration Continue (CI) : c'est une stratégie qui bénéficie grandement de l'utilisation de la CI étant donné quelle est souvent sollicité pour de petites modifications. La CI permet d'assurer que le tronc commun est toujours en état de fonctionner correctement et qu'elle continue à être deployable à tout moment.
- Tests automatisés : les tests automatisés vont de pair avec la CI, ils assurent, si ils sont correctement mis en place, de la qualité du code.
- Revues de code : comme mentionné précédemment, les revues de code sont une composante essentielle pour maintenir la qualité et le partage de connaissance.
- Feature flag : comme expliqué précédemment, il est important de savoir mettre en place les features flag parce qu'ils sont souvent utilisés.
- Culture de la collaboration : enfin, l'environnement de travail est très important, toute l'équipe doit être impliqué, connaître et appliquer ce processus. L'équipe doit également se responsabiliser et doit être prête à collaborer étroitement et à partager ses connaissances.
Résumons les bénéfices
Maintenant que nous avons expliqué le TBD comment il fonctionne et dans quel contexte, nous pouvons en ressortir les bénéfices suivants :
- Intégration continue (CI) : grâce à l'intégration fréquente de petits changements, les problèmes sont détectés et résolus plus rapidement. De plus, cela limite les éventuels conflits de fusion.
- Déploiements plus rapides : avec une seule branche principale toujours prête à être déployée, le TBD peut faciliter des déploiements plus rapides et plus réguliers.
- Simplification du processus : la stratégie TBD supprime la nécessité de gérer de nombreuses branches à long terme, simplifiant le flux de travail de l'équipe.
- Qualité du code : les revues de code régulières contribuent à maintenir la qualité du code et à anticiper les problèmes.
- Flexibilité grâce aux Feature Flags : l'utilisation de Feature Flags permet de tester de nouvelles fonctionnalités en production sans les exposer aux utilisateurs finaux, contribuant à un lancement plus sûr et contrôlé des nouveautés.
Un dernier bénéfice que nous allons voir en détail dans le dernier point de cet article, c'est la facilité avec laquelle le TBD favorise l'atteinte de performances élevées selon les métriques DORA, un ensemble de mesures reconnues pour évaluer l'efficacité des équipes.

Et les inconvénients dans tout ça ?
La mise en œuvre de la stratégie TBD présente également certains défis ou inconvénients :
- Gestion rigoureuses des fusions : les modifications doivent être fusionnées en continu dans le tronc commun, ce qui nécessite que les développeurs synchronisent fréquemment leur travail avec la branche principale pour éviter les conflits de fusion.
- Culture : pour certaines équipes, l'adoption de cette stratégie peut nécessiter un changement significatif dans leurs pratiques de travail, notamment l'intégration continue et les revues de code constantes.
- Déploiements risqués sans tests adéquats : sans une couverture de test adéquate, le risque d'introduction de bugs en production peut être plus élevé, car tout le code est fusionné directement dans la branche principale qui est déployée.
- Complexité des Feature Flags : bien que les Feature Flags offrent plus de flexibilité, leur gestion peut ajouter une certaine complexité. Une mauvaise utilisation des feature flags peut entraîner de la dette technique.
En dépit de ces défis/inconvénients, il est globalement reconnu que les avantages valent les efforts nécessaires pour mettre en œuvre le TBD. Comme pour beaucoup de choses de la vie, il est important de déterminer si cette stratégie est adaptée au contexte spécifique de votre équipe et de votre projet.
DORA Metrics et Trunk-Based Development
Les DORA Metrics (ou DevOps Research and Assessment metrics), sont une série de mesures de performance pour les équipes de développement logiciel.
Ces mesures incluent :
- Le temps de cycle de déploiement (Mean Lead Time for Changes - MLTC) : Le temps moyen nécessaire pour qu'un commit passe à la production.
- La fréquence de déploiement (Deployment Frequency - DF) : À quelle fréquence une organisation déploie du code en production.
- Le temps de rétablissement (Mean Time to Restore - MTTR) : Le temps nécessaire pour récupérer d'une panne ou d'un incident de production.
- Le taux d'échec des modifications (Change Failure Rate - CFR) : La proportion de déploiements causant un incident de production ou un échec de service.
Le TBD est lié aux DORA Metrics car c'est une méthode de développement qui peut potentiellement améliorer ces mesures. Il encourage des cycles d'intégration et de déploiement plus courts, ce qui peut accélérer le délai de déploiement et augmenter la fréquence de déploiement.
- MLTC et DF : La fusion fréquente de petites modifications permet de réduire le temps de cycle de déploiement et d'augmenter la fréquence de déploiement, car la branche principale est toujours dans un état deployable.
- CFR : Avec des revues de code régulières et des tests automatisés, on peut s'attendre à ce que le pourcentage de modifications ratées diminue, car les problèmes sont souvent découverts et corrigés avant le déploiement.
- MTTR : Comme les problèmes sont généralement plus petits et plus localisés avec cette approche, il est généralement possible de corriger et de restaurer le service plus rapidement.
En résumé, l’approche Trunk-Based Development est bien alignée avec l’amélioration des métriques DORA, ce qui en fait une stratégie de choix pour les équipes axées sur le DevOps.
Ainsi, le développement basé sur la stratégie TBD peut contribuer à l'amélioration des DORA metrics.
Le mot de la fin
Cet article a examiné en profondeur la stratégie de Trunk-Based Development (TBD) en la comparant à Git Flow et en mettant en avant ses nombreux avantages. Nous avons analysé comment le TBD favorise des cycles de développement plus rapides, une meilleure qualité de code grâce aux revues de code constantes, et une plus grande flexibilité par l'utilisation de feature flags. Nous avons également expliqué comment le TBD facilite l'atteinte de performances élevées selon les DORA Metrics.
Cependant, nous avons également souligné que le TBD n'est pas sans défis. Il nécessite une gestion rigoureuse des fusions, un changement culturel significatif dans certaines équipes, une bonne couverture de tests pour minimiser les risques associés au déploiement constant.
Pour conclure, le TBD est un modèle puissant qui peut accélérer la livraison de valeur, améliorer la qualité du code et favoriser l'optimisation continue des performances de l'équipe. Cependant, comme pour toute stratégie, son adoption doit être précédée d’une évaluation approfondie des besoins, contextes et capacités spécifiques de l’équipe.





.png)
.png)

