Dans l'univers du développement d'applications mobiles, la gestion des versions de Node.js est cruciale. Découvrez ici comment utiliser Node Version Manager (NVM) pour changer, installer des versions LTS, et éviter les conflits. Que vous soyez débutant ou expert, ce guide vous aidera à maîtriser cet outil essentiel.
Comprendre l'importance de Node Version Manager (NVM)
L'utilisation de différentes versions de Node.js peut être délicate. NVM simplifie ce processus en vous permettant de basculer facilement entre les versions. Vous évitez ainsi les conflits et assurez la compatibilité de vos projets.
NVM offre une flexibilité totale pour installer et gérer des versions spécifiques de Node.js en fonction de vos besoins. Son utilisation est simple, même pour les débutants, avec des commandes intuitives. NVM vous protège contre les conflits de versions en isolant les environnements.
NVM garantit que vos projets restent compatibles avec la version de Node.js sur laquelle ils ont été développés. Vous pouvez également mettre à jour vos projets en douceur sans crainte de problèmes de compatibilité.
En automatisant la gestion des versions de Node.js, NVM vous permet de vous concentrer sur le développement plutôt que sur la résolution de problèmes de version. C'est un gain de temps précieux.
En comprenant ces points, vous serez mieux préparé à tirer parti de Node Version Manager (NVM) dans votre travail de développement Node.js.
Installation de Node Version Manager
L'installation de Node Version Manager (NVM) est la première étape essentielle pour gérer vos versions Node.js. Cette section vous guidera à travers le processus d'installation sur différentes plateformes :
- Linux : Utilisez la commande wget pour récupérer NVM depuis GitHub. Suivez notre guide étape par étape pour une installation sans faille.
- macOS : Apprenez comment installer NVM sur macOS en utilisant la commande curl. Suivez nos instructions pour garantir une installation réussie.
- Windows : Si vous êtes sur Windows, découvrez comment installer NVM en utilisant des outils tels que Git Bash ou Windows Subsystem for Linux (WSL).
Après l'installation, nous vous montrerons comment configurer NVM pour une utilisation optimale. Vous serez prêt à commencer à gérer vos versions Node.js avec aisance.
Familiarisez-vous avec les commandes de base de NVM, telles que nvm --version pour vérifier la version installée, nvm ls pour afficher les versions disponibles et nvm install pour installer une version spécifique.
Suivez les instructions détaillées dans cette section pour installer NVM sur votre plateforme de choix. Vous serez rapidement opérationnel pour gérer vos versions Node.js de manière fluide.
Utilisation de NVM pour installer la dernière version LTS de Node.js
Maintenant que vous avez installé Node Version Manager (NVM), apprenons comment utiliser cet outil pour installer la dernière version LTS (Long Term Support) de Node.js.
Avant de procéder à l'installation, il est essentiel de savoir quelles versions LTS de Node.js sont disponibles. Vous pouvez le faire en utilisant la commande nvm ls-remote --lts.
Suivez ces étapes simples pour installer la dernière version LTS :
- Exécutez nvm install --lts pour installer la dernière version LTS disponible.
- Pour vérifier que l'installation a réussi, utilisez node --version pour afficher la version de Node.js installée.
Si vous souhaitez que la dernière version LTS soit la version par défaut utilisée par NVM, exécutez nvm alias default <version>.
Grâce à ces étapes simples, vous pouvez désormais installer et utiliser la dernière version LTS de Node.js avec facilité en utilisant Node Version Manager (NVM). Cela vous permettra de bénéficier des avantages de stabilité et de support à long terme pour vos projets Node.js.
Gestion de multiples versions de Node.js avec NVM
La gestion de plusieurs versions de Node.js est une nécessité pour de nombreux développeurs. Voici comment utiliser Node Version Manager (NVM) pour gérer efficacement ces versions.
Pour voir toutes les versions de Node.js installées sur votre système, utilisez simplement la commande nvm ls. Vous obtiendrez une liste claire de toutes les versions disponibles.
Pour basculer entre les versions, utilisez la commande nvm use <version>. Cela changera votre environnement de développement pour utiliser la version spécifiée.
Vous pouvez également créer des alias pour des versions spécifiques avec nvm alias <alias> <version>. Cela simplifie encore la gestion des versions.
Avec ces commandes simples, vous pouvez gérer facilement plusieurs versions de Node.js sur votre système, en utilisant Node Version Manager (NVM). Cela vous permet de maintenir la compatibilité de vos projets et de travailler sur des versions spécifiques selon vos besoins.
Mettre à jour Node.js avec NVM
Maintenir votre installation Node.js à jour est crucial pour bénéficier des dernières fonctionnalités et correctifs de sécurité. Voici comment effectuer des mises à jour en utilisant Node Version Manager (NVM).
Pour vérifier si des mises à jour sont disponibles, exécutez nvm ls-remote <version>. Cela affichera les versions de Node.js disponibles à la mise à jour.
Pour mettre à jour Node.js vers la dernière version LTS disponible, utilisez nvm install --lts. Cela installera la dernière version LTS sans affecter vos versions précédentes.
Si vous avez une version spécifique que vous souhaitez mettre à jour, utilisez nvm install <version> pour obtenir la dernière version de cette branche.
En utilisant ces commandes simples, vous pouvez maintenir votre installation Node.js à jour avec facilité, en garantissant que vos projets sont toujours optimisés en termes de performances et de sécurité.
Exemples pratiques et code source
Dans cette section, nous explorerons quelques exemples pratiques d'utilisation de Node Version Manager (NVM) avec des extraits de code source pour une meilleure compréhension.
Exemple 1 : Installation de Node.js LTS

Cette commande installe la dernière version LTS de Node.js.
Exemple 2 : Basculer vers une version spécifique
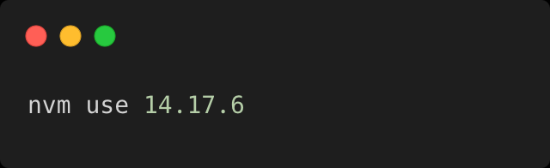
Utilisez cette commande pour basculer vers une version spécifique de Node.js (dans cet exemple, la version 14.17.6).
Exemple 3 : Créer un alias pour une version
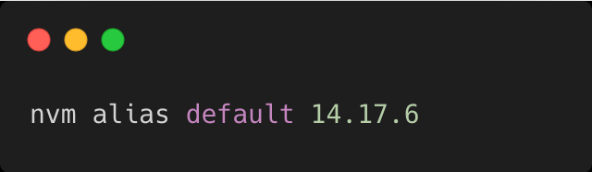
Créez un alias pour définir une version spécifique de Node.js comme version par défaut.
Exemple 4 : Vérifier les versions installées

Cette commande affiche la liste des versions de Node.js installées sur votre système.
Exemple 5 : Mise à jour de Node.js
Mettez à jour Node.js vers la dernière version (ici, la version actuelle) tout en conservant les packages de la version précédente.
Utilisez ces exemples pratiques et extraits de code source pour mieux comprendre comment utiliser NVM dans vos projets Node.js. Cela vous aidera à gérer efficacement les versions et à optimiser votre environnement de développement web.
Les meilleures pratiques de gestion des versions Node.js
Pour tirer le meilleur parti de Node Version Manager (NVM) et maintenir un environnement de développement Node.js efficace, suivez ces meilleures pratiques :
- Gardez NVM à jour : Pensez à mettre à jour régulièrement NVM pour bénéficier des dernières améliorations et corrections de bogues.
- Utilisez les versions LTS : Privilégiez les versions LTS (Long Term Support) pour une stabilité à long terme. Cela garantit que vos projets restent stables et sécurisés.
- Créez des alias significatifs : Lors de la création d'alias pour des versions spécifiques, choisissez des noms significatifs pour vous faciliter la gestion.
- Documentez vos projets : Tenez un journal des versions utilisées pour chaque projet afin de garantir une compatibilité continue.
- Gérez les dépendances avec npm : N'utilisez pas NVM pour gérer les dépendances de vos projets. Utilisez npm pour gérer les packages Node.js spécifiques à chaque projet.
- Restez informé : Suivez les annonces de nouvelles versions Node.js et les mises à jour de sécurité pour rester au courant des dernières avancées.
En suivant ces meilleures pratiques, vous optimiserez votre gestion des versions Node.js avec NVM et garantirez la stabilité, la sécurité et la facilité de gestion de vos projets.
Dans cet article, nous avons exploré en détail l'utilisation de Node Version Manager (NVM) pour la gestion des versions Node.js. Que vous soyez un développeur expérimenté ou que vous découvriez Node.js, NVM est un outil essentiel pour maintenir un environnement de développement propre et efficace.
Nous avons abordé les étapes clés, de l'installation de NVM sur différentes plateformes à la gestion de multiples versions de Node.js, en passant par les mises à jour et les meilleures pratiques. En utilisant NVM, vous pouvez facilement basculer entre les versions, maintenir la compatibilité de vos projets et garantir la sécurité de votre environnement de développement.
Les exemples pratiques et les extraits de code source ont été fournis pour vous aider à mieux comprendre comment utiliser NVM dans vos projets. En suivant les meilleures pratiques recommandées, vous pouvez maintenir un environnement de développement Node.js optimal.
En fin de compte, Node Version Manager (NVM) est un outil puissant qui facilite grandement la gestion des versions Node.js. Il vous permet de rester à jour avec les dernières versions, d'adapter vos projets aux besoins spécifiques et de maintenir un flux de travail de développement efficace. Intégrez NVM dans votre boîte à outils de développement Node.js dès aujourd'hui pour une expérience de développement plus fluide et plus productive.
Maintenant que vous savez correctement utiliser NVM, nous vous invitons à consulter notre guide complet sur l’outil de gestion de versions Git.