

Si vous développez une application SaaS, un réseau social, une marketplace ou encore une application métier, il est fort probable que vous aillez besoin d’envoyer des e-mails ou des SMS transactionnels à vos utilisateurs.
Si vous vous demandez ce qu’est un message transactionnel, c’est un message automatisé qui fournit aux utilisateurs des informations utiles qui visent à l’aider et améliorer son expérience. Parmi les exemples les plus courants, on retrouve les confirmations de commande, les rappels de rendez-vous et l'authentification à deux facteurs.
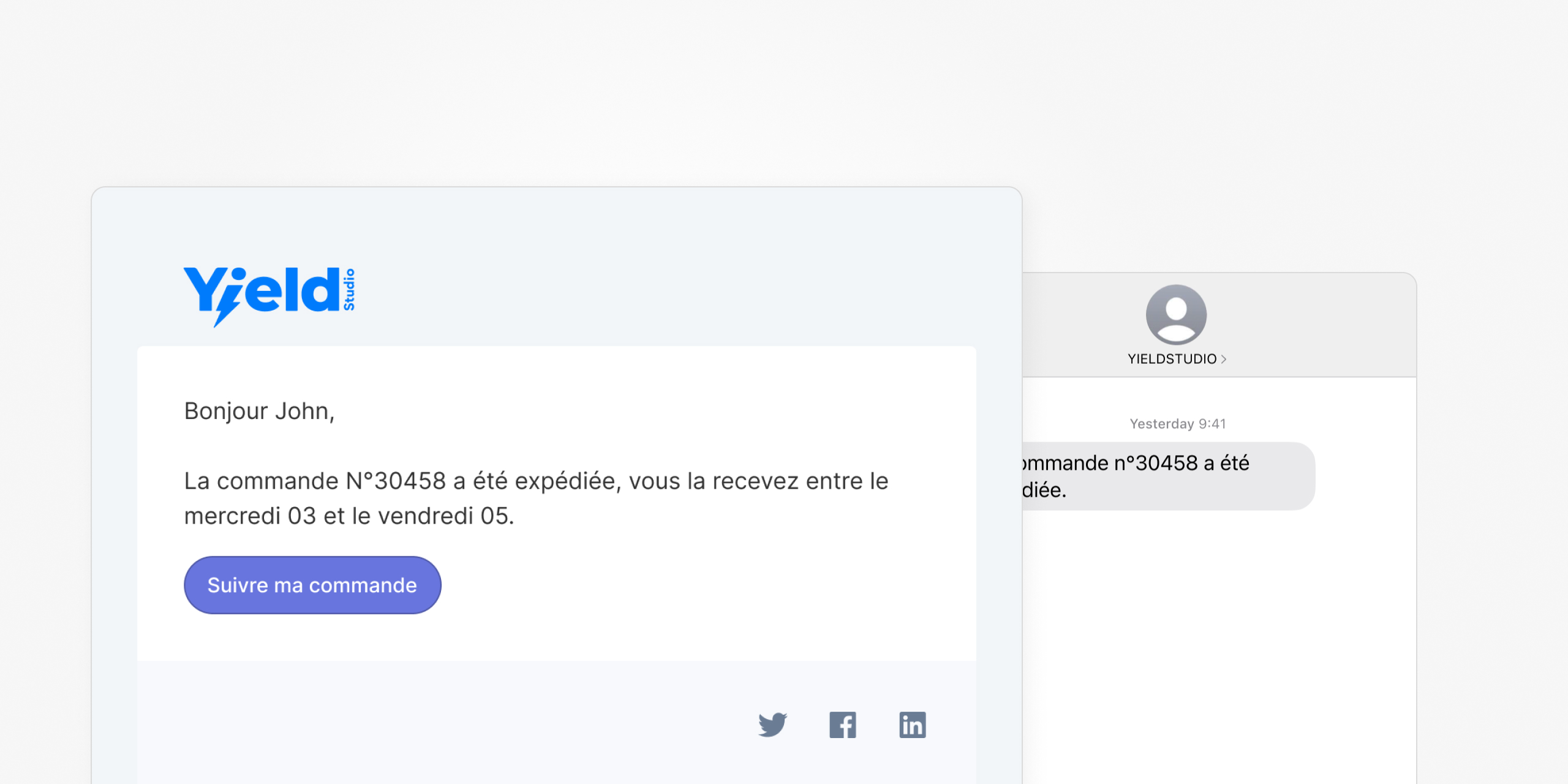
L’envoi d’e-mails et de SMS transactionnels avec Laravel est un jeu d’enfant, cette simplicité nous la devons au composant Notifications.
Laravel embarque le support de certains canaux : SMTP, Vonage et Slack. Les développeurs peuvent ensuite intégrer leurs propres canaux et les partager à la communauté sous forme de librairies.
C’est ce que nous avons fait chez Yield Studio en développant des packages pour Brevo, Mailjet et Expo !
Dans ce tutoriel, nous allons vous expliquer étape par étape comment envoyer des e-mails et des SMS transactionnels avec yieldstudio/laravel-brevo-notifier !
Étape 1 : Créer un compte Brevo
Pour commencer, vous devez vous créer un compte sur Brevo et vérifier votre adresse e-mail. Après ça vous pourrez vous rendre sur le tableau de bord.
Le plan Gratuit de Brevo vous permet d’envoyer jusqu’à 300 e-mails par jour, quant au SMS vous devrez charger votre compte avec des crédits SMS, à titre d’exemple le pack de 100 crédits SMS à destination de la France est facturé 4,5€.
Étape 2 : Installer Laravel Brevo Notifier
Après avoir créé votre compte Brevo, nous pouvons continuer l’installation.
composer require yieldstudio/laravel-brevo-notifier
Une fois l'installation terminée, nous pouvons éditer le fichier .env et ajouter les variables suivantes avec vos propres valeurs.
BREVO_KEY=your-brevo-key
BREVO_SMS_SENDER=Yield
# Laravel variables
MAIL_FROM_ADDRESS=hello@yieldstudio.fr
MAIL_FROM_NAME=Yield Studio
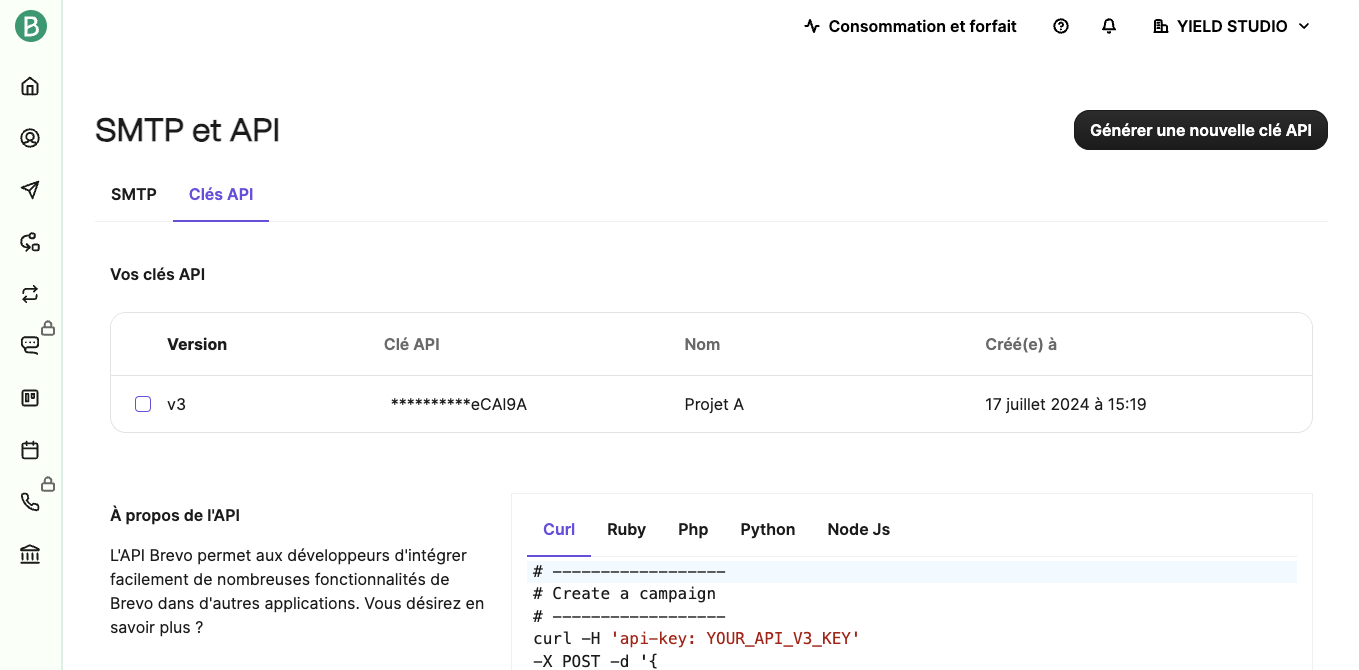
La valeur de BREVO_KEY peut être obtenue sur votre tableau de bord dans SMTP et API.
Quant à la valeur de BREVO_SMS_SENDER, elle est limitée à 11 caractères alphanumériques ou 15 caractères numériques. Il s’agit de l’expéditeur que verra votre utilisateur lors de l’envoi SMS (Yield, Amazon, IKEA)
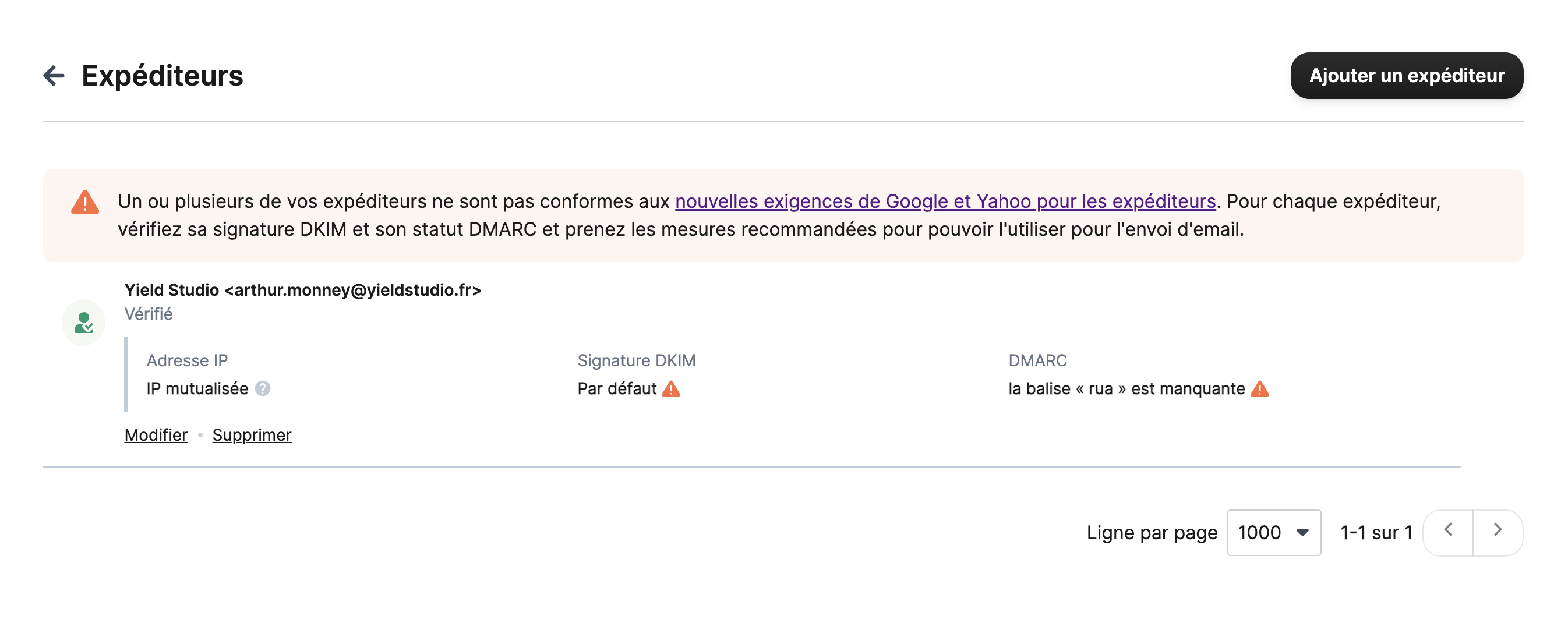
Étape 3 : Authentifier vos expéditeurs
Avec Brevo comme avec de nombreux fournisseurs, les adresses e-mail qui servent à envoyer des e-mails doivent être une adresse authentifiée. Vous pouvez authentifier une adresse e-mail en particulier ou bien directement un nom de domaine.
Vous devez vous rendre dans Expéditeurs, domaines et IP dédiées et ajouter les adresses e-mails ou les domaines qui vous serviront à envoyer des e-mails.
Étape 4 : Générer la Notification
Vous devez ensuite créer une classe pour votre notification, vous pouvez utiliser la commande Artisan ci-dessous, par exemple nous créons une notification OrderShipped
php artisan make:notification OrderShipped
Cette commande génère la classe dans le dossier App\Notifications. Si ce dossier n’existe pas encore, Laravel le créera pour nous.
Étape 5 : Envoyer un e-mail et un SMS
Assurez ensuite vous de changer le retour de la méthode via pour y ajouter notre BrevoSmsChannel et/ou BrevoEmailChannel
<?php
namespace App\Notifications;
use Illuminate\Notifications\Notification;
use YieldStudio\LaravelBrevoNotifier\BrevoSmsChannel;
use YieldStudio\LaravelBrevoNotifier\BrevoEmailChannel;
class OrderShipped extends Notification
{
public function via(): array
{
return [BrevoSmsChannel::class, BrevoEmailChannel::class];
}
}
Vous pouvez ensuite préparer votre notification en ajoutant la méthode toBrevoSms et/ou toBrevoEmail :
<?php
namespace App\Notifications;
use Illuminate\Notifications\Notification;
use YieldStudio\LaravelBrevoNotifier\BrevoSmsMessage;
use YieldStudio\LaravelBrevoNotifier\BrevoEmailMessage;
class OrderShipped extends Notification
{
public function __construct(private Order $order) {
}
// ...
public function toBrevoSms($notifiable): BrevoSmsMessage
{
return (new BrevoSmsMessage())
->to($notifiable->phone)
->content('La commande n°' . $this->order->number . ' a été expédiée.');
}
public function toBrevoEmail($notifiable): BrevoEmailMessage
{
return (new BrevoEmailMessage())
->templateId(1)
->to($notifiable->firstname, $notifiable->email)
->params(['order_number' => $this->order->number]);
}
}
Pour envoyer un e-mail transactionnel avec Brevo, vous devez créer des Templates.
Vous pouvez maintenant envoyer votre notification depuis votre controller, un listener ou l’endroit le plus approprié dans votre cas :
<?php
namespace App\Http\Controllers;
use App\Notifications\SendSMSMessageNotification;
use Illuminate\Http\Request;
use Illuminate\Support\Facades\Auth;
final class MarkOrderAsShipped extends Controller
{
public function __invoke(Request $request, Order $order)
{
// ...
$request->user->notify(new OrderShipped($order));
// ...
}
}
Et voilà vous avez envoyé votre première notification avec Brevo ⚡

Conclusion
Et voila, envoyer un e-mail ou un SMS transactionnel avec Brevo à partir d'une application Laravel c’est relativement simple. Créez d'abord un compte Brevo, installez la librairie yieldstudio/laravel-brevo-notifier, configurez et envoyez votre superbe notification.
Vous pouvez aller encore plus loin en ajoutant des destinataires en copie, des pièces jointes (une facture par exemple) et bien plus.
Sentez-vous libre de tester ce package et d’y contribuer sur Github.


