Il y a quelques années maintenant, le développement d'applications mobiles a connu une révolution. Chez Yield Studio, nous l'avons adoptée avec passion. Vous avez forcément déjà entendu parler des systèmes d’exploitation mobile Android et d'iOS ? Pour nous, concevoir une application pour l'un ou l'autre, revient à la même charge de travail.
En effet, grâce à la technologie React Native, nous sommes capables de développer simultanément pour ces deux géants du mobile. Plongez dans notre guide ultime du développement d’application Android.
Que vous soyez novice ou expert, découvrez comment transformer une simple idée en une application concrète. C'est parti !
📗 Comprendre les bases du développement Android
Android, ce n'est pas seulement un petit robot vert que vous voyez sur votre smartphone. En réalité, il s’agit d’un puissant système d'exploitation, utilisé par des milliards d’appareils mobiles à travers le monde. Avant de plonger dans la création d'une application, quelques notions clés s'imposent.
Premièrement, parlons "langage". Pour développer sur Android, on utilise principalement Kotlin, bien que d'autres langages de programmation comme le Java puissent également être adoptés. Kotlin est donc la pierre angulaire de bon nombre d'applications que vous utilisez quotidiennement si vous disposez d’un smartphone ou d’une tablette fonctionnant sous Android.
Voyons un exemple de code source Kotlin des plus basiques :

Dans cet exemple de code source Kotlin, nous utilisons un élément TextView pour afficher le texte « Bienvenue sur notre application Android ! ».
Ensuite, il y a l’environnement de développement, Android Studio. C'est le logiciel officiel, mis à disposition par Google, pour concevoir des applications mobiles Android. Doté d'une panoplie d'outils, il facilite la vie des développeurs, des plus novices aux plus chevronnés.
Voici une capture d’écran de l’environnement de développement Android Studio avec du code source Kotlin rédigé sur la droite de l’écran :

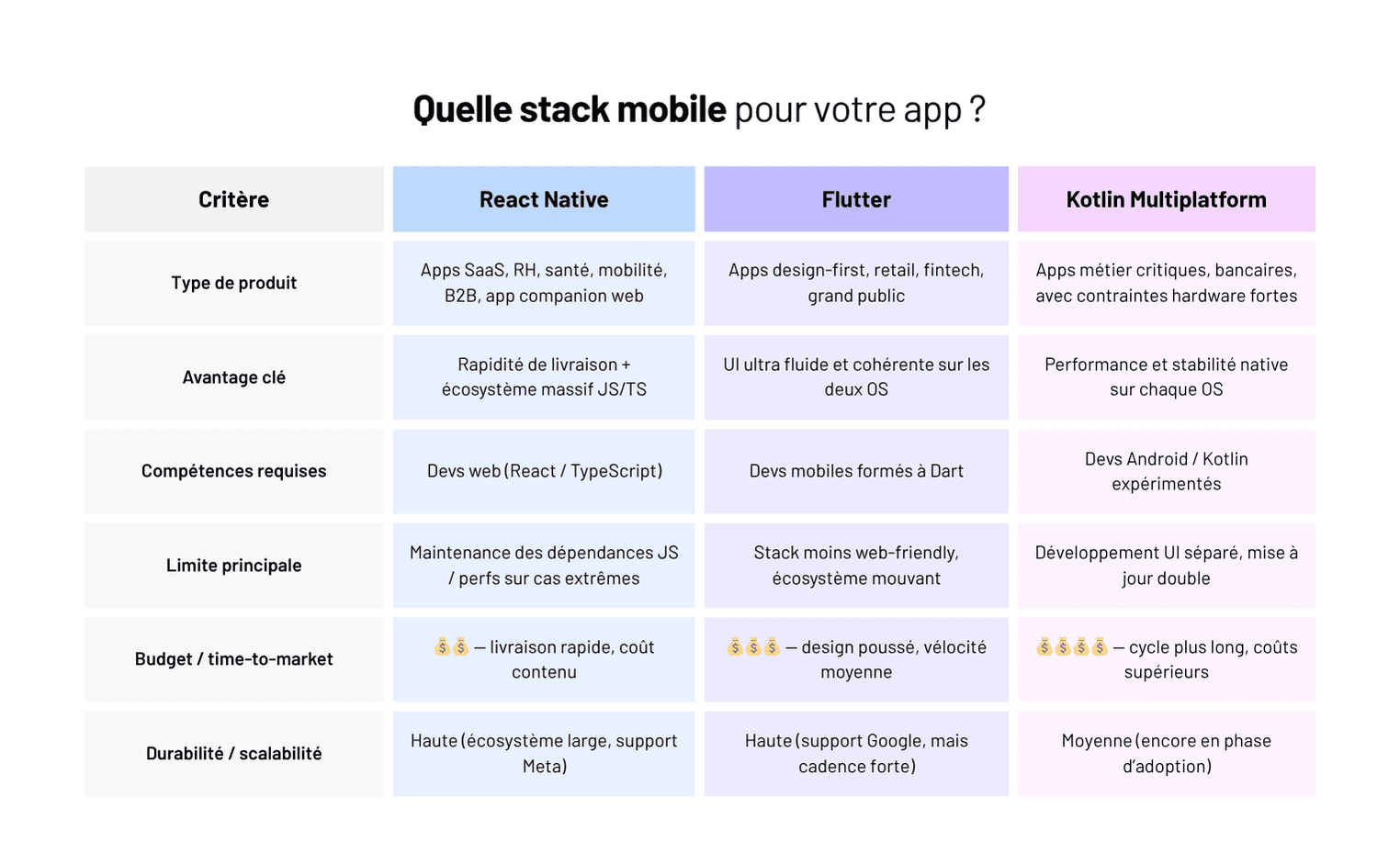
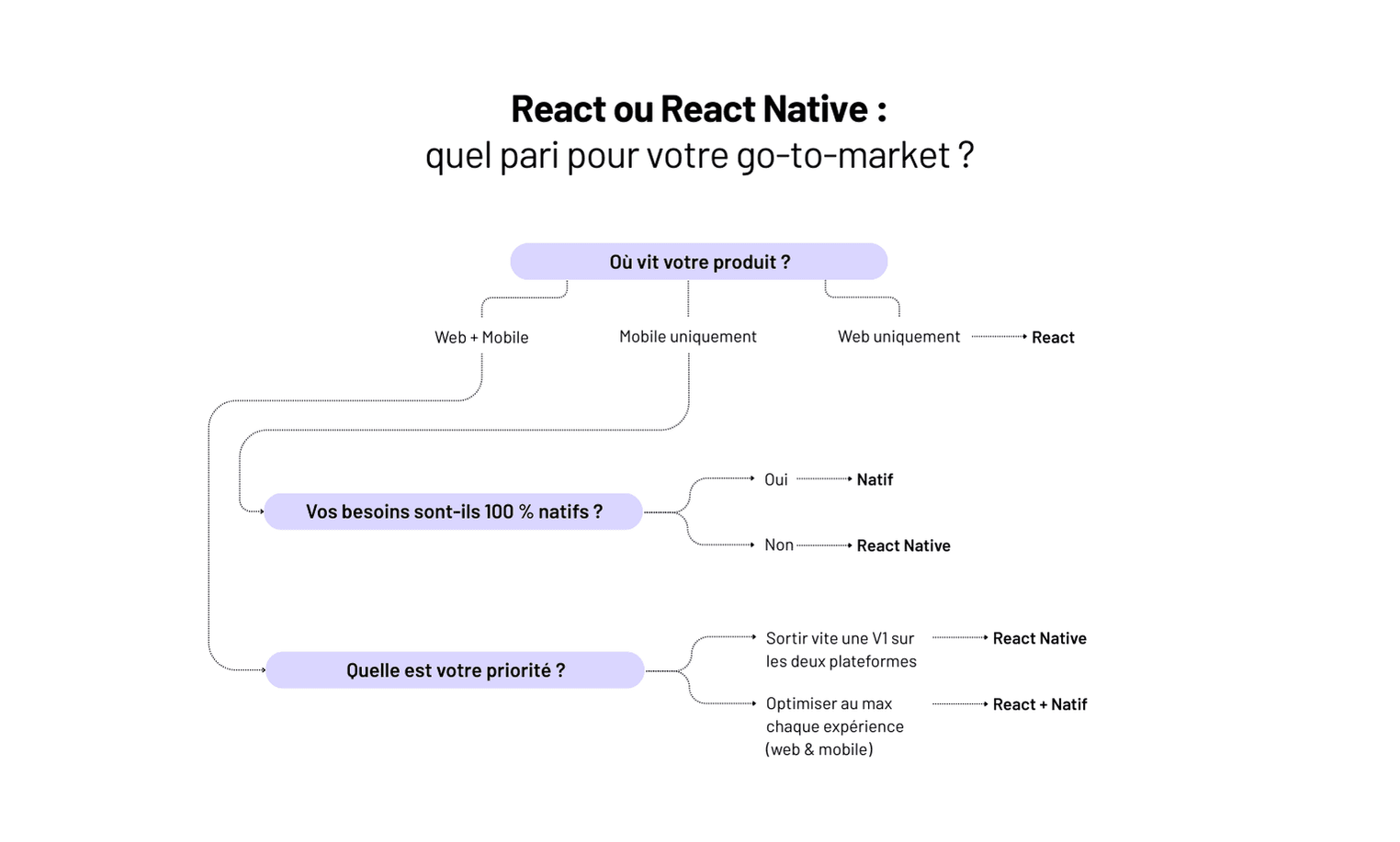
Mais chez Yield Studio, nous avons une large préférence pour React Native. Open source et ultra performant, il nous permet de concevoir des applications à la fois pour Android et iOS avec une seule et même base de code source JavaScript. Une véritable révolution qui simplifie le processus tout en garantissant une expérience utilisateur optimale.

Grossièrement, ce code source React Native emploie un composant Text au sein d'un élément View, avec un style appliqué pour le positionnement et la mise en forme du texte.
En résumé, le développement Android, c'est un mélange entre un langage de programmation, des outils adaptés et, dans notre cas, une touche de magie avec React Native.
Curieux d'en savoir plus ? Alors, continuons l'aventure ensemble !
👨💻 La technologie multiplateforme React Native
Lorsque l’on parle de développement d'applications mobiles, une question majeure revient souvent :
« Comment concevoir pour Android et iOS sans doubler le travail ? ».
Notre réponse : React Native !
Conçue par Méta (anciennement Facebook), React Native est une technologie open source qui a révolutionné la façon dont les développeurs conçoivent des applications mobiles. Avec ce Framework, nous n’avons plus besoin de créer deux applications distinctes pour les appareils fonctionnant sous Android et ceux utilisant iOS. Il suffit d’écrire un même code source JavaScript pour que React Native se charge de le transposer simultanément pour les deux systèmes d'exploitation.
Magique, n'est-ce pas ?
Chez Yield Studio, nous avons adopté cette technologie pour une raison simple : elle optimise notre efficacité ! Grâce à React Native, développer une application Android ou iOS représente exactement la même charge de travail pour nous. Quelques différences demeurent, bien sûr, mais elles sont mineures comparées à l'avantage principal : un gain de temps considérable.
Mais ce n'est pas tout ! React Native offre également des interfaces utilisateur fluides, adaptées à chaque plateforme. Les utilisateurs bénéficient ainsi d'une expérience homogène, que ce soit sur Android ou sur iOS.
En choisissant React Native, on fait le choix d'un développement plus rapide, plus cohérent et tout aussi performant. Chez Yield Studio, c'est cette technologie innovante qui nous guide au quotidien, nous permettant de délivrer des applications de haute qualité sur tous les fronts.
💡 Les étapes clés pour créer une application Android
Dès l'instant où l'on décide de se lancer dans le développement d'une application Android, un parcours structuré s'impose. Voici un guide étape par étape pour naviguer dans ce processus avec confiance :
- Définir le concept : Avant toute chose, clarifiez votre idée. Quelle est la valeur ajoutée de votre application ? À quel besoin répond-elle ?
- Conception de l'interface utilisateur : Une application réussie est intuitive. Travaillez sur un design ergonomique, adapté aux spécificités des appareils Android.
- Choisir le bon langage de programmation : Si nous privilégions React Native et donc JavaScript, chez Yield Studio, d'autres options existent. Kotlin et Java sont les langages utilisés pour développer de manière native sous Android.
- Utiliser Android Studio : Cet outil de développement, mis à jour régulièrement, est essentiel. Il intègre le SDK (pour Software Development Kit) Android offrant ainsi tout ce dont un développeur Android a besoin.
- Tests et améliorations : Une fois votre application développée, la phase de test est cruciale. Elle vous permet de détecter d'éventuels bugs et d'optimiser l'expérience utilisateur.
- Mise à jour constante : Le monde des applications évolue vite. Assurez-vous de mettre régulièrement à jour votre application pour répondre aux besoins changeants des utilisateurs et aux mises à jour du système d'exploitation.
- Lancement et promotion : Une fois que tout est en place, lancez votre application sur le Google Play Store. Ne négligez pas sa promotion pour garantir sa visibilité et son succès.
Créer une application Android est un voyage passionnant, parsemé de défis. Mais avec une méthodologie claire et les bons outils, comme ceux que nous utilisons chez Yield Studio, votre idée peut rapidement devenir une réalité prisée par des milliers d'utilisateurs.
📝 Publication et mise à jour
Entrer dans le monde des applications Android ne se termine pas simplement avec le développement de votre application. Deux étapes cruciales restent à franchir pour assurer sa pérennité : la publication et les mises à jour. Voici un aperçu de ce que cela implique :
- Avant de soumettre votre application Android sur le Google Play Store, vérifiez sa conformité aux directives de la plateforme. Veillez à préparer tous les éléments visuels et descriptifs nécessaires pour présenter votre application sous son meilleur jour.
- Une fois prête, soumettez l’application sur le store pour revue. Après validation, elle sera accessible à des millions d'utilisateurs. C'est le moment clé pour voir votre travail récompensé.
- Les avis des utilisateurs sont essentiels. Ils vous fourniront des informations précieuses pour améliorer votre application au fur et à mesure de son existence.
- En fonction des retours et avis des utilisateurs et des évolutions technologiques futures, planifiez des mises à jour régulières. Cela garantira la satisfaction des utilisateurs et la compatibilité avec les dernières versions d'Android.
- Le monde d'Android évolue sans cesse. Intégrez de nouvelles fonctionnalités et tendances pour que votre application reste au goût du jour.
- Comme tout produit, une application nécessite des réajustements. Analysez régulièrement les performances de votre application et effectuez les modifications qui s’imposent.
Chez Yield Studio, nous sommes conscients de l'importance de chaque étape. C'est pourquoi nous accompagnons nos clients bien au-delà du simple développement. La publication et la mise à jour sont des phases essentielles pour que votre application Android reste pertinente et appréciée de sa communauté.
Le développement d'applications Android a grandement évolué ces dernières années, poussé par des innovations et des technologies comme React Native ou Flutter. Si vous envisagez de développer une application Android, il est essentiel de comprendre les bases, mais aussi d'embrasser les nouvelles tendances qui façonnent l'avenir de la conception d’applications mobiles.
Chez Yield Studio, grâce à notre expertise en React Native, nous sommes prêts à transformer votre idée en une application fluide, performante et adaptée à la fois pour Android et iOS. En se tournant vers le futur tout en maîtrisant les fondamentaux du développement Android, nous vous assurons une présence mobile solide et durable.
🚀 Alors, prêt à créer la prochaine application révolutionnaire ? Nous sommes là pour vous accompagner.