

James
Chief Technical Officer & Co-founder
Développement web
Vers une ère de suprématie des applications web
Le marché des applications web voit des SaaS de gestion augmenter la productivité de 35%, tandis que les plateformes e-commerce enregistrent des hausses de conversion de 18%. Ces chiffres soulignent l'impact direct des solutions web personnalisées sur la performance commerciale. Avec l'intégration d'IA pour l'expérience utilisateur et de technologies cloud pour la scalabilité, les applications web ne se contentent plus de répondre aux besoins — elles anticipent et façonnent les demandes du marché.
Articles de James

Audit de sécurité applicatif : méthodologie et checklist OWASP
Méthodologie complète d'audit de sécurité applicatif : étapes clés, checklist OWASP Top 10 2025, outils SAST/DAST/SCA et bonnes pratiques pour sécuriser vos applications web et mobile.

Chatbot IA en entreprise : cas d'usage, coûts et ROI
Chatbot basique ou chatbot IA ? Découvrez les vrais cas d'usage en entreprise (support, RH, ventes, interne), les fourchettes de coûts réalistes et le ROI mesurable d'un chatbot intelligent.

Computer vision en entreprise : 5 cas d'usage concrets
Controle qualite, OCR, surveillance, retail analytics, inspection infrastructure : decouvrez 5 cas d'usage concrets de la computer vision en entreprise avec ROI et stack technique.

CTO as a Service : quand et pourquoi faire appel à un CTO externe
CTO as a Service, CTO externe, CTO temps partagé : découvrez quand et pourquoi y recourir, les missions concrètes, les coûts et le comparatif avec un CTO interne.

Data engineering : architectures modernes pour exploiter vos données
Data warehouse, data lake, lakehouse, data mesh : comprendre les architectures data modernes et savoir quand investir dans le data engineering pour votre entreprise.
Machine learning en production : du PoC au deploiement (guide MLOps)
80% des PoC ML ne passent jamais en production. Pipeline MLOps, model drift, feature stores, CI/CD pour modeles : le guide complet pour deployer du machine learning de maniere fiable.

RAG en entreprise : architecture, cas d'usage et limites
Le RAG (Retrieval Augmented Generation) permet d'exploiter vos données internes avec l'IA générative. Architecture technique, cas d'usage concrets et limites honnêtes pour décider en connaissance de cause.
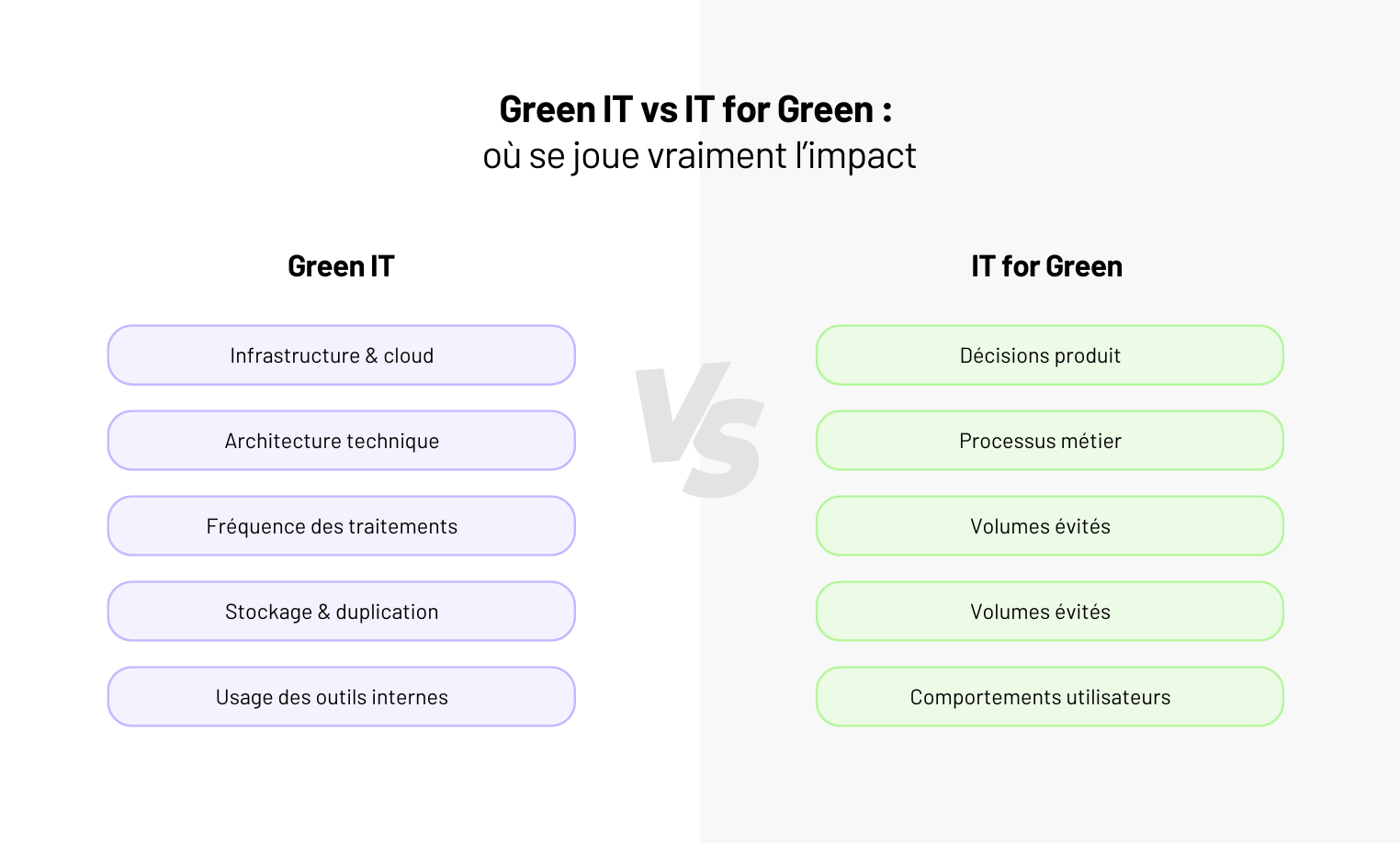
Green IT vs IT for Green : l’impact ne se joue pas là où on le croit
Green IT et IT for Green ne posent pas les mêmes questions, n’impliquent pas les mêmes choix, et n’agissent pas au même niveau. C’est un problème de pilotage produit autant que de décisions techniques.
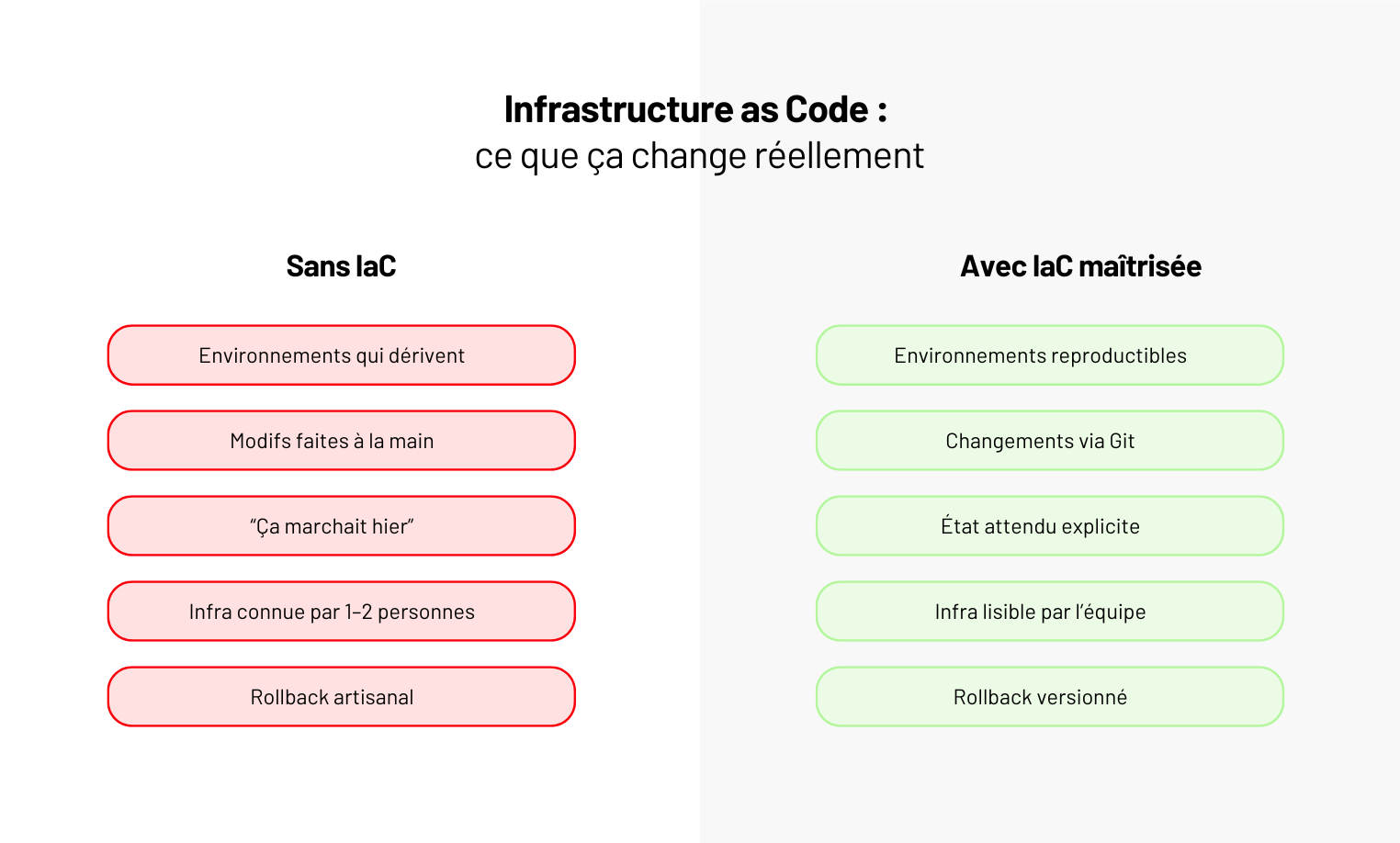
Infrastructure as Code : définition, avantages, et comparatif Terraform vs Pulumi
Une IaC incomplète crée souvent plus de risques qu’elle n’en supprime. Dans cet article, on pose les bases.
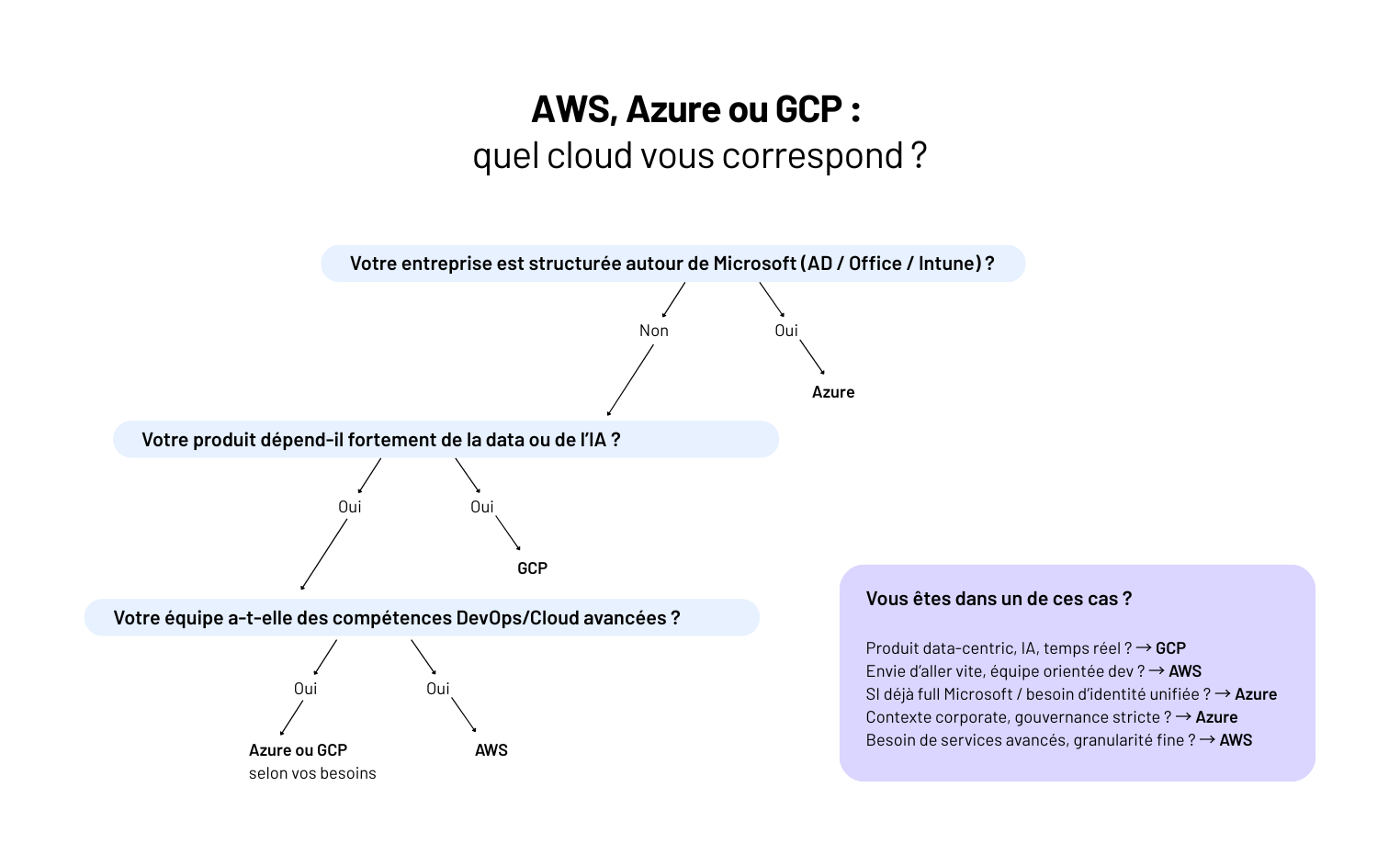
Comparatif AWS vs Azure vs GCP : lequel choisir ?
La question n’est donc pas : “Quel cloud est le meilleur ?”C’est : “Quel cloud correspond réellement à votre produit, votre équipe et vos contraintes pour les 5 prochaines années ?”

Docker : Le guide pour débuter en 2025 (exemples + bonnes pratiques)
Dans ce guide, on va à l’essentiel : comprendre ce que Docker fait vraiment, construire sa première image propre, éviter les pièges de débutant et adopter les bonnes pratiques qui rendent un produit reproductible partout - du laptop à la prod.
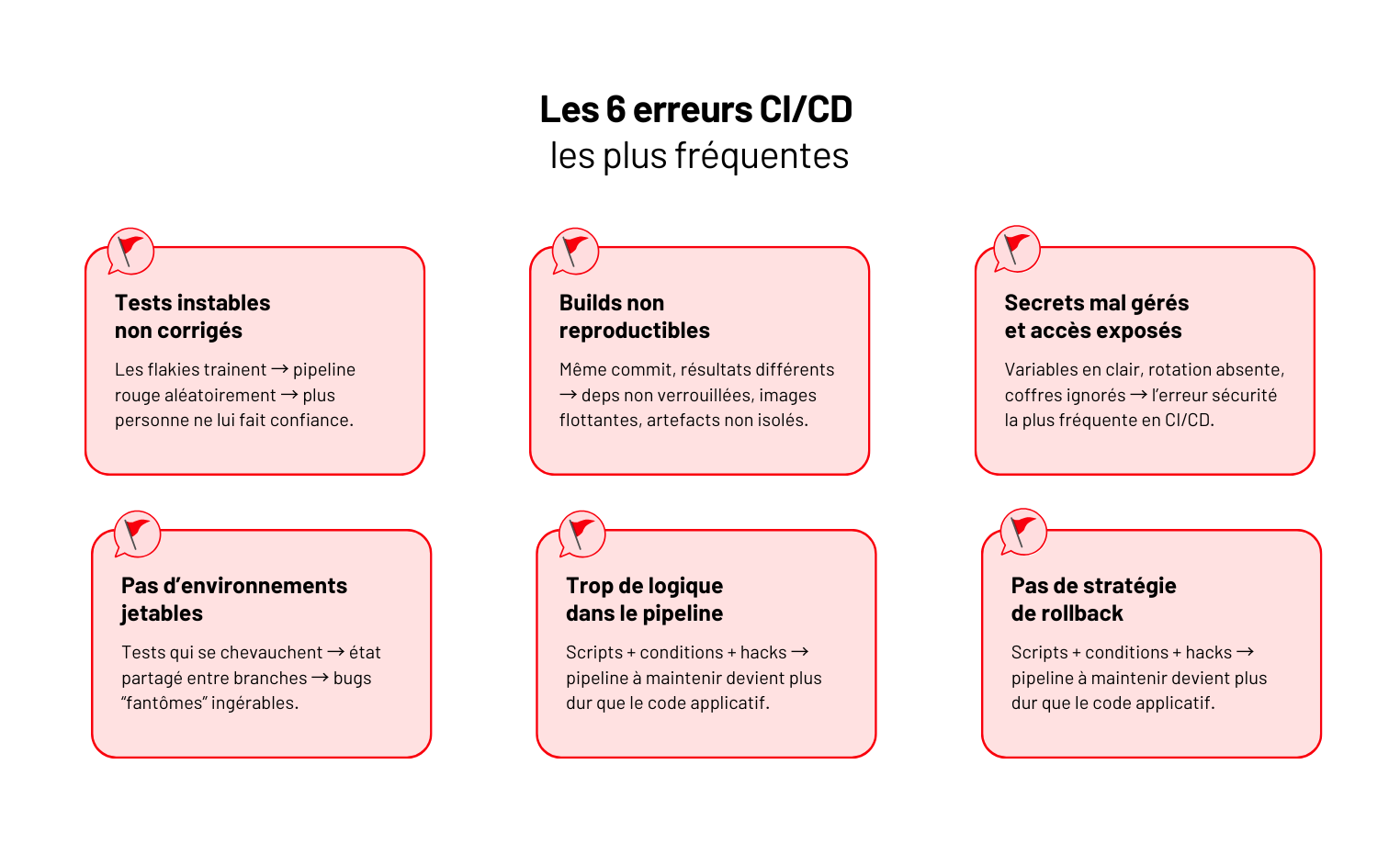
CI/CD : le guide complet du déploiement continu (outils, pipelines, best practices)
Dans ce guide, on simplifie tout : les vraies définitions, les briques indispensables, les bons outils, les pièges qui coûtent cher et les pratiques qui rendent les mises en prod aussi banales qu’une PR.

L’intelligence artificielle dans les logiciels métiers : comment l’intégrer efficacement ?
Dans un logiciel métier, l’IA n’est pas là pour faire rêver les comités de pilotage. Elle est là pour résoudre des frictions bien tangibles : la saisie qui prend trop de temps, les documents qu’on ne lit jamais, les validations qui s’enchaînent mal, les données qu’on n’arrive pas à exploiter.
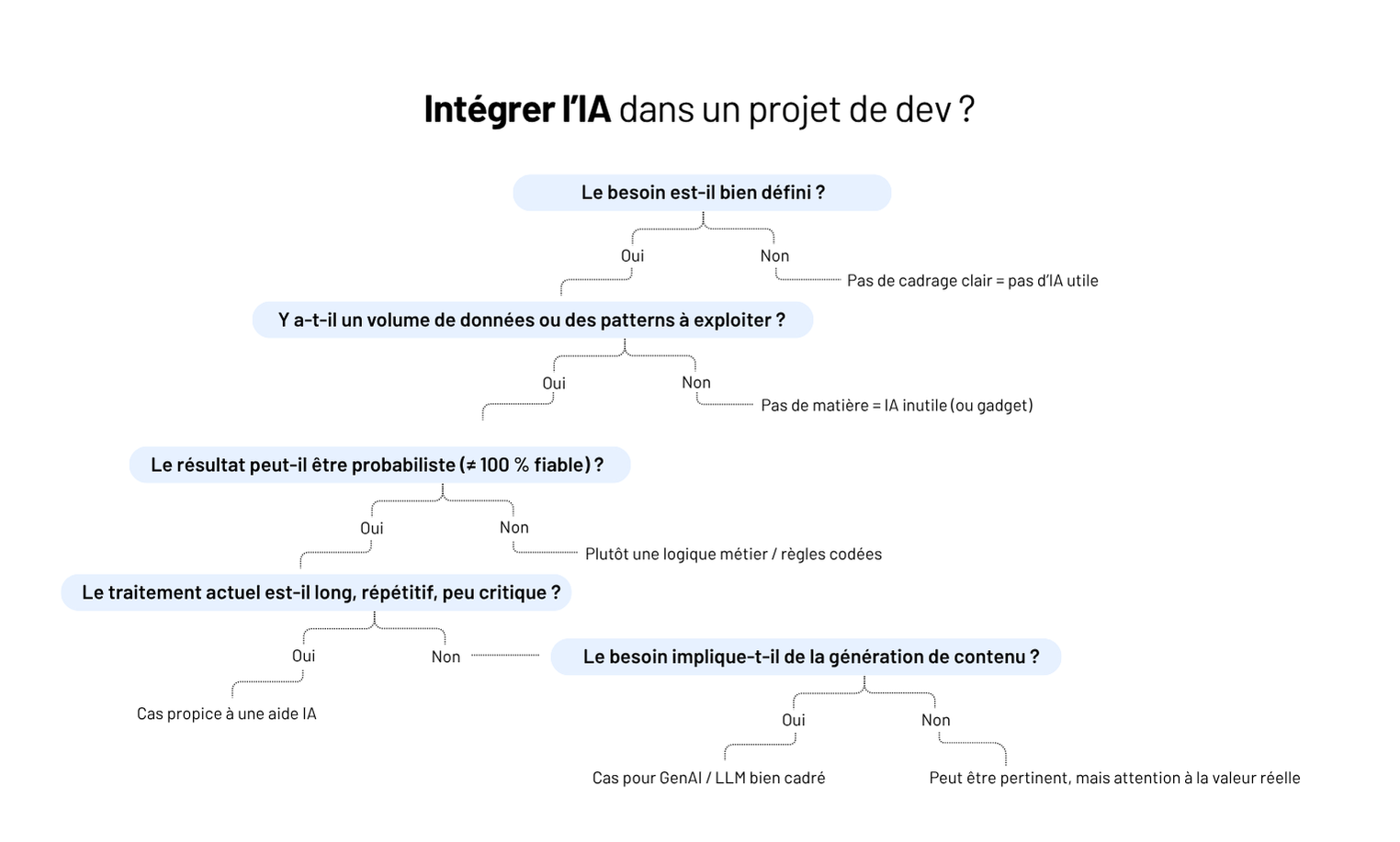
Comment utiliser l’IA dans le développement logiciel sur-mesure : cas d’usage concrets
Dans cet article, on partage 5 cas d’usage IA réellement utiles dans des projets web sur-mesure. Testés, adoptés, adaptables.
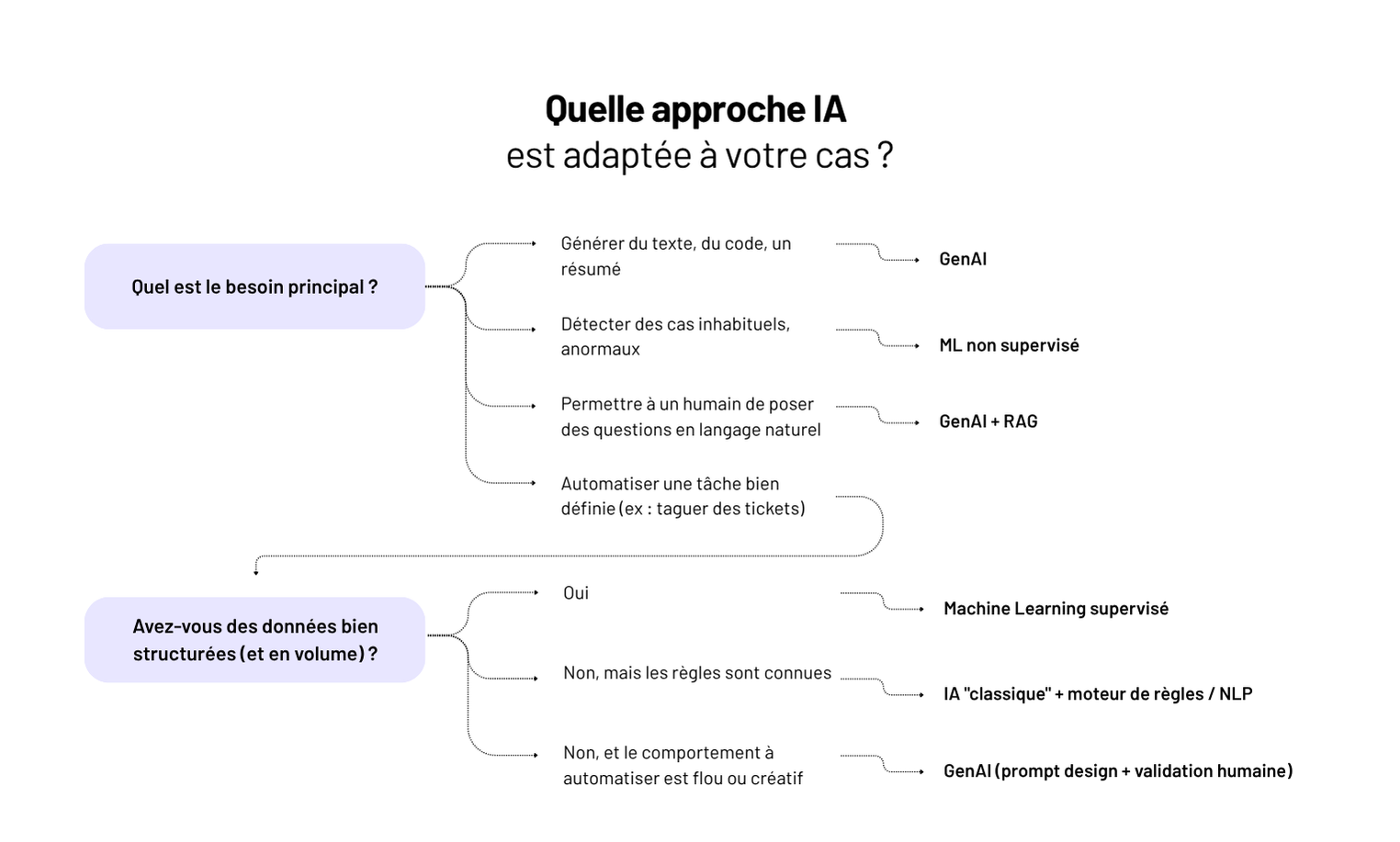
IA, ML, GenAI : comment s’y retrouver (et faire les bons choix)
IA, machine learning, GenAI : trois termes partout, souvent mélangés, rarement compris. Et derrière, des décisions mal cadrées, des attentes floues, des projets qui patinent.
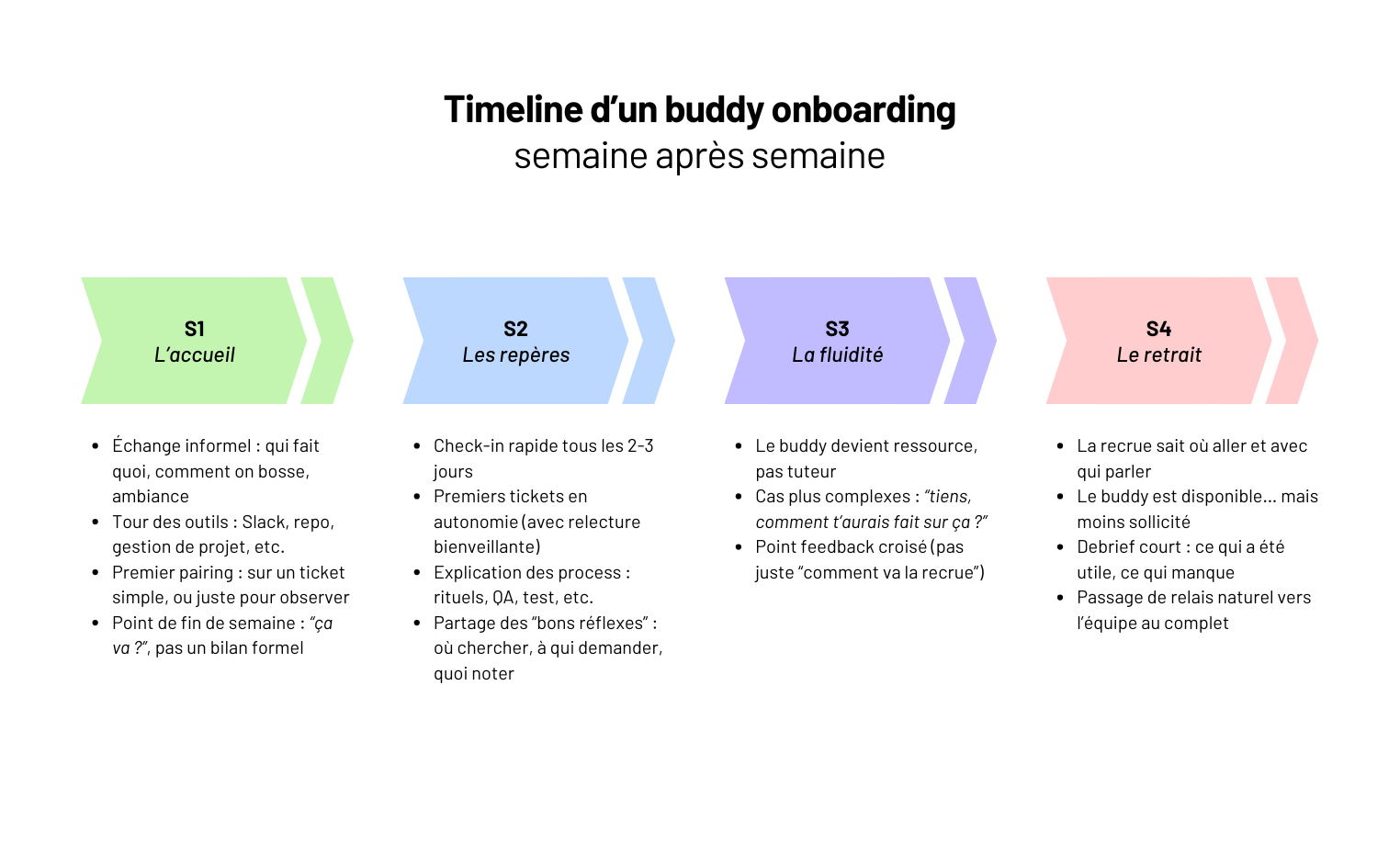
Système de buddy onboarding : les clés d’une intégration réussie en équipe tech
Un bon onboarding, ce n’est pas juste une checklist. C’est un vrai passage de relais : transmettre les réflexes, les décisions implicites, la manière de bosser ensemble. Tout ce qui ne s’écrit pas dans un wiki.
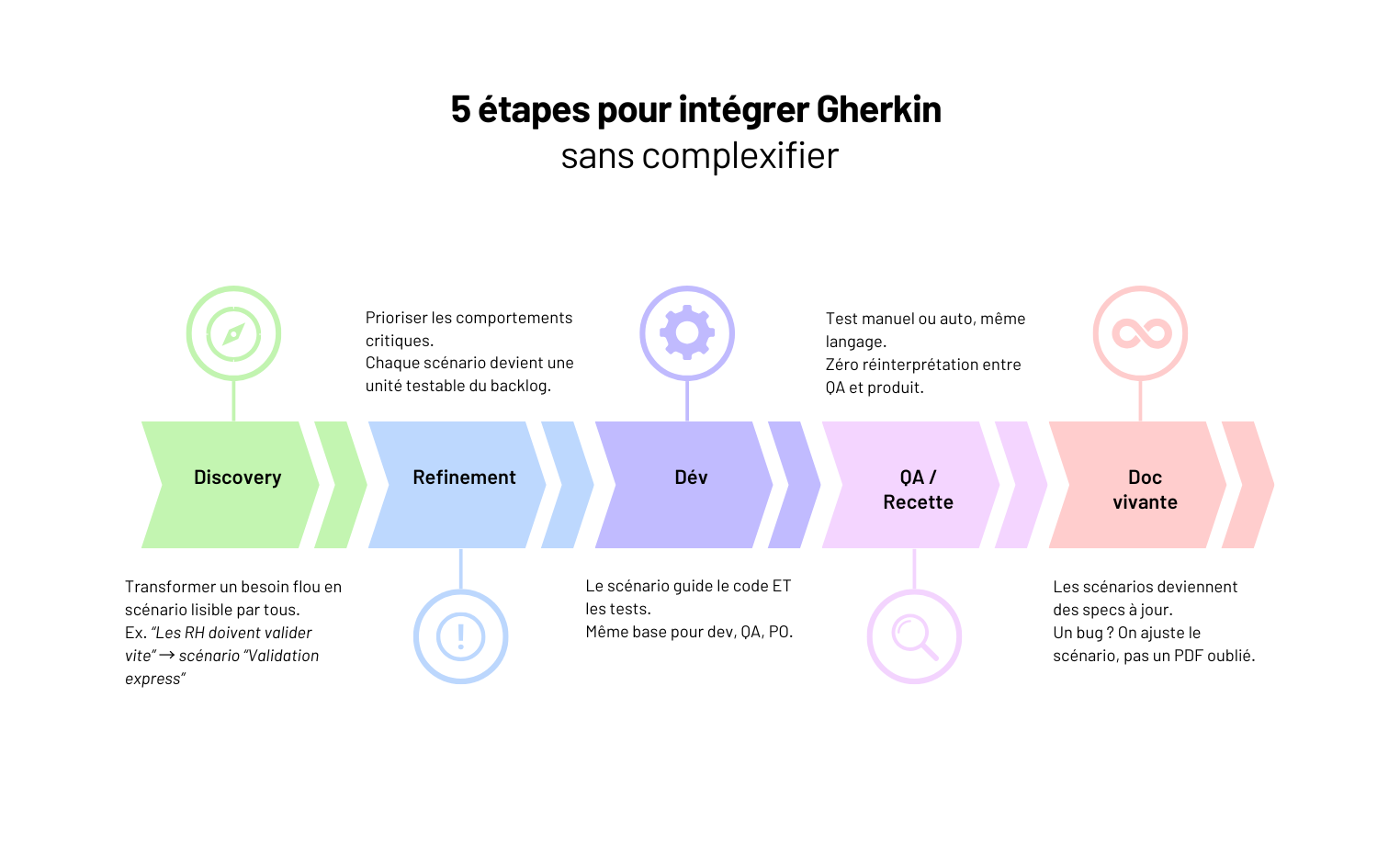
Méthodologie BDD : Comment utiliser Gherkin pour aligner tech et métier sur vos projets web
Dans cet article, on vous partage notre méthode terrain pour utiliser Gherkin à bon escient
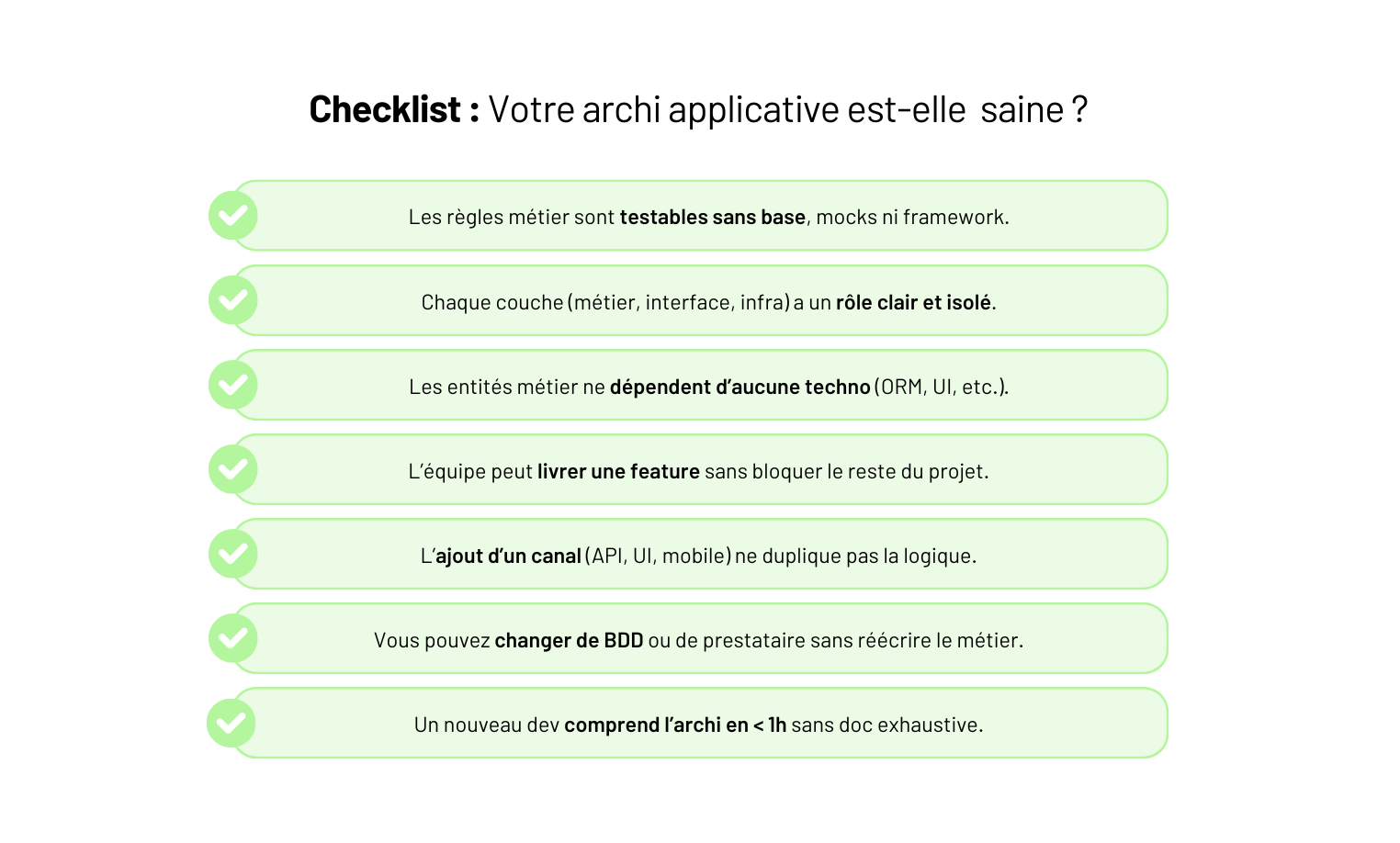
Concevoir une architecture applicative — poser les bases d’un produit qui tient
Dans cet article, une méthode claire pour poser les bases d’une architecture applicative qui tient
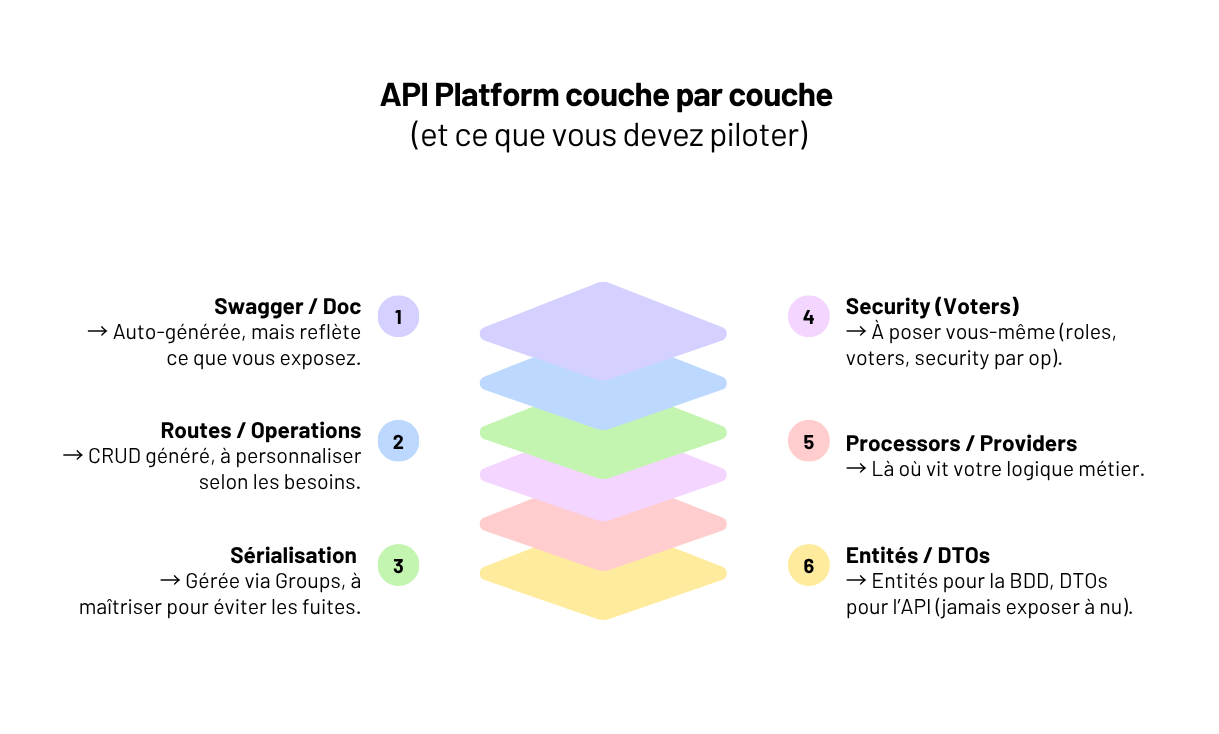
Créer une API REST en Symfony avec API Platform : le tuto complet (et réaliste)
Une base propre, testable, versionnable, maintenable. Avec les bonnes conventions, les pièges à éviter, et les patterns qu’on applique pour que l’API tienne — en prod, sur la durée.
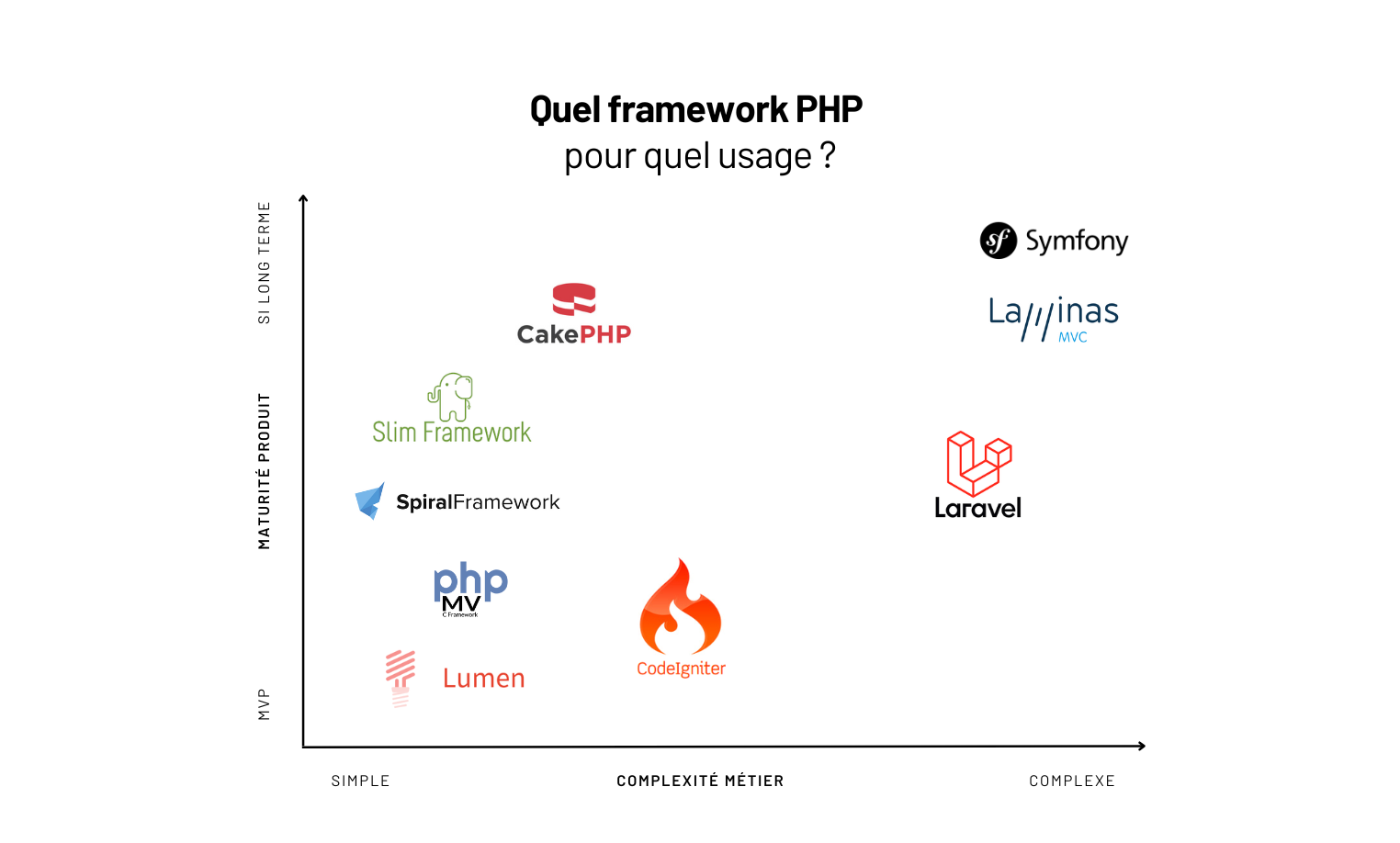
Top 10 des frameworks PHP en 2025 (pour un produit qui tient)
Dans cet article, pas de “framework miracle”. Juste un top 10 des frameworks PHP en 2025 qui comptent vraiment — parce qu’ils aident à construire des produits robustes. Avec, pour chaque techno : ses forces, ses limites, et les contextes où elle brille vraiment

Clean Code : comment écrire un code qu’on relit sans souffrir ?
Dans cet article, pas de dogme. Juste ce qu’on a retenu après des dizaines de projets, et ce qu’on applique (ou pas) quand on veut écrire du code propre qui tourne.

Symfony en 2025 : la techno que les grands comptes n’ont (vraiment) jamais quittée
Dans cet article, on explique ce qui fait revenir Symfony dans les grandes boîtes, les cas où il reste imbattable, et les erreurs à ne pas refaire.

Symfony vs Laravel vs Node.js : le bon framework pour un logiciel métier en 2025 ?
Dans cet article : pas de débat dogmatique. Juste une grille claire pour faire un choix éclairé. Avec des retours terrain, et les bons critères pour ne pas planter la base technique d’un produit métier.

Clean Architecture : comment structurer votre app pour éviter la dette demain
C’est un cadre simple pour séparer les responsabilités, découpler le métier de la technique, et construire une app qui tienne dans le temps — même quand les règles changent, même quand l’équipe tourne.

Externaliser ou internaliser son équipe de développeurs ?
Dans cet article, on vous partage une grille claire pour choisir intelligemment. Pas pour trancher une bonne fois pour toutes. Mais pour prendre la bonne décision, projet par projet.

Top 5 des agences IA en France
Dans cet article, on vous partage 5 agences IA qui font vraiment le job. Celles qui livrent des solutions d'Intelligence Artificielle activables, mesurables, maintenables.

Top 5 des agences data en France
Dans cet article, on vous partage 5 agences capables de livrer autre chose qu’un dashboard ou un POC qui dort dans un coin.

Développeurs seniors : la seule garantie d’un produit web qui tient dans le temps
La vraie question n’est pas “Combien coûte une équipe senior ?” C’est : “Combien vous coûte une équipe qui n’anticipe rien, livre lentement, et fait exploser les tickets Jira à 6 mois ?”

Quelles technologies choisir pour une application web en 2025 ?
React ou Vue ? Monolithe ou microservices ? Serverless ou conteneurisé ? En 2025, choisir les bonnes technologies pour développer une application web n’a jamais été aussi structurant… ni aussi risqué.

Git, GitHub et GitLab : quelles différences ?
GitHub et GitLab sont deux plateformes incontournables lorsqu’on parle de collaboration autour du code. Toutes deux reposent sur Git, le système de versioning le plus utilisé au monde. Mais quelle solution est la plus adaptée à ton organisation ? On fait le point.

Les 100 langages de programmation à connaître en 2025
L’objectif : découvrir les langages les plus utilisés, les plus utiles, les plus prometteurs — ou parfois simplement les plus surprenants.
Qu’est-ce que le refactoring ?
Tu en as assez de travailler avec du code désorganisé qui ralentit ton développement ? Le refactoring est sans doute la clé pour révéler tout le potentiel de ton base code.

Changer de version Node.js avec NVM : le guide
Guide complet pour changer de version Node.js avec Node Version Manager (NVM) : installez, gérez les versions, évitez les conflits.

Hard Delete vs Soft Delete : que choisir ?
Découvrez quand choisir le Hard Delete ou le Soft Delete dans la gestion des données. Avantages, exemples de code et conseils essentiels.
.webp)
Laravel vs Symfony : quel Framework choisir ? Le guide
La comparaison détaillée entre Laravel et Symfony. Performances, sécurité, courbe d'apprentissage : quel Framework PHP choisir pour votre projet web ?

Vue.js vs React.js : quel Framework pour son projet ?
Comparaison entre Vue.js et React.js, deux géants du développement web. Performance, apprentissage, modularité : quel Framework pour votre projet ?

Développement d’une application Android avec React Native
Découvrez le guide ultime du développement d’application mobile Android avec React Native. Transformez votre idée en réalité.

Systèmes d'exploitation pour smartphone iOS et Android
Découvrez les spécificités des systèmes d'exploitation pour smartphones iOS et Android et le développement cross-platform avec React Native.

Chat application mobile : Intercom, Crisp, Brevo
Découvrez comment intégrer des chats comme Intercom, Crisp, Brevo dans vos apps mobiles pour améliorer l'engagement utilisateur.