“Migrer vers le cloud”, ça sonne simple. En réalité, c’est là que beaucoup de projets se plantent. On ne déplace pas juste des serveurs : on change d’architecture, de gouvernance, et parfois… de culture technique.
Ce qu’on voit chez Yield :
- des migrations “rapides” qui doublent la facture faute de FinOps ;
- des IAM ingérables qui ouvrent des failles ;
- des architectures on-prem copiées-collées dans AWS, Azure ou GCP… et impossibles à maintenir.
👉Le cloud n’améliore pas un système fragile. Il en amplifie les défauts.
Dans ce guide, on remet de l’ordre : pourquoi migrer en 2025, comment choisir entre AWS/Azure/GCP, quelles approches fonctionnent vraiment, et comment migrer sans casser la prod ni exploser le budget.
Pourquoi migrer vers le Cloud en 2025 (et pourquoi ce n’est plus un sujet tech)
On migre rarement vers AWS, Azure ou GCP“pour “faire moderne”.
On migre parce que le système actuel limite le produit : trop lent, trop rigide, trop cher à faire évoluer - ou incapable d’absorber la croissance.
En 2025, les vraies raisons ressemblent à ça :
Scalabilité sans travaux forcés
Le cloud ne scale pas pour vous, mais il vous donne les outils pour absorber une montée en charge sans réécrire la moitié du système.
Auto-scaling, stockage distribué, réseaux globaux : ça change la trajectoire d’un produit qui croit vite.
Sécurité et conformité intégrées à la plateforme
Chiffrement, IAM granulaire, logs centralisés, rotation automatique : les fondations sont là, prêtes, auditables.
Le cloud ne sécurise pas à votre place, mais il vous permet d’atteindre un niveau qu’il est quasiment impossible de reproduire on-prem.
Résilience native, sans bricolage
Multi-AZ, redémarrage automatique, snapshots, reprise après incident : le “toujours-on” devient réaliste même pour une PME. Rien à voir avec les clusters bricolés qu’on voit encore on-prem.
Coûts pilotables (pas forcément plus bas, mais maîtrisables)
Le vrai avantage du cloud, ce n’est pas l’économie.
C’est le contrôle : on paie ce qu’on utilise, on surveille, on ajuste.
Le coût devient une variable du produit, pas un bloc fixe impossible à optimiser.
Accès immédiat aux briques modernes
C’est souvent la raison la plus sous-estimée : data pipelines, serverless, IA managée, edge, stockage distribué… Toutes ces capacités transforment la manière de concevoir un produit.
Pas besoin de monter une équipe “infra + ML + ops” : le cloud fournit des briques prêtes, fiables, intégrées.
📌 À retenir
Le cloud n’est pas magique.
C’est un amplificateur :
- d’agilité si votre architecture est saine,
- de dette si elle ne l’est pas.
C’est pour ça que la migration n’est plus un sujet tech.
C’est un sujet produit + architecture + gouvernance.
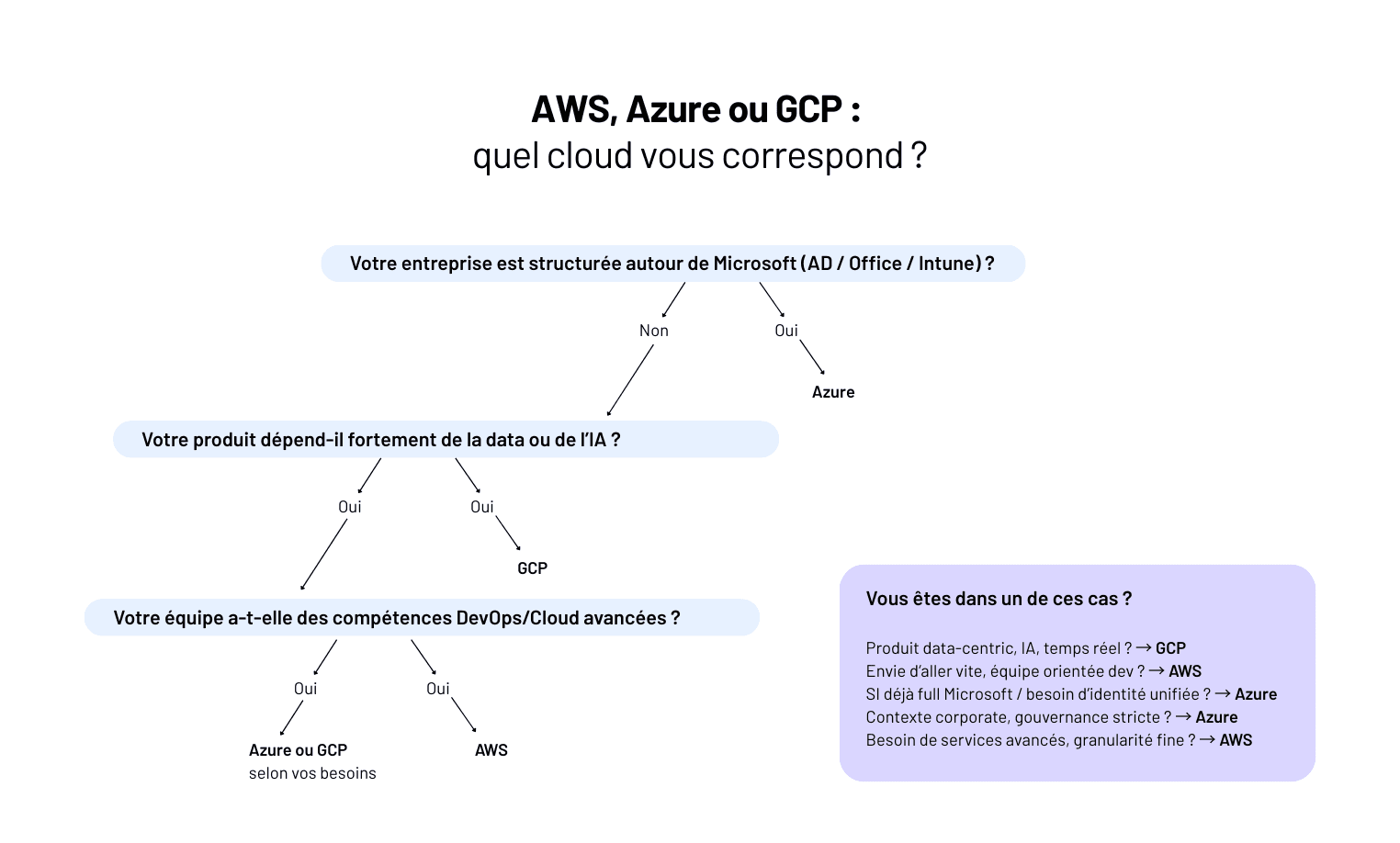
AWS, Azure, GCP : lequel choisir (et pour qui) ?
En 2025, les trois clouds se valent… sur le papier.
Dans la pratique, leurs forces ne sont pas les mêmes - et vos contraintes d’équipe, d’architecture et d’existant pèsent bien plus que le catalogue de services.
AWS - La boîte à outils la plus complète (et la plus exigeante)
AWS, c’est le couteau suisse du cloud :
- services matures ;
- documentation massive ;
- intégrations solides partout.
Parfait si votre équipe a déjà une culture DevOps / IaC et veut tirer parti de briques avancées : Lambda, S3, ECS/EKS, DynamoDB, EventBridge…
Les plus : puissance, granularité, écosystème.
Les moins : pricing complexe, IAM très strict (et facile à mal configurer), learning curve rude.
👉 Le bon fit : scale-up tech-driven, SaaS moderne, produits data-heavy.
Azure - Le choix naturel des organisations Microsoft
Si votre SI tourne déjà autour de Microsoft (AD, Office 365, Teams, Intune…), Azure simplifie tout : gestion des identités, intégration réseau, sécurité centralisée, monitoring unifié.
C’est le cloud préféré des DSI “corporate”, avec un bon équilibre entre gouvernance, services managés et conformité.
Les plus : continuité Microsoft, IAM intégré, bon support entreprise.
Les moins : UX parfois inégale, catalogue riche mais moins homogène.
👉 Le bon fit : entreprises déjà Microsoft, apps métiers, organisations avec forte gouvernance interne.
GCP - Simplicité, data & ML en mode premium
GCP n’a pas le volume d’AWS, mais il excelle dans ce qui compte pour les produits modernes :
- BigQuery pour l’analyse ;
- Pub/Sub pour les architectures événementielles ;
- Vertex AI pour l’IA managée ;
- une ergonomie de console bien au-dessus des autres.
Les plus : data/ML, pricing lisible, DX agréable.
Les moins : écosystème plus réduit, moins d’intégrations “enterprise”.
👉 Le bon fit : produits data-centric, apps en temps réel, équipes qui veulent aller vite sans se noyer dans l’architecture.
💡 Règle Yield
Le bon cloud, c’est celui que vos devs, vos ops et votre DSI peuvent réellement opérer.
- Si votre équipe est full JS/TS → AWS ou GCP fonctionnent très bien.
- Si vous vivez dans Microsoft depuis 10 ans → Azure sera plus simple.
- Si la data est votre cœur de valeur → GCP sera imbattable.
La migration se gagne sur la soutenabilité, pas sur le catalogue.
“Dans 80 % des migrations qu’on reprend, le problème ne vient pas du cloud choisi. Il vient d’un provider imposé sans regarder les compétences internes.Quand une équipe JS se retrouve à opérer Azure “parce que la DSI préfère”, la migration est déjà compromise.”
— Simon, Cloud Architect @ Yield Studio
Les 4 modèles de migration (et les pièges derrière chaque approche)
Dans la plupart des missions qu’on reprend chez Yield, le problème n’est pas AWS, Azure ou GCP : c’est le modèle choisi au départ.
Voici les quatre approches possibles… et leur réalité.
Lift & Shift : la tentation du “vite fait”
C’est l’approche la plus vendue, la plus rapide, et la plus risquée : déplacer l’infrastructure telle quelle.
En théorie, ça marche.
En pratique, on copie les mauvaises habitudes, on multiplie les coûts, et on ajoute de la dette technique dans un environnement plus complexe.
On l’a vu plusieurs fois :
- une architecture monolithique copiée dans AWS ;
- zéro optimisation réseau, zéro autoscaling, zéro rationalisation ;
- et une facture x2 en trois mois.
🚨 Red flag
Si le principal argument pour un Lift & Shift, c’est “on n’a pas le temps”, c’est que vous allez payer l’addition plus tard - et plus cher.
Re-platforming : moderniser juste ce qu’il faut
C’est le modèle le plus sain pour 70 % des projets : on garde l’architecture générale, mais on remplace les briques sensibles par du managé.
Pas de rupture, mais un vrai gain : bases SQL managées, stockage objet cloud, CI/CD automatisé, load balancer propre.
Ce qu’on constate à chaque fois :
- moins d’ops ;
- plus de stabilité ;
- un terrain propre pour faire évoluer le produit après migration.
C’est la bonne approche quand le produit fonctionne… mais souffre d’un socle vieillissant.
Re-factoring : la migration qui sert la roadmap
Ici, l’objectif n’est plus “déplacer”, mais améliorer : découper un service, isoler une brique critique, introduire de l’event-driven, revoir la persistance ou la mise à l’échelle.
C’est un investissement, oui. Mais sur des produits qui évoluent vite, c’est la seule façon d’arrêter de se battre contre la dette technique.
“Un refactoring cloud réussi, ça se voit dans la maintenance : si vos coûts n’ont pas commencé à baisser au bout de 3 mois, c’est que vous avez juste déplacé le problème dans AWS.”
— Hugo, Engineering Manager @ Yield Studio
Re-build : quand continuer coûte plus cher que repartir
Parfois, la vérité est brutale : le legacy n’est plus rattrapable.
Trop de dépendances, trop de code mort, trop d’effets de bord.
Dans ces cas-là, repartir de zéro n’est pas un caprice technique, mais la seule décision rationnelle.
Mais on le dit clairement : c’est rare. Et ça ne fonctionne que si le cadrage est serré, la dette identifiée et la roadmap maîtrisée.
Ce qu’on voit sur le terrain
Dans les migrations qu’on accompagne, la répartition est presque constante :
- le Lift & Shift fonctionne uniquement quand l’existant est déjà propre ;
- le Re-platforming est le meilleur compromis dans la majorité des cas ;
- le Re-factoring est rentable quand la roadmap est ambitieuse ;
- le Re-build ne s’impose que pour les systèmes en fin de vie.
👉 Le modèle n’est jamais “technique”. C’est un choix stratégique : quelle valeur la migration doit créer, et à quel horizon ?
Préparer la migration : la phase la plus sous-estimée
Chez Yield, on insiste toujours sur un point : la migration se gagne en amont, pas dans Terraform ni dans les consoles AWS/Azure/GCP.
Et quand on récupère un projet qui a dérapé, les mêmes symptômes reviennent systématiquement.
On ne sait pas ce qu’on migre
Ça paraît absurde, mais c’est la cause numéro 1 des dérives.
Des services oubliés.
Des jobs cron cachés quelque part.
Des endpoints qui servent encore “un vieux client”.
Des secrets dans des fichiers qu’on pensait morts.
Une migration cloud, c’est d’abord une cartographie honnête : flux réseau, dépendances, volumes data, jobs planifiés, logs, certificats, environnements parallèles.
👉 Tant que tout ça n’est pas clair, chaque étape devient un pari.
La dette technique reste sous le tapis
Migrer un système fragile dans le cloud ne le rend pas plus robuste : ça le rend juste plus cher. Et plus difficile à diagnostiquer.
On fait toujours un tri avant de migrer :
- code mort ;
- configurations dupliquées ;
- modules inutilisés ;
- logs illimités ;
- scripts bricolés.
Rien de glamour. Mais c’est ce qui fait la différence entre une infra cloud maîtrisée et un monolithe sous perfusion.
🚨 Red flag
Si vous “n’avez pas le temps” de nettoyer, la migration prendra deux fois plus longtemps et coûtera deux fois plus cher.
Le réseau est mal défini (et c’est souvent le premier mur)
VPC, subnets, NAT, règles inbound/outbound, peering, VPN, bastions…
Le réseau cloud n’a rien de magique : il est juste plus strict et plus explicite que l’on-prem.
Toutes les migrations douloureuses qu’on a vues avaient un point commun :
- réseau bricolé dès le départ ;
- IAM ouvert “provisoirement” ;
- accès admin laissé trop longtemps.
On pose d’abord le squelette : isolation stricte, comptes séparés, permissions minimales, rotation automatique des credentials. Tout le reste s’appuie dessus.
L’infrastructure n’est pas décrite (IaC) → dette immédiate
Terraform, Pulumi, CDK… peu importe l’outil.
Mais sans Infrastructure-as-Code, une migration cloud devient ingérable.
Impossible de rejouer un environnement, impossible de tester, impossible d’auditer.
On met toujours toute l’infra cible en IaC avant de migrer un premier service.
C’est la base d’un cloud maintenable sur 3 à 5 ans.
Avant de migrer, il faut déjà observer
On ne migre pas un système qu’on ne mesure pas.
On installe l’observabilité (logs, métriques, traces) avant la migration.
L’objectif : connaître l’état normal du système pour savoir si quelque chose casse côté cloud.
Sur un projet logistique qu’on a migré vers Azure, la simple mise en place du monitoring avant migration a révélé :
- 17 endpoints non utilisés ;
- 2 scripts planifiés oubliés ;
- une charge CPU x3 le lundi matin ;
- un batch qui mettait 22 minutes de plus que prévu.
Tous ces points auraient explosé dans Azure… mais ce n’est plus une surprise quand on les voit venir.
Conclusion - Le cloud amplifie ce qui existe déjà
Migrer vers AWS, Azure ou GCP peut changer la trajectoire d’un produit… ou l’alourdir durablement. Le cloud ne corrige pas les faiblesses : il les rend plus visibles, plus rapides et souvent plus coûteuses.
Ce qui fait la différence, c’est la clarté de l’intention, la qualité de la préparation, et la capacité de l’équipe à opérer un système plus strict, plus explicite, plus exposé.
Une migration réussie tient en trois idées simples :
- comprendre pourquoi on migre ;
- choisir un modèle cohérent avec sa dette et sa roadmap ;
- exécuter progressivement, en observant tout ce qui bouge.
Chez Yield, c’est exactement ce qu’on construit : des migrations cloud propres, mesurables, et soutenables dans le temps.
👉 Vous préparez une migration vers AWS, Azure ou GCP ? On peut vous aider à cadrer vos choix, sécuriser votre architecture et éviter les pièges qui coûtent cher.