Nos experts vous parlent
Le décodeur


Recruter un développeur. Puis un designer. Puis un PM. Puis un DevOps. Puis un QA.
Et faire en sorte que tout ce petit monde fonctionne ensemble… vite.
Beaucoup d’entreprises veulent construire leur propre équipe pour lancer leur produit digital.
Mais la réalité, c’est ça :
- 6 mois de recrutement pour aligner les bons profils.
- Une stack à poser de zéro.
- Des allers-retours sans fin sur les specs.
- Une V1 qui n’arrive jamais.
Dans un projet web complexe - SaaS B2B, plateforme métier, portail transactionnel - le risque, ce n’est pas de mal coder. C’est de prendre 12 mois pour valider une idée.
C’est là que l’externalisation change tout. Pas en “sous-traitant” le dev. Mais en accédant immédiatement à une équipe produit complète - prête à livrer, outillée, expérimentée.
👉 Dans cet article, on vous montre pourquoi externaliser auprès d’une agence de développement web peut être la décision la plus rapide, la plus solide, et la plus stratégique pour créer un produit digital qui tient.
Accéder à une équipe produit complète, prête à délivrer
Créer une application web, ce n’est pas juste “trouver un bon développeur”.
C’est :
- poser une architecture solide (cloud-native, modulaire, scalable) ;
- gérer des flux complexes (ERP, SSO, paiements, APIs tierces) ;
- construire un design qui convertit et engage ;
- automatiser les tests, le delivery, la mise en production.
Et surtout : faire travailler ensemble tous ces métiers — produit, design, tech, ops — dès le premier sprint.
👉 Monter cette équipe en interne ? Comptez 6 à 12 mois. Entre le sourcing, les entretiens, l’onboarding, et la montée en compétence collective.
En externalisant, vous accédez immédiatement à une équipe prête :
- Développeurs fullstack avec une vraie culture produit (pas juste des intégrateurs) ;
- Architectes capables de dimensionner une stack robuste, cloud-native, sécurisée ;
- UX/UI designers formés aux logiques SaaS : onboarding, activation, rétention ;
- Product Managers pour cadrer, prioriser, arbitrer avec méthode ;
- DevOps & QA pour sécuriser le delivery dès le jour 1.
Résultat ? Pas de phase de staffing. Pas de formation à prévoir. Une vélocité utile dès la première semaine.
Externaliser, ce n’est pas perdre la main. C’est gagner 6 mois sur la construction de votre socle produit.
Cadrer et piloter comme une boîte produit senior
Beaucoup de projets digitaux échouent non pas à cause de la technique, mais à cause du pilotage. Specs mouvantes. MVP flou. Décisions tardives. Backlog ingérable.
👉 Externaliser avec une agence de développement web permet d’installer, dès le départ, une méthode robuste - éprouvée sur des dizaines de produits.
Le cadrage n’est pas une formalité, c’est la fondation
Avant de livrer, on construit :
- une Product Discovery pour observer les vrais irritants terrain ;
- une boussole produit : cap business, cible utilisateur, North Star Metric ;
- des user stories concrètes, co-écrites avec les métiers.
Tout est structuré pour éviter l’effet tunnel. Chaque décision produit est alignée avec la vision. Chaque fonctionnalité est priorisée selon l’impact utilisateur, pas l’intuition du moment.
👉 Ce n’est pas une méthode “agile” décorative. C’est un cadre clair, partagé, qui transforme une idée en produit piloté.
Ce qu’on cherche = une V1 testable rapidement
Pas de specs de 60 pages. On définit avec vous un parcours prioritaire, utile dès les premières semaines. C’est la logique du slicing vertical : livrer petit, mais complet, pour tester vite.
Exemple :
Sur une plateforme B2B, plutôt que “gérer les commandes”, la V1 permet simplement de créer une commande + recevoir une notification de traitement.
Simple. Réaliste. Testable.
👉 Ce cadrage évite les dérives classiques des projets internes :
- backlog en roue libre ;
- MVP théorique ;
- 6 mois sans aucun retour utilisateur.
Avec une agence experte, vous ne perdez pas le contrôle. Vous gagnez un cadre de pilotage solide, qui vous accompagne jusqu’à la mise en production.
Livrer une V1 en 6 semaines, itérer dès la 8e
Un produit digital qui met 8 mois à sortir une première version testable ? C’est souvent déjà trop tard.
Les besoins ont évolué. Les concurrents ont dégainé plus vite. Les équipes internes doutent. Et le produit devient… un sujet sensible.
Externaliser avec une agence spécialisée, c’est éviter ce scénario.
Une V1 en quelques semaines, pas en quelques trimestres
Dès le cadrage, on identifie un parcours prioritaire - ce que vos futurs utilisateurs peuvent vraiment tester, utiliser, valider.
Pas besoin de tout livrer. On construit un MVP ciblé : juste assez pour déclencher de vrais retours, observer des usages concrets, mesurer ce qui compte.
Exemples de MVP typiques livrés en 6 à 8 semaines :
- SaaS d’abonnement : onboarding client + création de plan + génération de facture.
- Portail B2B : création de commande + suivi de statut + dashboard client.
- Plateforme de contenu : inscription + accès 1er module + scoring utilisateur.
👉 Ce qu’on livre n’est pas une démo. C’est un produit testable, qui permet d’apprendre vite, d’itérer intelligemment.
Et des déploiements sans panique
Aller vite, oui. Mais pas à l’aveugle.
L’agence met en place un pipeline de delivery solide :
- Feature flags : activer ou masquer une feature sans rollback ;
- Canary releases : tester sur un segment d’utilisateurs avant généralisation ;
- Monitoring natif : erreurs, lenteurs, crashs - tout est traqué dès le jour 1.
Résultat : on peut livrer chaque semaine, sans créer de dette. Et surtout : chaque livraison rapproche le produit de ce que veulent les utilisateurs.
C’est ça, l’avantage d’externaliser avec une équipe outillée, expérimentée, structurée.
Maîtriser les coûts sans recruter toute une équipe
Recruter en interne, c’est séduisant sur le papier. Mais dans la vraie vie, ça veut dire :
3 mois pour un Product Owner, 4 mois pour un développeur senior (s’il vient), 6 mois pour trouver un DevOps, et un budget RH qui explose.
Externaliser, c’est éviter de transformer un projet en plan de staffing.
Un budget prévisible, une équipe opérationnelle tout de suite
Avec une agence experte, vous connaissez :
- le périmètre qu’on va couvrir en 6 à 8 semaines ;
- l’équipe dédiée mobilisée dès la première semaine ;
- le coût, sans charges indirectes, sans période d’essai, sans délai de montée en compétence.
Et surtout : vous ne payez pas pour “recruter une équipe produit” - vous accédez directement à une équipe qui tourne.
Une expertise mutualisée, sans sacrifier la qualité
Un CTO freelance à temps plein ? 100K€/an. Un Product Manager senior en CDI ? Encore plus. Une équipe complète, coordonnée, disponible ? Presque mission impossible si vous partez de zéro.
En externalisant, vous mutualisez les profils seniors (UX, Dev, Lead Tech, Product…) sans compromis sur la qualité.
👉 Vous bénéficiez du savoir-faire d’une équipe qui a déjà fait - et réussi - des projets similaires. Pas besoin de réinventer la roue, ni de brûler du cash en tâtonnant.
Et un risque projet réduit dès le cadrage
Ce qui coûte cher dans un projet, ce n’est pas l’exécution. C’est l’imprécision.
👉 Sans cadrage clair, sans roadmap alignée, sans pilotage produit… un projet complexe finit toujours par déraper.
Par la méthode, l’expérience et l’outillage, une agence spécialisée vous protège de ces dérives :
- Roadmap basée sur la valeur, pas sur l’opinion ;
- Découpage réaliste, livraisons incrémentales ;
- Stack technique adaptée à votre besoin réel, pas à la hype du moment.
Externaliser, ce n’est pas “perdre le contrôle”. C’est prendre les bonnes décisions dès le départ, avec des gens qui savent comment faire.
Travailler avec un vrai partenaire produit, pas un sous-traitant
Externaliser, ce n’est pas “déléguer à distance” à un prestataire qui déroule un cahier des charges. C’est construire un produit digital en co-pilotage, avec une équipe qui challenge, structure, délivre - et s’engage.
👉 Une agence experte ne “prend pas des specs”. Elle crée de la clarté produit avec vous, et livre dans une logique de valeur.
Un partenaire stratégique, pas une boîte noire
Ce que vous cherchez, ce n’est pas une ligne de code. C’est un produit digital qui fonctionne, s’adopte, évolue.
C’est là que le modèle change :
- On démarre par une phase de Product Discovery : pour comprendre le terrain, reformuler le vrai problème, valider les hypothèses critiques.
- On structure une boussole produit : vision business, cible prioritaire, North Star Metric.
- On priorise par la valeur, pas par l’intuition.
- Et on livre un MVP testable, pas un périmètre hors sol.
👉 Ce cadre méthodologique, c’est ce qui fait la différence entre une livraison subie… et un vrai produit qui tient la route.
Une équipe intégrée, pas des profils isolés
Chez Yield, ce qu’on mobilise, ce ne sont pas “quelques devs à dispo”. C’est une Product Team complète qui a l’habitude de travailler ensemble - Product Manager, UX Designer, Lead Dev, DevOps.
Ce mode d’organisation garantit :
- une prise de décision rapide ;
- des arbitrages alignés ;
- une cohérence produit de bout en bout.
👉 Et c’est exactement ce qui évite les silos, les ping-pongs, et les incompréhensions de dernière minute.
Conclusion - Externaliser, ce n’est pas renoncer. C’est avancer.
Construire une application web utile, robuste, évolutive : c’est un défi. Pas seulement technique. Produit. Organisationnel. Humain.
Et vouloir tout faire en interne - sans méthode, sans équipe formée, sans culture produit - c’est souvent la recette des projets qui patinent.
👉 Externaliser avec une agence experte, ce n’est pas renoncer à la maîtrise. C’est accélérer, structurer, sécuriser.
Récapitulons ce que vous y gagnez :
- Une expertise disponible immédiatement : product, dev, design, DevOps… prêts à livrer.
- Un pilotage structuré : discovery, boussole produit, MVP découpé intelligemment.
- Un time-to-market accéléré : V1 testable en quelques semaines, itérations en boucle courte.
- Un cadre rigoureux : feature flags, canary releases, monitoring, CI/CD.
- Une flexibilité budgétaire : moins de charges fixes, plus de valeur livrée.
- Un vrai partenariat : pas une sous-traitance aveugle, mais un co-pilotage produit engagé.
Externaliser votre application web n’est pas une faiblesse. C’est une stratégie solide pour créer un produit digital qui sert, qui vit, qui tient dans la durée.

Un SaaS qui plafonne à 12 utilisateurs payants. Une plateforme B2B qui tourne en boucle sur la même feature depuis 4 mois. Un MVP livré… mais inutilisable car rien n’a été prévu côté support, auth, ou onboarding.
👉 Dans 90 % des cas, le problème n’est pas technique. C’est un cadrage raté. Pas assez clair. Pas assez structuré. Pas assez réaliste. Qui aurait pu être évité en bossant avec une agence de développement web bien carrée.
Chez Yield, on a cadré des dizaines de produits web - des SaaS early-stage aux plateformes intégrées en environnement SI. Et à chaque fois, c’est la qualité du cadrage qui fait la différence. Pas le budget. Pas la stack.
Un projet complexe, ce n’est pas un projet compliqué. C’est un projet où il faut de la méthode. Une méthode qui commence avant le premier sprint, avant le premier écran Figma, parfois même avant le premier dev.
Et c’est exactement ce qu’on vous partage dans cet article :
- comment clarifier un vrai besoin ;
- poser une vision utile ;
- prioriser sans s’éparpiller ;
- et préparer une V1 testable vite - sans sacrifier l’avenir.
Clarifier le besoin métier avant de parler techno
Avant d’écrire une ligne de code, on veut comprendre le quotidien de ceux qui utiliseront le produit. Dans un SaaS B2B, ce sont peut-être des RH qui gèrent les absences, des commerciaux qui relancent des devis, ou des DAF qui traitent les factures manuellement.
On observe ce qui est déjà bricolé : fichiers Excel maison, outils no-code abandonnés, workarounds incompréhensibles…
👉 C’est là que le besoin apparaît. Pas dans le brief de départ.
Pour structurer ces observations, on s’appuie sur un cadre simple et puissant - les Jobs To Be Done : “Quand je fais [situation], je veux [objectif] pour [bénéfice attendu]”.
Concrètement : “Quand je prépare une facture client, je veux retrouver les heures non facturées en un clic, pour éviter les oublis et gagner du temps.” Ce n’est pas une “feature facturation”. C’est une friction réelle, observable, prioritaire.
Le danger classique ? Partir d’une stack, d’un CMS, ou d’un outil low-code “déjà dispo” en interne. Ou de lister 40 fonctionnalités “parce que la concurrence les propose”.
Cadrer un projet web complexe, c’est justement résister à la tentation de tout prévoir - et commencer par ce qui compte :
- Quel est le problème qu’on résout ?
- Qui en souffre vraiment ?
- Pourquoi maintenant ?
Poser une vision produit claire et partagée
Un projet mal cadré, ce n’est pas forcément un mauvais sujet. C’est souvent une vision floue.
Dès le départ, on veut une chose : un cap qui résiste aux urgences, aux specs mouvantes et aux fausses bonnes idées. Pas une roadmap gonflée au doigt mouillé. Pas une maquette PowerPoint.
Chez Yield, on structure cette vision autour de 3 briques :
- Un cap business. Quel impact concret attend-on du produit ? Accélérer la conversion ? Réduire un coût interne ? Lancer un canal B2B ?
- Une cible utilisateur. Qui est le cœur de l’usage ? Décideur côté client ? Opérateur terrain ? Utilisateur pro qui ouvre l’app tous les jours ?
- Une North Star Metric. L’indicateur unique qui mesure si on avance dans la bonne direction. Exemple : % d’utilisateurs actifs à J30, nombre de documents validés, taux de conversion free → payant.
👉 On synthétise ça dans une boussole produit. Pas pour faire joli. Pour trancher, prioriser, décider. Une feature qui ne sert ni la cible, ni le cap, ni la NSM ? On la sort du backlog.
Sans cette boussole, tout devient urgent. Avec elle, on peut dire non - et avancer droit.
Prioriser les besoins avec méthode
Une fois la vision posée, le piège c’est de tout vouloir faire “pour la V1”. Mais un bon produit ne commence jamais par tout. Il commence par l’essentiel.
Chez Yield, on utilise une méthode simple pour hiérarchiser les besoins : la matrice valeur / effort, couplée au RICE Score :
- Reach – combien d’utilisateurs impactés ?
- Impact – à quel point ça change leur quotidien ?
- Confidence – est-ce qu’on a des preuves ou juste des intuitions ?
- Effort – effort de dev, de design, de test, d’intégration…
Résultat : chaque fonctionnalité est jugée sur une base claire, pas sur la pression du moment ou le pouvoir politique d’un stakeholder.
Exemple classique sur un SaaS :
Une équipe veut ajouter un dashboard ultra-personnalisable pour les comptes entreprise.
Mais ce dashboard ne concerne que 2 clients, mobilise 3 semaines de dev, et génère peu de valeur métier à court terme.
On tranche : pas pour la V1.
Prioriser, ce n’est pas dire non à vie. C’est dire : “pas maintenant, pas au détriment de ce qui compte.”
C’est aussi ce qui rend possible une roadmap réaliste. Et une V1 livrée vite, avec de l’impact mesurable.
Préparer la première version (MVP) pour livrer vite
Dans un projet web complexe, on ne vise pas de tout livrer. On vise de livrer vite un premier vrai usage. Un parcours complet, testable, qui crée de la valeur.
C’est ce qu’on appelle un slicing vertical : au lieu d’empiler des briques techniques, on assemble un flux utilisable de bout en bout.
👉 Sur un SaaS de gestion d’abonnements, ça peut être :
- Création de compte ;
- Configuration d’un premier plan tarifaire ;
- Génération automatique d’une première facture.
Est-ce que tout est prêt ? Non. Mais est-ce qu’on peut tester ? Oui. Et c’est ce qui compte.
Ce MVP permet de :
- tester l’expérience réelle avec des early users ;
- observer les premiers blocages ;
- poser une base solide pour les itérations.
💡 Dans nos projets, une V1 testable sort souvent en 6 à 8 semaines, parce qu’on découpe finement, on outille bien, et on se concentre sur l’impact, pas le périmètre.
Pas besoin de 40 features. Juste d’un premier vrai usage qui fonctionne.
Cartographier l’écosystème technique dès le départ
Un projet web complexe ne tombe jamais du ciel. Il doit parler à un SI existant, gérer des flux critiques, respecter des contraintes très réelles - sécurité, RGPD, authentification.
Avant d’écrire une user story, on cartographie l’écosystème :
- Quelles intégrations sont incontournables (ERP, CRM, SSO, outils métiers) ?
- Quelles API faut-il appeler, exposer, versionner ?
- Y a-t-il des contraintes fortes côté données : souveraineté, hébergement, durée de rétention ?
Un produit digital sans cette cartographie, c’est un tunnel vers l’échec. L’exemple classique : la V1 fonctionne en staging… mais l’auth SSO d’entreprise bloque tout en prod.
C’est aussi à ce moment qu’on distingue les dépendances :
- Flux critiques : sans eux, pas de MVP possible.
- Flux secondaires : à brancher plus tard, sans bloquer la V1.
Cadrer un projet, c’est aussi choisir ses batailles. Mieux vaut une V1 branchée à un seul système… qu’une plateforme figée, en attente d’un SI jamais prêt.
Organiser un pilotage projet clair (et pas bureaucratique)
Un bon cadrage, ce n’est pas qu’une vision produit. C’est aussi un cadre opérationnel pour que l’équipe puisse avancer vite, bien, ensemble.
Dès le départ, on pose les bases du pilotage :
- Un trio décisionnel stable : Product Manager, Lead Dev, UX Designer. Pas un empilement de strates. Trois voix, trois regards, un seul cap.
- Des rituels légers mais efficaces : kick-off clair, sprint plannings utiles, refinements en petits comités, démos orientées usage.
- Une Definition of Done partagée : une feature n’est terminée que si elle est testée, comprise, utilisable côté utilisateur - pas juste “dev terminé”.
👉 Le but ? Éviter les effets tunnel, les specs figées, les ping-pongs entre équipes. Ce qu’on cherche, c’est un flux de décision fluide, au plus près du produit.
C’est aussi le bon moment pour poser les règles d’engagement :
- Qui tranche quand il y a débat ?
- Qui est dispo pour valider une UX ?
- Qui doit être là (et qui ne doit pas l’être) dans les instances projet ?
Un projet web complexe mal piloté, c’est un projet qui glisse. Bien cadré, c’est un projet qui avance - sprint après sprint, arbitrage après arbitrage.
Anticiper l’après-MVP dès le cadrage
Cadrer un projet complexe, ce n’est pas juste préparer la première livraison. C’est préparer tout ce qui vient après. Car un MVP, ce n’est pas un livrable final. C’est un point de départ.
Dès le cadrage, on prévoit les conditions d’itération continue :
- Quels seront les KPIs à suivre ? (usage réel, activation, rétention, satisfaction…)
- Comment va-t-on collecter du feedback utilisateur ? (entretiens flash, support, analytics…)
- Qui s’engage sur le pilotage de la roadmap post-MVP ?
Et surtout, on anticipe les méthodes de livraison progressive :
- Feature flags : pour activer / désactiver une fonctionnalité à chaud
- Canary releases : pour déployer par segments d’utilisateurs
- CI/CD outillé : pour livrer sans dépendre d’une “release globale”
👉 L’idée, c’est de ne pas se retrouver paralysé une fois le MVP sorti. Un bon cadrage permet de penser long terme - sans complexifier à court terme.
Un produit digital bien né, c’est un produit qui peut évoluer dès la semaine suivante.
Conclusion - Cadrer, c’est sécuriser 80 % du projet
Un projet de développement web complexe ne déraille pas à la mise en prod. Il déraille bien avant, dès les premières semaines, faute de cap, de méthode, de décisions structurées.
Cadrer, ce n’est pas faire un “pré-projet”. C’est poser les fondations de tout ce qui vient après.
- Un problème utilisateur clairement défini (pas une intuition vague) ;
- Une vision produit partagée (pas une to-do géante) ;
- Une roadmap priorisée par la valeur (pas par le bruit) ;
- Un MVP testable rapidement (pas une promesse à 6 mois) ;
- Un pilotage outillé, orienté usage (pas juste un suivi de specs).
👉 Chez Yield, le cadrage n’est pas une option. C’est ce qui transforme un projet digital ambitieux… en vrai produit, utilisé, utile, et durable.
Vous voulez construire vite ? Commencez par cadrer juste.

Specs qui s’empilent. MVP retardé. Users fantômes. On voit souvent des projets digitaux démarrer fort… puis caler en plein vol. L’intention est bonne. Mais sans méthode, un produit SaaS ou une plateforme métier peut vite devenir un chantier sans cap.
Chez Yield Studio, on ne parle pas de “recette magique”. On parle de cadre robuste, éprouvé sur des dizaines de projets - des portails B2B aux SaaS scalables.
👉 Notre approche s’inspire du Lean Product Development : partir d’un vrai problème, livrer petit, mesurer, ajuster - sans jamais perdre l’utilisateur final de vue.
Ce que vous allez lire ici, c’est notre méthode en 8 étapes (et même 9 si vous lancez un produit early-stage), conçue pour transformer un besoin en produit digital utile, monétisable et durable.
0 - Clarifier l’opportunité produit (avant même de parler de dev)
Vous êtes en train de lancer un nouveau produit digital - SaaS B2B, plateforme sectorielle, portail transactionnel. Vous avez une intuition forte, un marché identifié, une équipe réduite… mais pas encore de clarté produit.
👉 Avant même de passer en mode projet, il faut tester le terrain. C’est ce qu’on appelle la Product Discovery.
Pas besoin d’une usine à idées. Juste de quoi valider que :
- votre cible a un vrai problème (observé, pas imaginé) ;
- votre solution propose une réponse simple, concrète, testable ;
- vous pouvez embarquer des early users dès la première version.
💡 Si vous êtes à ce stade, c’est possible de partir avec nous sur une phase courte, ciblée, pour valider le produit avant d’engager du développement.
1. Comprendre le vrai problème à résoudre
La tentation est forte de commencer un projet avec une liste de features. Mais une feature list n’est ni une vision produit, ni une stratégie. Encore moins une réponse utile à un vrai problème.
Chez Yield, on commence autrement : par le terrain - mais pas forcément un open space ou une réunion de cadrage. Le terrain, c’est aussi ce que vos utilisateurs essaient déjà de faire, avec ou sans vous.
Retour d’XP :
“Sur le projet Mémo de Vie, on ne partait pas d’un brief fonctionnel mais d’un constat terrain : des victimes de violences n’avaient aucun outil simple et sécurisé pour stocker des preuves au fil du temps.
L’équipe a mené des entretiens avec des associations, des psychologues, des juristes, pour comprendre ce que "garder une preuve" voulait vraiment dire au quotidien.
Résultat : pas de demande de “drive sécurisé” ou de “messagerie chiffrée”. Mais un besoin clair : “Quand je vis un événement violent, je veux pouvoir l’enregistrer discrètement et le conserver dans un espace auquel je pourrai accéder plus tard, en sécurité.”
C’est ce type de besoin réel, formulé en situation, qui structure toute la suite. Pas une idée floue. Un usage ancré.
Pour structurer les besoins et éviter les biais, on s’appuie sur le cadre des Jobs To Be Done : “Quand je fais [situation], je veux [objectif] pour [bénéfice attendu]”.
L’objectif de cette phase : construire un produit qui résout un problème qui compte - pas juste cocher une checklist de features.
2. Cadrer avec une vision produit claire
Une fois le vrai problème identifié, l’erreur serait de foncer sur la solution. Ce qu’on pose ensuite, c’est une vision produit. Pas une “liste de fonctionnalités à développer”.
Retour d’XP :
“Après avoir cartographié les parcours et défini les Jobs To Be Done sur TKcare, on a pu formuler une vraie proposition de valeur : fluidifier la relation RH / intérimaire, avec un espace unique et sécurisé.
Cette vision, on l’a formalisée dans un Lean Canvas, avec la cible, la promesse, la North Star Metric (‘missions validées sans friction’)… et elle a guidé tous les arbitrages par la suite.
On ne développait pas des ‘features RH’. On construisait un produit qui allait simplifier la vie de deux utilisateurs très différents - et ça change tout.”
Tout ça tient dans un document de cadrage qu’on appelle boussole produit. C’est le guide de chaque décision produit tout au long du projet.
Pourquoi c’est essentiel ? Sans vision claire, les specs dérivent. Chaque demande semble urgente. Et le backlog devient une to-do list sans cap.
Avec une boussole solide, on sait dire non. On priorise. On découpe. On livre ce qui a vraiment un impact.
3. Prioriser par la valeur, pas par l’intuition
Un backlog ne vaut rien s’il n’est pas trié. Et dans beaucoup de projets, ce tri est fait… à l’intuition. Ou à la pression hiérarchique.
Chez Yield, on remplace l’arbitraire par une méthode : la priorisation par la valeur.
Avec le client, on co-construit une matrice valeur / effort. Chaque feature est scorée sur 4 critères :
- Reach : combien d’utilisateurs concernés ?
- Impact : à quel point ça change leur quotidien ?
- Confidence : à quel point on est sûrs de l’impact ?
- Effort : temps, complexité, dépendances techniques.
👉 On en détaille l’application dans notre article sur la construction d’une roadmap utile.
Ce scoring est particulièrement utile dans les contextes SaaS : faut-il investir dans un module de paiement multidevise ? Déployer un plan freemium ? Proposer du multi-tenant dès la V1 ?
Une bonne priorisation, c’est aussi refuser les fausses bonnes idées. Ce qui est simple à faire, mais inutile. Ce qui est demandé fort, mais utilisé par 2 personnes.
On ne livre pas ce qu’on peut coder vite. On livre ce qui fait progresser le produit.
4. Découper en fonctionnalités testables (et livrer une V1 utile)
Chez Yield, on ne cherche pas à “tout livrer d’un coup”. On vise une V1 utile, testable, axée sur un parcours prioritaire qui permet déjà de générer de la valeur - ou de valider une hypothèse business.
C’est la logique du slicing vertical : livrer un petit nombre de fonctionnalités… mais utilisables de bout en bout, par des utilisateurs réels.
Exemple :
Sur un SaaS B2B d’automatisation comptable, la V1 livrée en 6 semaines comprenait :
- l’import manuel d’une facture ;
- la génération automatique d’une écriture ;
- et son export au format comptable.
Pas de SSO. Pas de dashboards personnalisés. Pas d’intégration bancaire.
Mais un vrai flux testable, utilisé par 4 clients pilotes - et validé dès la 2e semaine.
👉 On livre un produit exploitable, qui permet de récolter du feedback immédiatement, d’identifier les vraies frictions, et de prioriser la suite sur du concret.
Le slicing vertical, c’est ça : livrer moins, mais livrer juste. Pour tester, ajuster, avancer.
Chez Yield, livrer vite un MVP testable n’est pas un exploit. C’est notre mode opératoire.
Quelques exemples de MVP livrables en 6-8 semaines :
- Portail logistique B2B : création de commande, suivi de statut, tableau de bord client — MVP réaliste livrable en 6–7 semaines selon nos standards.
- SaaS de gestion d’abonnements : onboarding client, configuration de plan tarifaire, génération automatique de facture - MVP livrable en 6–8 semaines avec la bonne stack et un périmètre bien découpé.
- Plateforme de formation : création de compte, accès à une première capsule de contenu, score utilisateur - MVP testable dès la semaine 2, livrable en 6 semaines.
👉 Dans tous les cas, la logique est la même : slicing vertical, parcours testable complet, feedback utilisateur dès la semaine 2.
5. Impliquer les utilisateurs dès le jour 1
Un bon produit ne se conçoit pas “pour” les utilisateurs. Il se construit avec eux.
Dès les premières semaines, on implique des utilisateurs réels dans les itérations. Pas pour faire joli. Pour valider ou invalider les choix faits.
Sur le projet de SaaS comptable, les premiers clients pilotes ont été sollicités :
- pendant la phase de discovery, pour expliciter leurs irritants récurrents ;
- dès la V1, pour tester le flux import → écriture → export ;
- et toutes les 2 semaines ensuite, via des démos ciblées.
Ce qu’on observe dans ces phases ? Des comportements inattendus. Des micro-frictions invisibles dans les specs. Des besoins critiques qui n’avaient jamais été formulés.
Chez Yield, une feature n’est jamais “terminée” tant qu’elle n’est pas testée en conditions réelles, comprise et utilisée sans friction, et adoptée par les vrais utilisateurs.
C’est ce feedback, itératif et immédiat, qui transforme une V1 fonctionnelle… en produit digital durable.
6. Livrer sans stress grâce à une mise en prod progressive
Mettre une app en ligne ne devrait jamais être un moment de panique. Chez Yield, c’est une routine. Parce que tout est pensé pour déployer souvent, proprement, sans surprise.
Sur le SaaS d’automatisation comptable, les premières versions ont été déployées avec :
- des feature flags : certaines fonctionnalités visibles uniquement pour les testeurs early access ;
- des canary releases : déploiement par lots de clients pour observer les comportements sans tout casser ;
- un pipeline CI/CD versionné, testé, monitoré.
👉 Ces techniques, on ne les utilise pas “quand on a le temps”. On les installe dès le premier sprint. Elles permettent de livrer vite, sans prise de risque, d’activer ou désactiver une feature à chaud, et de détecter un bug critique en 2 minutes - pas en 2 jours.
Résultat : une mise en prod n’est plus un “moment critique”. C’est juste une étape naturelle du cycle produit.
7. Travailler en co-pilotage produit / tech / design
Un produit SaaS ne peut pas être “commandé” par le métier, “designé” à part, puis “développé” en bout de chaîne. Ce schéma en cascade crée des incompréhensions, des tensions, et des mauvais arbitrages.
Chez Yield, on structure chaque projet autour d’un trio décisionnel stable dès le départ :
- Product Manager pour fixer le cap, prioriser, challenger les demandes ;
- Lead Developer pour anticiper la dette, sécuriser la stack, organiser le delivery ;
- UX/UI Designer pour garantir l’ergonomie, la fluidité des parcours, l’adoption.
👉 Ces trois-là travaillent ensemble, tout le temps. Pas en séquence. Pas en silos.
Ce mode de collaboration réduit drastiquement les “mauvaises surprises”. Pas de design impossible à dev. Pas de dev hors sujet. Pas de feature inutilisable côté utilisateur.
Résultat : des décisions prises au bon moment, par les bonnes personnes, et des fonctionnalités qui avancent… sans ping-pong interminable.
8. Installer une culture d’amélioration continue (et itérer vite sur la V1)
La mise en production, ce n’est pas la fin. C’est le début du vrai travail. Un bon produit SaaS ne se fige pas après la V1 — il évolue en permanence, guidé par l’usage réel.
Chez Yield, on installe une culture d’itération continue dès les premiers jours de prod. Concrètement, ça veut dire :
- Monitoring technique actif dès le jour 1 : crashs, lenteurs, erreurs serveur, performances par device ;
- Analyse d’usage en continu : taux d’activation, features ignorées, parcours abandonnés ;
- Feedback terrain en boucle courte : support utilisateur, entretiens flash, friction réelle remontée vite.
Et surtout : on suit les KPIs définis dès le cadrage - qu’il s’agisse de taux de rétention, de fréquence d’usage, ou d’activation d’une fonctionnalité clé.
Toutes les 4 à 6 semaines, on mène une rétrospective produit : ce qui fonctionne vraiment (pas juste “ce qui est codé”) / ce qui doit être corrigé ou supprimé / ce qui mérite d’être accéléré.
Exemple terrain :
- Semaine 1-4 : MVP livré (création de commande + validation)
- Semaine 5 : friction remontée sur la validation
- Semaine 6-7 : amélioration design + technique
- Semaine 8 : ajout d’une fonctionnalité clé (export, reporting…)
👉 Ce rythme-là, c’est ce qui transforme un MVP fonctionnel en produit SaaS robuste, monétisable et utilisé.
Conclusion - Pas une méthode de plus. Celle qui fait grandir votre produit.
Un projet de développement web ne devrait pas être une course à la livraison. Ce qui compte, ce n’est pas ce qui est en ligne à la fin du sprint 8. C’est ce qui est utilisé à la semaine 12. Ce qui évolue à la semaine 20. Ce qui génère de la valeur à la semaine 40.
Chez Yield, on ne vend pas une “recette agile”. On structure un cadre robuste, outillé, itératif - pour faire émerger un vrai produit digital. Utilisable, utilisé, évolutif.
- On part du terrain, pas du fantasme de la roadmap.
- On découpe par valeur, pas par complexité.
- On livre une V1 vite, mais utile.
- On itère sur de l’usage réel, pas sur des post-its.
- On pense produit SaaS, pas MVP jetable.
Et surtout : on reste là après la mise en prod. Pour suivre, corriger, renforcer, faire croître.
Vous ne cherchez pas une prestation. Vous cherchez un produit qui tient. Pas une app figée. Un actif digital qui vit.
C’est exactement ce que permet notre cadre en 8 étapes. Et c’est ce qu’on fait - de la première interview utilisateur au suivi de la V3.

Le projet avait pourtant bien démarré. Un brief propre. Un budget validé. Une “agence web” recommandée par le marketing.
Trois mois plus tard ? Une maquette léchée… mais aucun MVP testable. Pas d’authentification SSO. Zéro intégration au SI. Et une équipe métier qui commence à douter sérieusement de la suite.
Que vous soyez responsable marketing, DSI ou chef de projet digital, ce scénario fait partie des cauchemars que vous redoutez.
Il illustre ce qui arrive quand on confond une agence de développement web avec une “agence web” tout-venant – et c’est exactement le sujet du jour : quelles différences entre les deux, et comment éviter de reproduire ce fiasco ?
L’agence web classique : utile, mais pas adaptée aux projets complexes
Historiquement, l’agence web est née pour répondre à des besoins de communication digitale. Elle conçoit des sites vitrines, des interfaces e-commerce simples, des landing pages optimisées SEO. Son cœur de métier : rendre visible, créer une présence en ligne, valoriser une marque.
Côté techno, ça se traduit par l’usage de CMS clés en main (WordPress, Shopify, Webflow), avec des thèmes customisés, des plug-ins, un peu d’intégration front. Le tout piloté par des profils gestion de projet, design et intégration.
👉 Pour un site vitrine, une campagne produit, un blog performant : c’est efficace.
Mais dès qu’on entre dans un projet plus ambitieux - une plateforme, une app connectée, un outil interne complexe - les limites apparaissent :
- Pas de cadrage produit.
- Pas d’architecture logicielle.
- Peu ou pas de logique d’intégration avec des systèmes tiers (ERP, CRM, APIs internes).
- Aucune industrialisation du delivery (tests, CI/CD, sécurisation des mises en prod).
Le risque, ce n’est pas une mauvaise exécution. C’est un mauvais cadre de départ, parce que l’agence ne parle pas le même langage que le projet.
Elle livre une interface, pas un produit. Elle gère un projet, mais ne pilote pas une roadmap.
Ce n’est pas un problème de compétence. C’est une question de posture, de méthode, et de profondeur d’exécution.
L’agence de développement web : une Digital Factory externalisée
Là où l’agence web classique livre un site, l’agence de développement web conçoit un produit digital. Pas une interface figée, mais un système vivant : connecté, itératif, sécurisé, maintenable.
Ce type d’agence intervient quand il ne s’agit plus seulement d’être “présent en ligne”, mais de résoudre un vrai problème métier via la technologie. Créer une plateforme sur-mesure, une application à usage interne, un SaaS B2B, un outil client connecté à votre SI.
👉 Le positionnement change : on quitte la logique de projet isolé pour entrer dans une logique de co-pilotage produit.
Ce que l’agence apporte :
- Cadrage et Product Discovery avec les équipes métier (UX research, ateliers, spécifications dynamiques)
- Product Management externalisé : priorisation, roadmap, arbitrage de valeur
- Architecture logicielle moderne : microservices, cloud-native, Kubernetes, serverless
- Intégration SI : ERP, CRM, APIs internes, SSO…
- Méthodologie MVP + slicing vertical : livrer rapidement une version testable
- Delivery industrialisé : CI/CD, tests automatisés, feature flags, monitoring, MEP progressive
Et surtout : une équipe qui ne se contente pas d’exécuter, mais qui challenge, structure, sécurise. Un partenaire qui a l’habitude de construire des produits dans la durée - et qui a industrialisé ce savoir-faire.
C’est ce que défendent aujourd’hui les meilleurs studios tech et les références du marché : la Digital Factory externalisée.
Les piliers méthodologiques d’une agence de développement web experte
La vraie différence ne se joue pas dans la stack, ni dans la taille de l’équipe. Elle se joue dans la méthode. Dans la capacité à structurer un delivery produit rigoureux, piloté, mesurable.
Voici les piliers qui transforment un projet en produit.
Une vision produit qui aligne tout le monde
Dès le cadrage, l’agence pose un cap. Pas une liste de fonctionnalités, mais une North Star Metric claire, un objectif business assumé, et des utilisateurs bien identifiés.
Tout est structuré autour de ça : les choix techniques, les priorisations, le rythme de delivery.
👉 C’est ce qu’on pose dans la phase de cadrage décrite dans cet article sur la roadmap produit.
Mais une bonne vision produit, ce n’est pas qu’un cap à long terme : c’est aussi un cadre mesurable. On formalise des objectifs clairs et actionnables.
Et pour que la vision tienne dans le temps, encore faut-il qu’elle soit partagée. D’où l’importance d’impliquer les bons interlocuteurs dès le départ.
Une priorisation pilotée par la valeur, pas par l’intuition
Dans les projets mal cadrés, le backlog devient vite un cimetière de features. Tout semble “prioritaire”, personne ne tranche, et l’équipe avance à l’aveugle.
Dans une agence structurée, la priorisation repose sur des critères objectifs :
impact utilisateur, valeur métier, effort réel, risques. On utilise des méthodes comme RICE pour scorer, comparer, arbitrer - en lien direct avec les enjeux du terrain.
👉 C’est ce qu’on pose dès les premiers ateliers de roadmap, où chaque item est challengé, classé, assumé. On vous montre comment organiser cette priorisation dans cet article.
L’objectif : livrer ce qui crée de la valeur, pas juste ce qui est demandé. Et garder une équipe alignée - parce qu’elle sait pourquoi elle livre ce qu’elle livre.
Un MVP découpé intelligemment, testable rapidement
Un bon MVP ne couvre pas “tout”. Il couvre juste assez pour tester la promesse - sur un parcours utilisateur complet, exploitable dès les premières semaines.
C’est là que la méthode change tout. Une agence experte ne découpe pas le périmètre en blocs techniques (auth, back-office, API…), mais en slicing vertical : un enchaînement d’écrans, de règles métier et de traitements qui permettent de valider un vrai usage, dans un vrai contexte.
L’objectif n’est pas de cocher des specs, mais de mettre un produit entre les mains des utilisateurs, et d’observer. Pas dans six mois. Dans six semaines.
Des utilisateurs métiers intégrés dans le cycle
Un bon produit n’est pas “validé” par les métiers à la fin. Il est co-construit avec eux tout au long du projet : entretiens, tests, feedback sur les versions intermédiaires, arbitrages live.
L’agence installe cette collaboration comme un réflexe.
👉 On détaille cette approche dans notre article comment définir les parties prenantes et les besoins utilisateurs
Une vraie culture d’apprentissage post-livraison
Livrer n’est pas l’objectif. Faire évoluer le produit en continu, si.
Une agence experte installe le suivi des KPIs dès la mise en prod, détecte les usages réels, et sait itérer sans tout casser.
👉 On vous explique comment suivre l’usage réel dans suivre l’adoption d’un logiciel métier.
Agence web vs agence de développement web : le tableau différenciateur
Deux types d’agences. Deux niveaux d’exécution. Deux visions du digital.
Résumons les différences clés - en livrables, en méthode, en capacité d’intégration, en time-to-market.

👉 Si vous avez un vrai enjeu produit, ce tableau suffit à trancher. L’alignement de la méthode avec la complexité du projet, c’est ça, le vrai critère de choix.
Quand faire appel à une agence de développement web ?
Pas besoin d’une Digital Factory pour lancer un site vitrine. Mais dès que le projet implique de la complexité, de la scalabilité ou de la valeur métier, le bon partenaire change.
Vous construisez un produit digital structurant
Plateforme métier, outil collaboratif, app B2B, portail client… Ce ne sont pas des sites, ce sont des produits vivants, avec des logiques d’usage, d’itération, de support et de scalabilité.
👉 Ils demandent une méthode, pas juste une exécution.
Vous devez interfacer le produit avec votre SI
ERP, CRM, référentiels internes, système de login, SSO… Une agence web classique ne gère pas ce niveau d’intégration. Tandis qu'une agence dev vous accompagne sur les schémas d’architecture, les APIs, les cycles d’interopérabilité.
Vous visez un MVP rapide, testable, évolutif
Le projet ne doit pas durer 9 mois. Il doit être utilisable vite, mesurable, itératif. L’approche MVP + slicing vertical permet de livrer un parcours complet testable dès les premières semaines.
Votre projet implique des enjeux techniques sérieux
Architecture scalable, sécurité, performances, déploiement… Ici, il faut un partenaire qui maîtrise les fondamentaux : DevSecOps, CI/CD, tests auto, cloud-native.
Vous cherchez à industrialiser votre delivery digital
Le but n’est pas de “livrer un projet”. C’est de poser les bases d’un produit qui pourra évoluer, se maintenir, s’itérer. Une agence de développement, c’est aussi une Digital Factory externalisée.
Conclusion - Deux visions du web, deux niveaux de jeu
Une agence web, c’est le bon partenaire pour exister en ligne. Créer un site, une présence, un support de communication.
Mais dès qu’il s’agit de construire un produit digital, avec des enjeux de delivery, d’usage, d’intégration ou de scalabilité, il faut un tout autre niveau de structuration.
L’agence de développement web, c’est plus qu’un prestataire technique. C’est un co-pilote produit. Un accélérateur de delivery. Un expert de la qualité logicielle. Et un garant de l’industrialisation de votre capacité digitale.
Si votre ambition est de créer une application web robuste, utile, et évolutive…
vous avez besoin d’une agence de développement logiciel. Pas d’une simple agence web.

Un jeudi matin, en comité de pilotage, le CTO lâche : “On a déjà cramé 60 % du budget, et on n’a toujours pas de version utilisable.” Silence. Les specs ont changé trois fois. L’équipe interne est sous l’eau. Le freelance principal est parti sur une autre mission. Et personne ne sait vraiment si le produit répond encore au besoin métier de départ.
Ce genre de situation, on le voit souvent chez Yield. Pas parce que les équipes sont mauvaises. Mais parce que construire une application web en 2025, ce n’est pas juste du code. C’est un mélange de discovery produit, d’architecture cloud, de gestion du delivery, de sécurité, de scalabilité… et de décisions à prendre vite.
👉 C’est là que le choix d’un partenaire change tout. Pas une “agence web” qui empile les features. Une équipe produit-tech qui sait cadrer, prioriser, livrer - et surtout, industrialiser la réussite.
On vous montre pourquoi faire appel à une agence experte vous permet de sécuriser vos projets, d’accélérer le delivery et de construire un produit qui tient la route. Pas juste une app de plus.

L’accès immédiat à une expertise pointue
Construire un logiciel métier aujourd’hui, c’est devoir trancher très vite entre :
- une architecture scalable ou non ?
- serverless ou conteneurisé ?
- headless CMS ou framework custom ?
- quelle stack pour intégrer de l’IA sans bricoler un POC bancal ?
La réalité : peu d’équipes internes ont ce recul — surtout quand elles sont absorbées par la maintenance, les projets en cours, ou les impératifs du quotidien.
👉 Faire appel à une agence spécialisée, c’est court-circuiter la phase de tâtonnement.
Pas besoin de six mois de R&D interne pour comprendre comment intégrer un LLM via LangChain ou mettre en place une archi cloud-native en multi-environnement sécurisé : l’expertise est déjà là, industrialisée.
Une bonne agence ne se contente pas de livrer du code. Elle apporte un regard critique sur l’ensemble du produit :
- Comment découper les modules pour scaler sans exploser les coûts ?
- Comment anticiper les sujets de sécurité, d’audit, de conformité (RGPD, ISO, etc.) ?
- Comment construire une stack qui tient la route à 200 utilisateurs… comme à 10 000 ?
Ces sujets doivent être posés dès la phase de définition de l’architecture technique - on l’a détaillé dans notre article sur la préparation au développement.
C’est aussi un gain côté produit. Discovery, priorisation par la valeur, user research, arbitrage des features : vous accédez à des profils qui maîtrisent autant le delivery que la stratégie. Des gens qui savent dire non, avec des arguments.
Résultat ? Des choix techniques solides, des décisions structurantes prises dès le départ, et un produit qui évite les impasses.
Retour d’XP :
Une scale-up B2B venait de recruter son premier lead dev. Il gérait déjà la refonte du SI, l’onboarding des juniors, les incidents en prod… Impossible pour lui de tester sereinement une nouvelle stack cloud + IA. En 2 semaines, notre équipe a cadré un socle technique modulaire avec intégration RAG, POC validé et plan de montée en charge. Le tout en mobilisant une stack éprouvée, avec une infrastructure et des outils prêts à l’emploi.
Une méthodologie ultra structurée et éprouvée
Un bon produit ne naît pas d’un brief. Il se construit dans la clarté, la rigueur et les bons arbitrages au bon moment.
Chez Yield, on voit passer beaucoup de projets qui ont échoué… non pas faute de moyens, mais faute de méthode. Pas de vision produit alignée. Pas de découpage clair. Pas de priorisation par la valeur. Résultat : un tunnel de dev, des features inutilisées, et une équipe qui s’épuise.
👉 Une agence sérieuse n’improvise pas sa façon de faire. Elle applique une méthodologie industrielle, éprouvée sur des dizaines de projets.
Ça commence dès le jour 1 :
- On cadre une vision produit claire et partagée, avec les parties prenantes clés.
- On co-construit le périmètre avec le trio Produit / Tech / Design à la même table.
- On découpe par slicing vertical : pas des specs techniques en cascade, mais des parcours utilisateurs complets, testables à chaque sprint.
- On priorise les livrables avec des méthodes comme RICE : valeur métier, impact utilisateur, complexité réelle.
Le tout orchestré avec un backlog vivant, des rituels agiles tenus (vraiment), et un focus constant sur l’impact produit — pas juste le delivery.
Ce que vous gagnez : un produit construit au bon rythme, des fonctionnalités utiles livrées vite, et une équipe qui reste alignée dans la durée.
Retour d’XP :
Sur un projet dans l’assurance, le client pensait avoir “tout spécifié” en amont. Résultat : 180 pages de specs… et zéro vision produit. On a repris le sujet en discovery, clarifié les priorités avec l’équipe métier, appliqué une logique de découpage par valeur métier. En 3 semaines, un MVP clair était cadré, avec une roadmap réaliste sur 3 mois. Ce qu’il manquait, ce n’était pas du temps ou du budget. C’était une méthode.
Une réduction maximale des risques
Un projet logiciel peut déraper vite. Un changement de spec mal anticipé. Une mise en prod qui casse l’existant. Un usage qui stagne après la release. Et tout le monde se retrouve à éteindre des incendies, au lieu de créer de la valeur.
👉 La vraie différence entre une équipe artisanale et une équipe structurée, c’est la gestion proactive du risque.
Une agence sérieuse sécurise chaque étape du delivery :
- Feature flags pour activer / désactiver les modules sans impacter toute la prod.
- Canary releases pour déployer progressivement, observer les impacts, corriger à chaud.
- Blue-green deployment pour basculer sans rupture.
Côté qualité, les pipelines de CI/CD tournent en continu. Les tests sont automatisés, versionnés, intégrés dès le début. Pas en mode “on testera après quand ce sera stable”. On a détaillé ces pratiques dans notre article sur les tests et le monitoring.
Et après la mise en production ? Le suivi continue : taux d’adoption, usage réel, retours terrain, tickets support. Pas juste “c’est en ligne” - mais “ça marche, ça sert, ça évolue”.
Résultat ? Moins de bugs critiques, moins d’effet tunnel, plus de sérénité pour vos équipes internes. Et surtout : un produit qui peut grandir sans se fragiliser.
Retour d’XP :
Sur un projet e-commerce B2B, la première mise en production a été stoppée net par une régression non détectée côté API. Pourquoi ? Les tests étaient là, mais non maintenus. Depuis, chaque sprint inclut une passe QA systématique, des tests de non-régression versionnés, et des canary releases sur environnement miroir. Plus aucun incident bloquant depuis 6 mois.
L’accélération du time-to-market
Un produit qui met 9 mois à sortir sa première version a déjà un pied dans l’échec.
Les attentes ont changé. Les users sont passés à autre chose. L’équipe est usée. Et le business n’a rien à montrer.
👉 Une agence produit-tech, c’est aussi une machine de delivery bien huilée, capable de livrer vite — mais propre.
Concrètement :
- Une équipe opérationnelle prête en quelques jours, avec les bons outils, les bons rituels, les bons réflexes.
- Une first usable version en 4 à 6 semaines, testable par les utilisateurs métiers. Pas une maquette figée, un vrai produit. On pose les bases dès la phase de prototypage interactif - comme on l’explique ici.
- Un rythme de sprint soutenu, avec des releases toutes les 2 à 3 semaines, pas tous les trimestres.
Et surtout : une capacité à intégrer les feedbacks rapidement. Pas dans 6 mois. Pas “pour la V2”. Mais dès la prochaine itération. On teste, on ajuste, on pivote si nécessaire - sans remettre tout à plat.
À la clé : un produit vivant, visible, qui progresse sous les yeux des parties prenantes. Et une capacité à convaincre vite - en interne comme en externe.
Une industrialisation complète du delivery
Un bon produit, ce n’est pas un one-shot. C’est une capacité à délivrer de la valeur métier de façon répétée, structurée, prévisible.
C’est exactement ce que permet une agence qui fonctionne en mode digital factory externalisée : une équipe stable et dédiée, des fondations tech solides et une organisation orientée delivery continu.
Concrètement, ça veut dire quoi ?
- Un socle cloud partagé (infra, CI/CD, monitoring, sécurité) pour aller vite sans réinventer.
- Des assets logiciels mutualisables : composants UI, briques d’auth, modules de notification…
- Une gouvernance claire : budget piloté, backlog outillé, roadmap par palier.
- Et surtout : une capacité à s’intégrer finement dans votre SI (ERP, CRM, outils internes), sans tout casser.
On ne parle pas ici d’un prestataire qui livre une app. On parle d’un partenaire qui construit avec vous un système de delivery robuste, modulaire, capitalisable.
Et plus vous avancez, plus vous gagnez en autonomie - avec des fondations qui vous permettent de lancer d’autres produits, sans repartir de zéro. Encore faut-il maintenir ces fondations dans le temps - on l’aborde dans notre article sur la dette technique et la maintenabilité.
Conclusion - Une agence, oui. Mais une vraie.
Faire appel à une agence produit-tech, ce n’est pas déléguer un projet. C’est structurer votre capacité à livrer un logiciel utile, utilisé et maintenable dans le temps.
Vous gagnez :
- une expertise pointue, pour faire les bons choix techniques et produits dès le départ ;
- une méthodologie éprouvée, pour prioriser, découper et livrer sans friction ;
- un delivery rapide, sécurisé, mesuré, piloté par l’usage et les retours métier ;
- et surtout : une approche industrialisée, pensée pour durer — pas juste pour livrer une V1.
La vraie différence, elle est là. Une agence “prestataire” code ce qu’on lui demande. Une agence “accélérateur de réussite produit” co-construit, challenge, et délivre de la valeur métier.
À vous de choisir ce dont votre projet a vraiment besoin.

Un décideur pose la question : “Pourquoi ça fait 6 mois qu’on développe… et qu’on n’a rien à montrer ?” C’est souvent là que le malaise commence.
Pas parce que l’équipe est incompétente. Mais parce que le projet s’est perdu dans les specs, les chantiers parallèles, les allers-retours de validation — et qu’on a oublié l’essentiel : le bon logiciel, ce n’est pas celui qui fait tout, c’est celui qui résout un vrai problème.
Chez Yield, on a vu passer des dizaines de projets qui patinaient… alors que les ingrédients étaient là : une équipe engagée, un budget solide, un objectif métier clair.
Ce qui manquait ? Un fil rouge. Une méthode. Une manière de construire pas à pas — avec du bon sens, et du feedback.
👉 Ce guide, c’est exactement ça : 8 étapes simples, concrètes, pour construire un logiciel métier qui sert vraiment. Pas un tunnel de dev. Pas une app “concept”. Un produit utile, piloté, livré, utilisé.
Prêt à construire mieux ? Let’s go.
Étape 1. Partir d’un vrai problème utilisateur, pas d’une intuition interne
Une bonne app ne commence pas par une to-do list de features. Elle commence par un irritant terrain, vécu, répété — que personne n’a encore bien résolu.
Avant de parler maquette ou stack technique, il faut répondre à une seule question :
👉 Quel problème concret on cherche à résoudre, pour qui, dans quel contexte ?
Et ça, on ne l’obtient pas dans une salle de réunion. On l’obtient :
- en posant des questions ouvertes aux utilisateurs (sans chercher à valider une idée) ;
- en observant leurs gestes et les contournements qu’ils ont mis en place (“je fais un copier-coller dans Excel, puis j’envoie un mail à Lucie…”) ;
- en formulant clairement le besoin sous forme de Job To Be Done (JBTD) :
“Quand je fais [situation], je veux [objectif] pour [bénéfice attendu].”
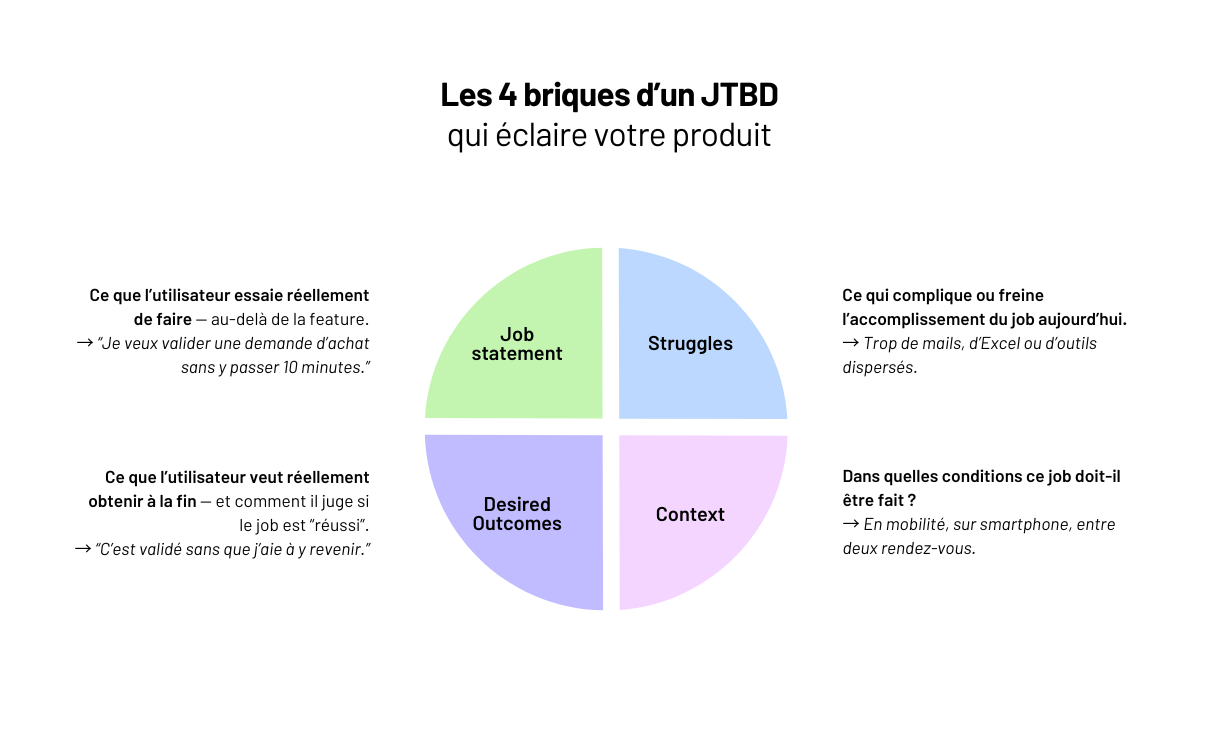
Sans ce travail, on développe un outil “intéressant”… mais pas nécessaire. Et c’est le meilleur moyen de se retrouver avec une app qui tourne — mais que personne n’utilise.
Ce qu’on pose chez Yield, dès la phase d’amorçage : un cadrage centré usage, pas fonctionnalités. Parce qu’un logiciel utile, c’est d’abord un logiciel qui résout quelque chose de tangible.
💡Pour bien formuler le problème à résoudre, rien ne remplace l’observation terrain. On détaille notre méthode pour identifier les bons irritants métier dans cet article sur l’analyse du travail des équipes.
Étape 2. Travailler avec une vision produit claire et partagée
Une vision produit, c’est un cap partagé, qui éclaire les décisions et aligne les équipes. Sans elle, on avance à vue. Avec elle, chaque choix trouve sa logique.
Une direction claire, pas un patchwork de besoins
Un bon logiciel métier ne naît pas d’un besoin exprimé par une équipe isolée. Il prend racine dans une vision claire — une direction que tout le monde comprend, partage… et peut challenger.
Sans cette vision, on finit vite avec un backlog qui grossit sans cap, un produit qui évolue par ajouts successifs, et des arbitrages flous entre ce qui est “urgent”, “important”, ou juste “bruyant”.
👉 Une vision produit bien posée, c’est :
- Un cap business : pourquoi on lance ce logiciel ? Quel impact attendu sur l’organisation ?
- Une cible utilisateur : pour qui on le construit — et quels irritants on cherche à résoudre en priorité ?
- Une North Star claire : un indicateur simple qui dit si on avance dans la bonne direction (ex. : % de demandes traitées sans relance, temps moyen entre deux étapes clés…).
Une boussole produit, vivante et activée
Chez Yield, on aime formaliser cette vision sous forme de “boussole produit” dès les premières semaines. Pas pour faire joli. Mais pour avoir un document court, concret, que chaque équipe peut relire quand il faut trancher : “est-ce que cette évolution nous rapproche — ou nous éloigne — de notre but ?”
Et cette vision ne reste pas figée dans un coin de Notion. On la réactive à chaque sprint planning, à chaque rétro, à chaque discussion stratégique. Parce qu’un produit bien piloté, c’est un produit qui sait pourquoi il existe — et pourquoi il évolue.
💡Une bonne vision produit repose aussi sur des objectifs mesurables et partagés. On vous montre comment les définir efficacement dans cet article sur les bons objectifs produit.
Une vision alignée sur la réalité terrain… et technique
Une vision produit solide, c’est aussi une vision lucide sur l’environnement technique. Un logiciel métier ne vit jamais en silo : il s’insère dans un écosystème existant — souvent avec un ERP, un CRM, un outil maison.
Ces interconnexions sont rarement “plug and play”. Si on ne les identifie pas dès le départ, elles deviennent des freins imprévus : données manquantes, flux à reconstruire, dépendances mal anticipées.
👉 C’est pour ça qu’on pose très tôt chez Yield une cartographie des systèmes existants et des flux critiques. Pas pour faire de l’archi pour l’archi. Mais pour faire des choix réalistes — et éviter les plans sur la comète qui explosent à l’intégration.
Étape 3 – Prioriser par la valeur, pas par la facilité technique
Un bon backlog, ce n’est pas une to-do list géante. C’est une matrice de décision. Chaque ticket, chaque idée, chaque “ce serait bien de…” doit passer au filtre de la valeur métier. Sinon, vous risquez de livrer ce qui est rapide… mais pas forcément utile.
👉 L’objectif, c’est de trier. Froidement. Ce qui génère de l’impact utilisateur passe en haut. Ce qui rassure un stakeholder, mais n’apporte rien sur le terrain ? À challenger.
Voici ce que vous devez poser pour prioriser avec méthode et lucidité :
- Une grille de scoring simple : le RICE Score reste une valeur sûre. Il combine portée (Reach), impact, confiance et effort. Et vous force à objectiver chaque critère.

- Une matrice “effort / valeur” visuelle : parfaite en atelier de cadrage ou de grooming. Elle aide à repérer les quick wins, les “faux gros sujets”, et les véritables no-go.
- Un échange régulier avec les utilisateurs métier : ils sont les mieux placés pour dire ce qui compte. Même un sujet techniquement simple peut être perçu comme inutile sur le terrain.
- Une vraie capacité à dire non : la priorisation, ce n’est pas l’art d’empiler, mais celui de renoncer. Si tout est prioritaire, rien ne l’est.
Astuce Yield : lors du sprint planning, testez un “pitch inversé” – chaque feature doit être défendue en 2 minutes chrono : quelle valeur, pour qui, et pourquoi maintenant. Si ça ne tient pas la route, c’est que ce n’est pas mûr.
💡 La priorisation ne se décide pas sur un coin de table. Elle s’ancre dans un travail de cadrage solide, une compréhension des enjeux métiers, et une évaluation réaliste des ressources. On détaille notre méthode dans cet article dédié à la construction de roadmap produit.
Étape 4. Découper intelligemment en fonctionnalités livrables
Livrer un gros bloc après 3 mois de dev, ça fait joli dans un planning. Mais ça ne prouve rien.
Dans une logique produit, ce qu’on cherche, ce n’est pas de “finir un module”. C’est de livrer une première valeur, testable, compréhensible, utile — même si elle est incomplète. Et pour ça, il faut découper plus finement, plus intelligemment.
👉 Un bon découpage, c’est ce qui permet de créer un flux : on livre vite, on apprend vite, on ajuste vite. Et surtout, on réduit drastiquement les risques de déconnexion entre le besoin réel… et ce qui arrive en production.
Voici ce que vous devez poser pour éviter le “tout ou rien” :
- Découpez en User Stories indépendantes. Pas des specs géantes, mais des scénarios utilisateur qui tiennent seuls.
- Livrez des incréments testables. Pas besoin de couvrir tous les cas d’usage au début : une version “premier parcours complet” permet déjà de valider énormément.
- Utilisez le slicing vertical. Plutôt que découper par couches techniques (back, front, design…), découpez par fonctionnalités utilisables. Même simples, elles doivent être testables de bout en bout.
- Gardez un rythme de livraison visible. Si vous livrez toutes les 3 semaines mais que personne ne peut tester, vous perdez l’essentiel : le feedback.
Le découpage, ce n’est pas une étape de specs. C’est un levier de pilotage. Plus vous livrez tôt, plus vous apprenez, plus vous créez de la valeur métier réelle.
💡 Un bon découpage permet aussi de travailler plus intelligemment les maquettes et les tests. On vous montre ici comment transformer un besoin métier en parcours visuel cohérent.
Étape 5 – Intégrer les utilisateurs métiers en continu dans le cycle
Un logiciel métier, ça ne se conçoit pas pour les utilisateurs. Ça se conçoit avec eux.
Les embarquer tôt, c’est éviter les malentendus plus tard. Et poser les bases d’un produit qui trouve vraiment sa place.
Les faire entrer tôt dans le process… vraiment
Si les utilisateurs finaux (souvent issus du métier) découvrent le produit à la fin, c’est déjà trop tard. Les allers-retours s’enchaînent, les incompréhensions s’installent, et ce qui devait “simplifier le quotidien” devient un outil en plus — pas une solution.
👉 Pour éviter ça, il faut intégrer les utilisateurs métier tout au long du développement. Pas en spectateurs, mais comme contributeurs actifs.
Voici ce que vous devez poser pour en faire des alliés plutôt que des testeurs de dernière minute :
- Des rituels partagés : ateliers de cadrage, revues de sprint, démos ciblées… L’objectif n’est pas de “valider”, mais de co-construire.
- Une Definition of Done métier : chaque fonctionnalité n’est pas “terminée” tant qu’elle n’est pas validée par les usages réels.
- Des retours qualifiés, pas anecdotiques : enregistrements de parcours, interviews rapides, verbatims collectés en continu.
- Des binômes produit/métier : sur les sujets critiques, associer un utilisateur clé au PO pour affiner les specs en live.
Chez Yield, on intègre très tôt les retours terrain dans les tickets. Car un bug pour le métier n’est pas toujours un bug technique — c’est parfois juste un manque de clarté.
💡 Pour que l’intégration des utilisateurs soit réellement efficace, il faut savoir à qui parler, et sur quoi les faire réagir. On a détaillé notre méthode pour bien identifier les parties prenantes et leurs vrais besoins.
Préparer l’adoption, pas juste la livraison
Un bon produit n’est pas seulement fonctionnel. Il est compréhensible, adoptable, et utile pour ceux qui le vivent au quotidien. Et ça ne se joue pas uniquement en phase de développement. L’appropriation post-livraison fait partie du projet.
Voici ce que nous mettons en place systématiquement pour favoriser l’adoption terrain :
- Une formation ciblée : format court, concret, adapté au niveau des utilisateurs (démos, pas à pas, cas réels)
- Une documentation utile : accessible, vivante, et intégrée là où les utilisateurs en ont besoin
- Un support lisible : qui contacter, par quel canal, avec quel niveau de réponse attendu
Ce n’est pas un bonus. C’est la dernière ligne droite pour sécuriser l’impact métier réel.
Étape 6. Livrer en production sans prendre de risques
Une mise en production, ce n’est pas un “grand saut” à faire d’un bloc. C’est un processus maîtrisé, où vous séparez clairement le moment où le code est livré… de celui où la fonctionnalité est activée pour les utilisateurs.
👉 Le bon réflexe, c’est de livrer souvent, par petites touches, sans stress — grâce à une stratégie de déploiement progressive.
Voici ce que vous devez mettre en place pour ne pas livrer à l’aveugle :
- Des Feature Flags : vous livrez la fonctionnalité en prod, mais elle reste inactive tant qu’elle n’est pas validée. Idéal pour faire des tests ciblés ou des activations par lot.

- Des Canary Releases : vous activez progressivement la nouvelle version, sur un segment limité d’utilisateurs (5 %, 20 %, 50 %…) pour surveiller les effets et corriger si besoin.
- Du Blue-Green Deployment : deux environnements de prod en miroir. Vous basculez de l’un à l’autre en quelques secondes, en cas de bug critique ou de rollback.
- Des Go/No Go métier : certaines features critiques doivent passer une validation métier avant activation. Pas une formalité — un vrai check opérationnel.
Résultat : vous gardez la main sur ce que voit l’utilisateur, même si le code est déjà en prod. Moins de stress côté équipe, plus de sécurité côté produit.
Ce n’est pas du luxe. C’est ce qui vous permet d’itérer vite… sans exploser la qualité.
💡 Vous voulez éviter les déploiements sous tension ? On vous détaille ici comment concevoir une stratégie de mise en prod progressive, sans effet tunnel.
Étape 7 – Travailler en collaboration fluide entre produit, tech et design
Un bon produit ne sort jamais d’une suite de validations en cascade. Il naît de la co-construction. Et ça, ce n’est pas une question d’outils, mais de posture collective.
👉 Trop d’équipes continuent à fonctionner en silos : le produit rédige une spec, la tech implémente “ce qui est possible”, le design ajuste a posteriori. Résultat ? Des tensions, des itérations dans le vide, et une perte de sens.
Chez Yield, on recommande une organisation centrée sur un trio clé, impliqué ensemble du cadrage à la livraison :
- Le Product Manager porte la vision et le cap : pourquoi on fait, pour qui, et avec quel impact attendu.
- Le Lead Dev garantit la faisabilité, anticipe les contraintes techniques et porte la qualité long terme.
- Le Designer traduit l’intention produit en expérience fluide, testable, compréhensible par l’utilisateur final.
Ce trio doit intervenir dès les premières phases (cadrage, atelier d’impact, arbitrage des MVPs), pas seulement au moment de “produire”.
Pour rendre cette collaboration fluide, vous pouvez mettre en place :
- Un rituel de kick-off commun pour chaque sprint ou nouveau sujet ;
- Un refinement croisé, où produit, tech et design challengent ensemble les specs et l’impact attendu ;
- Une présentation des choix UX/UI à chaud, avant que le dev n’ait commencé à coder une feature qui ne tiendra pas la route.
Un bon indicateur : si votre développeur découvre le design dans le ticket Jira, ou si votre designer ne comprend pas pourquoi “ça a été développé comme ça”… il est temps de revoir vos circuits.
💡 Chez Yield, on pense que le trio Produit / Tech / Design doit être structuré dès le départ. On a formalisé ici les bons réflexes pour fluidifier cette collaboration.
Étape 8 – Installer une vraie culture de l’apprentissage continu
Une app n’est jamais “terminée”. Ce qui fait la différence entre un produit qui stagne et un produit qui progresse, ce n’est pas (juste) le nombre de releases. C’est la capacité à apprendre. Vraiment.
Observer le réel, pas juste le planning
👉 Dans les projets bien pilotés, chaque itération est une opportunité d’améliorer l’expérience utilisateur, de corriger un angle mort, ou d’optimiser les performances.
Mais pour ça, il faut poser un cadre clair, et surtout : rendre l’apprentissage actionnable.
Voici les bonnes pratiques à intégrer dès le départ :
- Monitorer ce qui se passe en prod, sans attendre les retours utilisateurs. Temps de chargement, taux de clic, crashs, erreurs serveur… ce sont vos signaux faibles.
- Structurer les feedbacks : tickets de support, verbatims utilisateurs, entretiens métier. Le but, ce n’est pas de collecter tout — c’est d’identifier ce qui revient, ce qui coince, ce qui ralentit.
- Organiser des temps de recul : au-delà de la rétro dev, une vraie rétro produit toutes les 4 à 6 semaines. Ce qu’on a appris, ce qui mérite d’être challengé, ce qu’on veut tester ensuite.
💡Un produit qui apprend, c’est un produit qui vit. Pour vous aider à suivre l’usage réel et ajuster sans attendre, on a détaillé ici notre méthode.
Poser des KPIs utiles dès le sprint… et au-delà
Une bonne habitude : intégrer 1 KPI d’usage, 1 KPI de perf, et 1 KPI de satisfaction dans chaque sprint. Pas pour “faire joli”, mais pour piloter ce qui compte vraiment.
Mais l’apprentissage ne s’arrête pas à la fin du sprint 12. Un produit qui apprend… c’est aussi un produit qu’on continue d’écouter à M+6, M+12.
Pour ça, on pose des indicateurs de succès long terme dès la conception :
- Des KPIs de récurrence : taux d’usage actif, fréquence par profil, taux de rétention
- Des métriques métier concrètes : gain de temps, baisse des erreurs, fluidité des process
- Des signaux faibles : baisse d’usage, hausse des tickets, contournements qui émergent
Un pic d’usage à la mise en prod, c’est bien. Mais la vraie réussite, c’est un usage régulier, durable, intégré.
En résumé — Les 8 réflexes d’un projet logiciel bien mené
Un bon logiciel n’est pas juste bien codé. Il est pensé pour résoudre un vrai problème, construit avec les bonnes personnes, et livré avec méthode. Voici les 8 réflexes à garder en tête pour faire les bons choix à chaque étape :
- Partir d’un problème utilisateur clair, pas d’une intuition vague. C’est la seule façon de produire de la valeur réelle — pas du fonctionnel vide.
- Travailler avec une vision produit partagée, qui aligne les équipes et guide chaque décision, du premier wireframe au dernier ticket Jira.
- Prioriser par la valeur, pas par la facilité ou la visibilité. C’est ce qui évite la dette fonctionnelle… et le backlog qui enfle sans impact.
- Découper intelligemment les fonctionnalités, pour livrer petit à petit, tester plus tôt, et apprendre plus vite.
- Intégrer les utilisateurs métier dès le départ, dans les ateliers, les tests, les arbitrages. Ils ne sont pas “consultés”, ils co-construisent.
- Soigner la mise en production, en la rendant progressive, pilotée, maîtrisée. Pour livrer sans stress… et sans surprise.
- Faire collaborer produit, tech et design en continu, pas en cascade. C’est le seul moyen d’éviter les silos et les specs hors sol.
- Adopter une vraie culture d’apprentissage, où le produit évolue parce qu’on l’observe, on le challenge, et on l’écoute.
👉 Vous voulez cadrer votre projet logiciel avec méthode, sécuriser vos choix et construire un produit qui délivre vraiment ? Chez Yield, on vous aide à poser des fondations solides — et à les faire grandir sprint après sprint. Parlons de votre projet.

Un matin, un bug. L’app ne s’ouvre plus sur certains Android. Un jour plus tard, un autre : les utilisateurs ne peuvent plus se connecter via Apple ID.
Trois semaines passent. Les notes chutent, les users churnent, et l’équipe produit commence à entendre la question qui fait mal : “C’est normal qu’on n’ait rien prévu pour ça ?”
En 2025, créer une application mobile, c’est bien. Mais la faire vivre, c’est vital.
Trop d’entreprises consacrent 90 % de leur budget à la phase de build… et laissent la maintenance à l’improvisation. Résultat : un produit fragile, des updates qui trainent, des correctifs en urgence, et un vrai coût business — réputation, rétention, sécurité.
👉 Dans cet article, on remet les pendules à l’heure. On vous explique :
- ce que recouvre réellement la maintenance mobile (et ce qu’on oublie souvent) ;
- pourquoi elle est clé pour la performance, la sécurité, et la longévité d’un produit ;
- et comment l’organiser concrètement, pour que chaque mise à jour soit un vrai levier de valeur.
Maintenance, TMA, support produit : peu importe le nom — ce qui compte, c’est de savoir comment vous faites durer votre app.
Maintenance mobile : qu’est-ce que ça recouvre (vraiment)
Développer une application, c’est lancer un produit. La maintenir, c’est le faire vivre.
Et trop souvent, ce qui est perçu comme un “petit poste de dépense annexe” devient en réalité le socle de sa performance à long terme. Car une application mobile n’est jamais “finie” : elle évolue, elle s’adapte, elle doit rester fluide malgré les mises à jour d’OS, les nouvelles attentes des utilisateurs ou les besoins métier qui changent.
👉 La maintenance mobile, ce n’est pas juste corriger des bugs. C’est tout ce qui permet à ton app de rester utile, performante, et bien classée — même 6, 12, 24 mois après la mise en ligne.

Ce que comprend (vraiment) une TMA mobile bien pensée
Pas besoin de tout faire tout de suite. Mais un bon plan de maintenance doit couvrir 6 piliers essentiels. Voici ce qu’on met en place dans 90 % des projets Yield.
Correction des bugs
Des crashs, des comportements inattendus, des lenteurs… une app sans bug, ça n’existe pas. Ce qui compte, c’est :
- la capacité à les identifier rapidement (via monitoring ou retours terrain) ;
- la rapidité de correction ;
- la transparence avec les équipes métier ou les utilisateurs.
Chez Yield, on priorise les anomalies dans un backlog dédié, avec un traitement itératif et une logique de “triage express”.
Sécurité et protection des données
Une app mobile, c’est un point d’entrée sensible. Et plus l’app traite de données critiques (santé, RH, finance), plus la sécurité est non négociable :
- Mise à jour des dépendances critiques ;
- Audits de sécurité réguliers (internes ou via tiers) ;
- Authentification renforcée (2FA, biométrie, etc.) ;
- Logging d’audit pour le RGPD.
Pas besoin d’être une néo-banque pour sécuriser sérieusement : toute app pro ou B2B y est exposée.
Suivi des mises à jour OS
À chaque nouvelle version d’iOS ou d’Android, certaines fonctions cassent, des composants deviennent obsolètes, des designs sautent.
Une maintenance efficace inclut :
- des tests de compatibilité dès les bêtas développeur ;
- des correctifs proactifs pour les mises à jour critiques ;
- un accompagnement dans la validation App Store / Google Play.
Ne pas anticiper ces changements, c’est risquer le rejet du store ou l’instabilité sur les nouveaux appareils.
Monitoring de la performance
Une app lente, instable ou qui plante, ça se désinstalle.
Dès la mise en ligne, il faut monitorer en continu :
- le taux de crash ;
- le temps d’affichage des écrans clés ;
- les parcours abandonnés ;
- les erreurs serveur ou API.
On installe souvent Sentry, Firebase ou DataDog dès la V1 — car les problèmes les plus coûteux sont ceux qu’on ne voit pas venir.
Évolutions fonctionnelles
La TMA ne sert pas qu’à maintenir le périmètre existant. C’est aussi un moyen d’améliorer ton app, petit à petit :
- ajout de features attendues par les utilisateurs ;
- refonte de parcours trop complexes ;
- itérations design ou UX sur la base des feedbacks.
On travaille en lots courts (2 à 4 semaines), pour valider chaque amélioration métier avec les équipes terrain.
Maintenance du backend
Une app mobile ne vit pas seule : elle repose souvent sur une API, une base de données, un dashboard métier.
La maintenance doit aussi inclure :
- des mises à jour serveur régulières ;
- une surveillance de la charge et des pics d’activité ;
- la gestion des versions et de la scalabilité.
Pourquoi c’est indispensable (et rentable)
“On verra la maintenance plus tard.” Spoiler : c’est souvent trop tard.
Car ce n’est pas quand les crashs arrivent ou que les utilisateurs désertent qu’il faut agir. C’est avant. Une app qui fonctionne bien aujourd’hui peut devenir inutilisable demain — et pas parce que l’équipe a mal bossé. Mais parce que le contexte évolue en continu.
👉 La maintenance, ce n’est pas un coût “subi”. C’est un levier de rentabilité, de rétention et de crédibilité produit. Voici pourquoi.
Une base utilisateurs plus large (et plus fidèle)
Chaque mise à jour est une preuve : votre app est vivante. Et ça change tout.
Elle montre que vous corrigez vite. Elle prouve que vous écoutez vos utilisateurs. Elle rassure ceux qui hésitent encore à l’utiliser.
Résultat ? Une meilleure adoption, une meilleure rétention, et une satisfaction qui se voit dans les commentaires store ou les retours internes.
💡 Un bug corrigé en 3 jours, c’est perçu comme un engagement. En 3 semaines, c’est vu comme un manque de fiabilité.
Un meilleur classement dans les stores
Apple et Google n’aiment pas les apps à l’abandon. Et ça se voit.
Les stores valorisent les apps qui sont mises à jour régulièrement, restent compatibles avec les derniers OS, et corrigent les erreurs rapidement.
Concrètement : plus de visibilité = plus de téléchargements = plus de ROI sur votre app.
Une durée de vie rallongée (donc un meilleur amortissement)
Sans maintenance, votre app a une date de péremption.
Elle plante à chaque nouveau device. Elle devient vulnérable. Elle finit par être inutilisable… ou désinstallée.
Avec une TMA bien pensée, votre app peut durer 3 à 5 ans sans refonte majeure. Et ça, c’est un énorme levier de rentabilité :
💡 Une app refondue tous les 18 mois = 2 à 3 fois le budget initial à moyen terme.
Une app bien maintenue = un coût amorti, un produit stable, une roadmap maîtrisée.
Une sécurité renforcée
La moindre faille peut coûter très cher — RGPD, perte de données, réputation entachée.
Ce que permet une maintenance régulière :
- Suivi des vulnérabilités connues ;
- Mise à jour des bibliothèques critiques ;
- Patching rapide en cas d’alerte ;
- Audit de sécurité automatisé ou programmé.
🛡️ En 2025, la sécurité ne se traite pas en one-shot. C’est un réflexe permanent, et c’est la TMA qui le garantit.
Un outil métier toujours aligné avec la réalité du terrain
Si votre app est un outil interne ou B2B, le manque de maintenance freine la productivité.
Vos équipes doivent contourner des bugs récurrents. Les besoins évoluent, mais rien ne change dans l’interface. Chaque évolution devient un projet à part entière, lourd et lent.
Une bonne TMA permet :
- d’intégrer les retours terrain au fil de l’eau ;
- de déployer des évolutions légères sans rupture ;
- de garantir une continuité de service, même avec des changements en cours.
Anticiper la maintenance dès la phase de build : le vrai levier sous-estimé
Ce n’est pas la maintenance qui coûte cher. C’est de ne pas l’avoir prévue.
On voit encore trop de projets où la TMA devient un fardeau imprévu — parce qu’aucune base n’a été posée au moment du build. Résultat : chaque bug devient un projet, chaque montée d’OS une galère, chaque évolution une prise de tête.
👉 Ce qu’on vous montre ici, c’est comment poser des fondations solides dès le début — pour que votre app ne soit pas juste “livrée”, mais durablement maintenable.
Concevoir une architecture qui résiste au changement
La première dette technique, c’est souvent le découpage du code.
Une app mono-bloc, mal segmentée, c’est :
- des bugs en cascade dès qu’on touche à une feature ;
- une courbe d’apprentissage explosive pour un nouveau dev ;
- des évolutions impossibles sans tout refaire.
💡 Chez Yield, on pose une architecture modulaire dès la V1 : features isolées, services découplés, design system réutilisable. Parce que c’est ce qui permet, 6 mois plus tard, d’itérer vite — sans tout casser.
Outiller la supervision dès les premiers sprints
Le piège classique : attendre d’avoir des utilisateurs pour monitorer… alors qu’on aurait pu éviter les erreurs avant même qu’elles n’arrivent.
Dès la mise en ligne, votre app devrait déjà logguer, tracer, alerter.
Ce qu’on installe systématiquement :
- Sentry pour les erreurs front ;
- Firebase Performance Monitoring pour les lenteurs invisibles ;
- Datadog ou ELK côté back pour suivre les pics d’activité et les exceptions silencieuses.
👉 Ce n’est pas du luxe. C’est le minimum pour ne pas piloter à l’aveugle.
Documenter juste ce qu’il faut (mais vraiment)
“On documentera après”. On connaît tous la suite : personne ne documente, puis tout le monde rame.
Pas besoin de 30 pages. Mais vous devez poser une base lisible :
- Architecture générale (backend, app, services tiers) ;
- Stack technique et dépendances critiques ;
- Procédures clés (déploiement, mise à jour, rollback).
Une doc légère mais claire, c’est ce qui permet à un nouveau dev d’intervenir sans tout redemander. Et à votre prestataire de maintenance de ne pas tout réinventer.
Inscrire la maintenance dans le backlog produit
Ce n’est pas “à part”. C’est dans le flux.
Une maintenance bien gérée commence… dans les tickets. Concrètement :
- Créez un tag maintenance dans votre backlog dès le sprint 1 ;
- Réservez 20 à 30 % de bande passante à la dette tech et aux retours de production ;
- Priorisez ces sujets comme des features métier — car c’en sont.
Une app qui tient dans la durée, c’est une app où on itère sur ce qui gêne… pas juste sur ce qui brille.
Choisir le bon partenaire pour maintenir votre app
Trouver un bon prestataire pour créer une app, c’est déjà un défi. Mais en trouver un qui puisse la maintenir dans la durée, sans perte de qualité ni d’historique… c’est encore plus critique.
Voici les points à avoir en tête pour choisir un partenaire de TMA fiable, réactif et aligné avec vos enjeux.
Continuer avec l’équipe de développement initiale ? Souvent, oui
Si le prestataire qui a développé l’application est fiable et structuré, c’est généralement le choix le plus fluide.
Pourquoi ? Il connaît l’architecture et les choix techniques. Il a la documentation (quand il y en a). Et il peut anticiper les effets de bord.
En revanche, si l’équipe tourne, ou si la relation s’est étiolée, il vaut mieux repartir sur une base saine.
Reprendre avec une nouvelle équipe ? C’est possible… à conditions claires
Un prestataire expert en TMA peut parfaitement reprendre une app, même sans avoir fait le développement initial. Mais il doit être structuré pour ça.
Voici les points à valider :
- Capacité d’audit rapide (code, archi, dépendances) ;
- Maitrise des frameworks utilisés (Flutter, Swift, Kotlin…) ;
- Expérience en reprise de dette technique (et pas juste en “build from scratch”) ;
- Process de passation et documentation technique solide.
💡 Pro tip : une reprise sérieuse commence toujours par un audit flash — c’est ce qui évite les mauvaises surprises et permet de poser un cadre clair.
Les 5 critères à surveiller chez un partenaire TMA
Voici notre checklist chez Yield pour valider qu’un partenaire est prêt à prendre le relai :

Le facteur confiance (et transparence)
La TMA, ce n’est pas “du support”. C’est un travail de fond, qui nécessite :
- une visibilité sur ce qui est fait (et quand) ;
- une capacité à dire non (ou pas maintenant) ;
- une culture du delivery régulier, même sur de petits lots.
Chez Yield, c’est ce qu’on appelle une relation produit, pas juste une “prestation de maintenance”.
Organiser une maintenance mobile qui tourne (vraiment)
Une maintenance efficace, ce n’est pas une checklist à cocher une fois par trimestre. C’est un système vivant, qui s’intègre au quotidien de votre produit. Chaque brique a son propre rythme, sa méthode, ses enjeux.
👉 Voici les 6 composantes clés d’une TMA mobile bien structurée — et comment les organiser concrètement.
Corriger les bugs : en continu, pas par lot
Un bug critique ne peut pas attendre une version mensuelle. Les équipes doivent pouvoir le prioriser, le tracer, et le corriger rapidement.
Ce qu’on recommande :
- Un backlog de bugs partagé, priorisé chaque semaine ;
- Une répartition claire : correctif immédiat (hotfix) vs correctif planifié ;
- Une procédure de rollback ou de patch rapide en cas de blocage en prod.
Assurer la compatibilité avec les OS (sans attendre le crash)
Chaque mise à jour majeure d’iOS ou Android peut casser une app. Il faut donc anticiper, tester, et corriger en amont, dès la bêta publique des OS.
Les bons réflexes :
- Mise à jour planifiée à chaque version majeure ;
- Appareils de test en version bêta dès leur sortie ;
- Suivi des breaking changes dans la documentation Apple/Google.
Suivre la performance, pour ne pas découvrir les problèmes après l’utilisateur
Un bon monitoring, c’est ce qui permet de détecter une lenteur, une surcharge ou une erreur silencieuse avant qu’elle n’impacte l’usage réel.
Les outils qu’on recommande :
- Firebase Performance Monitoring ;
- Sentry pour les crashs et erreurs JS natifs ;
- Outils custom via DataDog ou Prometheus côté back.
👉 Ce suivi doit être intégré dès la V1, pas “plus tard”.
Gérer les évolutions : un sprint dédié ou un lot par mois
L’app évolue. C’est normal. Mais pour éviter la dérive, chaque demande métier doit passer par un refinement clair, un arbitrage produit, et une planification réaliste.
Deux formats possibles :
- 1 sprint TMA tous les 2 mois, avec sujets fonctionnels + correctifs ;
- Ou un “lot maintenance” intégré à chaque cycle produit.
Ce qu’il faut éviter : accumuler les petits tickets non priorisés pendant 3 mois… puis vouloir tout livrer d’un coup.
Maintenir le backend : sécurité, versions, performance
On oublie souvent que l’app mobile repose sur un backend — API, base, infra. Et que si cette brique bouge sans contrôle, l’app plante.
Ce qu’on prévoit systématiquement :
- Suivi des dépendances critiques (Node, Laravel, PostgreSQL…) ;
- Montées de version sécurisées, testées hors-prod ;
- Patchs de sécurité appliqués dans les 7 jours suivant leur publication.
Superviser en continu : logs, crashs, alertes
Sans supervision, vous volez à l’aveugle. Une app stable, c’est une app qu’on observe, pas une app qu’on “espère”.
Ce qu’on pose dès le départ :
- Collecte et tri automatique des logs (Datadog, LogRocket, ELK) ;
- Alertes en cas de crash ou d’exception critique (via Slack ou email) ;
- Rapports mensuels ou hebdo pour faire le point.
👉 En résumé : la maintenance mobile, ce n’est pas juste “corriger des bugs”. C’est maintenir un produit digital vivant, stable, sécurisé, et capable d’évoluer avec son marché.
Combien coûte la maintenance d’une application mobile ?
C’est LA question qu’on finit toujours par poser. Et c’est normal : maintenir, ça a un coût. Mais comme souvent, la bonne réponse, c’est : ça dépend. Pas du nombre d’écrans, ni du langage utilisé. Mais de la structure de l’app, de son usage réel… et de ce qu’on veut en faire dans la durée.
Voici les 3 grands postes à prévoir — et les ordres de grandeur réalistes pour 2025.
Le socle “vital” : support, correctifs, compatibilité
C’est le minimum pour éviter que votre app ne plante à la première mise à jour d’iOS.
Ce que ça inclut :
- Correction de bugs (mineurs et critiques) ;
- Suivi des mises à jour OS (Android / iOS) ;
- Monitoring de performance et de crash ;
- Mise à jour des dépendances critiques.
💸 Budget annuel moyen : 15 à 25 % du coût de développement initial
👉 Pour une app à 80 000 €, comptez entre 12 000 et 20 000 €/an pour ce socle.
Le lot d’évolutions métier : garder une app utile (et utilisée)
Une app figée, c’est une app morte. Prévoir un lot d’évolutions régulières, c’est ce qui permet de :
- intégrer les retours terrain ;
- ajuster les parcours utilisateurs ;
- enrichir la valeur métier.
💸 Budget annuel moyen : 10 à 20 jours de dev / design / QA par trimestre
Soit environ 15 000 à 40 000 €/an, selon le périmètre.
Les coûts “silencieux” : infra, sécurité, supervision
Ce sont les lignes qu’on oublie souvent… mais qui font toute la différence :
- Hébergement cloud / bases de données ;
- Suivi sécurité (audits, patchs) ;
- Outillage (monitoring, ticketing, reporting).
💸 Comptez environ 3 000 à 10 000 €/an, selon la complexité de l’archi.
Exemple de budget de maintenance sur 2 ans

💡 À retenir : un budget de TMA bien anticipé évite une refonte complète au bout de 18 mois. Ce qui en fait le meilleur amortissement long terme.
Maintenir, c’est faire vivre (et faire gagner)
Une application mobile ne meurt pas parce qu’elle est mal conçue. Elle meurt parce qu’on l’abandonne après sa mise en ligne.
Pas de correctifs rapides = des notes en chute.
Pas de mises à jour OS = une app rejetée du Store.
Pas de suivi des usages = des utilisateurs qui désertent.
À l’inverse, une application bien maintenue, c’est une app qui :
- reste fluide sur tous les appareils,
- évolue avec les besoins métier,
- anticipe les problèmes de sécurité,
- et continue de livrer de la valeur des mois — voire des années — après sa sortie.
💡 La vraie question n’est pas “combien coûte la maintenance d’une app ?” mais “combien vaut sa stabilité et sa capacité à durer”.
Que vous soyez porteur de projet ou DSI, la qualité de votre maintenance conditionne la réussite de votre application.
Vous voulez estimer votre budget de maintenance, reprendre un existant avec une nouvelle équipe ou anticiper les ruptures iOS/Android à venir ?
👉 Parlez-nous de votre app. On vous aide à poser une stratégie claire, durable et alignée avec vos enjeux réels.

90 % du temps passé sur smartphone l’est dans des apps. Et ce chiffre ne faiblit pas. Achat, logistique, santé, formation, RH… le mobile est devenu le point d’entrée par défaut.
Mais les règles du jeu ont changé. Aujourd’hui, les attentes sont claires : une interface qui répond au quart de seconde, une expérience qui s’adapte à l’usage, de l’IA bien intégrée (pas juste un chatbot gadget), et zéro surchauffe ou vidage de batterie. Une app, ça doit marcher vite, bien, longtemps — sinon, elle est supprimée.
👉 Créer une app, ce n’est plus simplement “mettre une interface dans un store”. C’est construire un produit à part entière — utile, fiable, adopté.
Et c’est là que beaucoup se plantent : ils pensent “développement”, là où il faut penser vision produit, stratégie d’usage, et arbitrage UX/tech.
Étape 1 – De l’idée au concept produit
Avant de penser dev, stack ou fonctionnalités… il faut valider le plus important : est-ce qu’on résout un vrai problème ?
Pas un “ce serait cool si” — un irritant concret, prioritaire, vécu sur le terrain.
C’est ce qu’on appelle le Problem/Solution Fit. Tant qu’on ne l’a pas, le risque est simple : construire une app que personne n’utilise.
Pour poser les bases du bon produit, quelques outils suffisent :
On ne parle pas de framework magique, mais de grilles qui permettent de sortir du flou — vite.
- Entretiens utilisateurs : 5 interviews ciblées valent mieux que 50 suppositions. Ce que disent (et vivent) vos futurs utilisateurs est plus précieux que n’importe quelle feature list.
- Lean Canvas : une vision produit + marché, synthétisée en une page. On y pose les bases : problème, solution, segment, canaux, revenus, etc.
- Opportunity Tree : pour structurer les options produit. Pas juste empiler des fonctionnalités, mais garder le lien entre le besoin, l’objectif, et l’action utile.
Pour formaliser tout ça, deux formats simples à utiliser :
Pas besoin d’un doc de 20 pages. Un Product Canvas ou une fiche JTBD (Jobs To Be Done) bien remplie suffit à cadrer une V1.

Ce que vous devez faire apparaître :
- Le problème que vous adressez ;
- Le profil utilisateur visé ;
- Le scénario d’usage clé ;
- Le résultat attendu, mesurable, concret.
Toujours viser une V1 chirurgicale
Pas un proto fourre-tout. Pas une app “qui en jette”. Juste ce qu’il faut pour prouver l’usage, rien de plus.
- Uber V1 ne gérait que les courses à San Francisco, avec une flotte privée.
- Yuka scannait un code-barres et affichait une note, point.
- Doctolib, au départ, permettait uniquement de prendre un rendez-vous avec un généraliste à Paris.
👉 À chaque fois : une seule feature critique, bien exécutée, pour tester l’appétence réelle.
Pas besoin de tout livrer pour apprendre — juste de viser juste.
Et surtout : éviter les 5 pièges classiques
On les voit tous les jours. Ils coûtent du temps, de l’énergie, et des budgets gaspillés.
Voilà ce que vous devez éviter :
- Se lancer sans parler à un seul utilisateur ;
- Empiler 12 features pour “faire complet” ;
- Copier un concurrent sans comprendre l’usage réel ;
- Viser trop large trop tôt ;
- Ne pas définir ce qu’est une V1 utile.
Une bonne app commence par un besoin prioritaire. Pas par une liste de fonctionnalités.
Étape 2 – Choisir la bonne techno : ambition, usage, budget
Ce n’est pas “quelle techno est la meilleure ?” C’est quelle techno est la plus adaptée à votre produit, votre budget, votre ambition.
Car non, vous n’êtes pas obligé de faire du natif. Et non, le low-code n’est pas “du faux dev”.
Ce qui compte, c’est ce que vous visez.

Native : pour les applis qui doivent tout faire, vite et bien
C’est le haut de gamme. Une app iOS en Swift, une Android en Kotlin. Deux bases de code, deux équipes.
Mais une fluidité parfaite, un accès complet au hardware, et des performances au rendez-vous.
Typiquement ? Une app bancaire, de gaming, de streaming, ou avec de lourdes contraintes offline.
C’est solide… mais c’est cher. Et plus lent à faire évoluer.
Hybride : le bon choix pour 80 % des projets
Une base de code unique (Flutter, React Native), deux plateformes couvertes. Résultat : moins de budget, plus de vélocité, et une app qui coche quasiment toutes les cases.
Chez Yield, c’est notre go-to stack pour la majorité des apps B2B ou des MVPs un peu ambitieux — comme cette app de gestion des congés, connectée au SIRH, pensée mobile-first et livrée en quelques semaines.
PWA : le web qui joue à être une app
Pas besoin de passer par les stores. Un clic sur un lien, et l’app s’ouvre. C’est rapide, léger, frictionless.
Mais attention : l’expérience n’est pas totalement native. Et les possibilités restent limitées côté fonctionnalités avancées (notifs, GPS, accès hardware…).
C’est idéal pour un configurateur produit, une app événementielle ou un tunnel de réservation mobile-first.
Low-code / No-code : tester vite, lancer proprement
Vous avez un besoin interne, un usage à valider ou une app Excel à professionnaliser ? Le low-code est votre ami.
Des outils comme WeWeb, Glide ou FlutterFlow permettent de créer des interfaces robustes… sans passer 3 mois en dev natif.
Mais attention : ce n’est pas un raccourci. Il faut cadrer, designer, tester. Sinon, vous livrez un outil bancal plus vite — mais pas mieux.
Exemple : app de saisie terrain pour techniciens, montée en quelques semaines avec FlutterFlow.
💡 La question n’est pas “quelle est la meilleure techno”, mais “laquelle me permet de livrer une V1 utile, dans mon timing, avec mes moyens”.
Retour d’XP :
“ Une startup industrielle vient nous voir avec un MVP no-code bâti sur Glide : usage validé, adoption confirmée… mais limites atteintes sur les perfs et la gestion fine des droits. On a repris avec FlutterFlow, en gardant la logique fonctionnelle. Moralité : le no-code est top pour tester — mais cadré dès le départ pour éviter le refacto total.”
Étape 3 – Le design UX/UI au cœur du succès
Une bonne app, ce n’est pas (juste) une app jolie. C’est une app qu’on comprend en 3 secondes, qu’on utilise sans friction, et qu’on a envie de rouvrir.
En 2025, l’expérience prime sur l’esthétique. Les utilisateurs ne pardonnent pas les parcours tordus, les interfaces surchargées ou les micro-bugs d’affichage. Ce qu’ils veulent : une app qui marche, qui va droit au but, et qui ne fait pas perdre de temps.
Le process UX à suivre (et à ne jamais brûler)
Pas besoin d’un tunnel de livrables. Mais chaque étape a son importance pour éviter de dériver.
Voici le parcours qu’on suit chez Yield pour éviter les angles morts dès le début :
- Interviews utilisateurs & personas : comprendre qui on cible, et dans quelles conditions réelles ils utiliseront l’app.
- Jobs To Be Done : formaliser les déclencheurs d’usage, les irritants, les leviers d’adoption.
- Wireframes & parcours clés : ne pas chercher à tout modéliser, mais verrouiller les moments critiques (onboarding, action principale, validation, etc.).
- UI System + tests d’interfaces (Maze, Useberry…) : un design cohérent, accessible, et validé sur cible.
Ce que les utilisateurs attendent vraiment
Une app doit aller droit au but : fluide, lisible, intuitive. Le dark mode, l’accessibilité, un langage simple et direct ? C’est la base.
Chaque interaction doit donner un retour clair, immédiat. Animations douces, micro-interactions utiles, navigation sans à-coups : on ne doit jamais se demander "et maintenant ?".
L’IA ? Oui, mais bien intégrée. Pas un chatbot plaqué. Un vrai levier pour simplifier, personnaliser, anticiper.
Et si le réseau coupe ? L’usage continue. La gestion offline n’est plus un luxe.
Et côté méthode, quelques principes qui changent tout
Ces conseils sont simples, mais ils évitent 80 % des erreurs de design produit :
- Ne commencez jamais un écran sans scénario d’usage associé.
- Ne validez aucune interface sans au moins un retour utilisateur (même informel).
- Ne misez pas sur le "waouh effect". Ce qui compte, c’est l’intuitivité.
👉 Le design n’est pas là pour “faire beau”. Il est là pour faire comprendre, faire agir, faire revenir.
Et dans un monde où chaque utilisateur zappe en 2 secondes, c’est ce qui fait la différence entre une app adoptée… et une app désinstallée.
Étape 4 – Le développement : rapide, propre, maintenable
Lancer le développement, ce n’est pas une simple exécution. C’est le moment où chaque choix technique a un impact direct sur la stabilité, la vélocité et la maintenabilité du produit.
Et ce qu’on construit ici, ce n’est pas “juste une app” : c’est un socle technique qui doit tenir dans le temps, absorber les évolutions, supporter la montée en charge — sans tout casser.
Une stack standardisée, testée, prête à scaler
En 2025, certaines briques sont devenues des évidences. On ne les choisit pas par effet de mode, mais parce qu’elles répondent aux contraintes les plus fréquentes : time-to-market, performance, évolutivité.
Stack mobile recommandée :
- Front-end : Flutter ou React Native → pour une base de code unique, des performances proches du natif, et une vélocité de dev accrue.
- Back-end : Node.js, Laravel, Supabase ou Firebase → selon les enjeux de scalabilité, de persistance des données et de logique métier.
- API : REST si l’équipe a besoin de simplicité. GraphQL si le projet nécessite de la flexibilité et de l’optimisation côté client.
- Fonctionnalités critiques à anticiper : authentification sécurisée, gestion offline, analytics embarqué, push notifications, gestion des paiements.
Ces choix doivent être faits dès le cadrage technique. Une stack mal posée = une dette assurée à moyen terme.
Et côté architecture : modulaire, testable, réversible
Ce n’est pas juste le code qui compte. C’est la façon dont on le structure, le versionne, le déploie.
Ce qu’on met en place pour un produit sain dès le jour 1 :
- Architecture modulaire → chaque feature isolée, testable indépendamment, et facile à maintenir.
- CI/CD dès le début → automatisation des tests, des builds et des déploiements pour livrer vite… et propre.
- Feature Flags → tester une fonctionnalité en prod sans l’imposer à tout le monde. Activer/désactiver en un clic. A/B tester sans fracas.
💡 Exemple client : sur une app de suivi de maintenance terrain, on a activé une nouvelle UI de reporting uniquement pour 5 % des utilisateurs grâce aux feature flags. Résultat : itérations plus rapides, aucune régression visible, adoption mesurée.
Étape 5 – Tester avant de crasher : QA, dry-run et terrain
Le développement est terminé. L’app tourne. Mais avant de la balancer dans les stores, un réflexe : tester comme si elle était déjà en prod.
Parce que le vrai crash, ce n’est pas un bug technique. C’est une app qui freeze chez l’utilisateur, une feature qui ne sert à rien, une perf qui s’effondre dès qu’on sort du wifi.
Ce qu’on teste, et quand
Dès la première version fonctionnelle, il faut croiser deux approches : tests techniques et tests utilisateurs.
Tests fonctionnels :
- Scénarios critiques automatisés : login, parcours principal, paiement, etc.
- Tests snapshot pour détecter les régressions visuelles.
- Outils à activer : Detox, Appium, Jest (ou équivalents selon la stack).
Tests utilisateurs :
- Panels internes (équipe, partenaires, testeurs proches).
- Early adopters externes (petit groupe cible avec feedback rapide).
- Pré-prod via TestFlight (iOS) ou Google Play Console (Android).
Ce n’est pas “on verra à la bêta”. C’est dès la version alpha qu’on mesure : clarté des flows, friction, compréhension, valeur perçue.
Bonus expert : ne jamais lancer dans le vide
Quelques pratiques simples pour sécuriser la release — même avec une V1 imparfaite :
- Toujours faire un dry-run : simulez un lancement réel avec l’équipe. Parcours complet, de l’installation au support.
- Monitoring post-release : mettez en place le suivi dès le jour 1 :
- Crash reports (Firebase Crashlytics, Sentry)
- Suivi des erreurs et ralentissements
- Heatmaps, funnels, logs UX
L'objectif : corriger dès que possible, avant que les premiers utilisateurs ne jugent l’app sur sa première impression.
Une app bien testée, ce n’est pas une app sans bug. C’est une app qui réagit vite, apprend vite, et évolue sans casser.
Étape 6 – Lancer, ce n’est pas juste publier
Le store, ce n’est pas une vitrine. C’est un champ de bataille. Votre app y sera noyée parmi des milliers. Sans stratégie de lancement, vous ratez l’occasion de capter l’attention là où elle est la plus précieuse : au jour 1.
Avant de cliquer sur “publish”, préparez le terrain
L’upload ne prend que quelques minutes. Mais tout ce qui se joue autour est critique.
Ce qu’il faut avoir préparé en amont :
- Un compte développeur Apple et Google (créé, vérifié, prêt).
- Les visuels et captures d’écran optimisés pour chaque store.
- Une description orientée bénéfice utilisateur (pas juste la liste de fonctionnalités).
- Des tests de titres et sous-titres (A/B test possibles avec StoreMaven ou via Google Play).
Premier objectif : apparaître, séduire, convertir. Et ça se joue dans les 30 premières secondes.
Un lancement, ça se chauffe
Si personne n’attend votre app, personne ne la verra. Les premières installations, reviews et usages influencent directement l’algorithme des stores.
Tactiques simples à activer :
- Liste d’attente avec incentive clair (accès prioritaire, bonus, rôle de testeur…).
- Bêta ouverte sur TestFlight ou Google Play Console, pour générer de premiers retours + reviews.
- Campagne d’activation ciblée : newsletter, posts LinkedIn, influenceurs de niche.
- Micro-influence > pub broad : les utilisateurs font plus confiance à un retour authentique qu’à un display surchargé.
Et surtout : attention aux reviews. Mauvais départ = crédibilité à rattraper, algorithme à reconquérir.
Retour d’XP :
“Une app RH interne devait être déployée auprès de 800 collaborateurs. Plutôt que de pousser l'app “en masse”, l’équipe a mis en place un plan de chauffe sur 10 jours :
- teasing dans la newsletter interne,
- accès anticipé pour un groupe pilote (TestFlight),
- série de mini-vidéos tutos envoyées sur Slack.
Résultat : 70 % de taux d’installation en 48h, 30 avis positifs dès le jour 1, et une adoption immédiate.”
Quelques outils utiles pour ne rien rater
Un bon lancement, c’est aussi une bonne stack. Ces outils ne font pas le job à votre place, mais ils vous aident à déclencher, observer et ajuster dès les premiers jours :
- OneSignal : push notification + activation.
- StoreMaven : test A/B sur la fiche store.
- AppFollow : suivi et réponse aux reviews + veille concurrentielle.
Un bon lancement ne fait pas tout. Mais un mauvais peut tout plomber. Préparez-le comme un événement produit — pas comme une formalité technique.
Étape 7 – L’après-lancement : apprendre, améliorer, construire sur le long terme
Publier une app, ce n’est pas clore un projet. C’est lancer un produit. Et un produit digital qui ne bouge pas… finit par se faire oublier.
L’enjeu, ce n’est pas seulement de corriger des bugs ou d’ajouter une feature sympa. C’est d’apprendre vite, itérer juste, et construire une base solide pour faire évoluer l’app sans repartir de zéro tous les 6 mois.
Mettre en place une boucle de feedback continue
Dès les premiers jours, il faut capter ce qui se passe sur le terrain :
- Surveys intégrés, support in-app, interviews utilisateurs ciblées
- Analytics comportemental : où ça clique, où ça décroche
- Feedback qualitatif des early adopters
Objectif : comprendre ce que les utilisateurs font (ou ne font pas) — et pourquoi. Sans cette boucle, impossible de prendre de bonnes décisions produit.
Retour d’expérience
“Sur une app RH B2B récemment lancée, on observe un gros décrochage à l’étape de connexion mobile. Les analytics ne suffisent pas, mais croisé aux retours support + logs, on remonte un bug SSO spécifique à Android. Corrigé en 48h. Résultat : +35 % de rétention J1.
Avant de chercher la “feature magique”, commencez par débloquer l’usage de base. C’est souvent là que tout se joue.”
Suivre les bons KPIs produit
Pas besoin de suivre 30 métriques. Juste les bonnes :
- Rétention J1–J7–J30 : est-ce qu’on garde les utilisateurs ?
- Activation : atteignent-ils la valeur clé rapidement ?
- Fréquence d’usage : l’app devient-elle un réflexe ?
- Conversion : est-ce que ça produit un impact mesurable (achat, engagement, prise de RDV…) ?
Ces KPIs ne servent pas à décorer un dashboard. Ils guident la priorisation.
Structurer une roadmap qui tient dans le temps
On sort d’une logique “features à empiler”. On construit une roadmap produit :
- Quick wins : les petits ajustements qui changent tout.
- Améliorations structurantes : refonte de parcours, optimisations clés.
- Scalabilité : ouvrir à d’autres cibles, préparer l’international, passer du B2C au B2B…
👉 Une app n’est jamais “finie”. C’est un produit vivant. Et un bon lancement n’a de valeur que si l’itération suit. Construire une app, c’est poser les fondations d’un produit qui évolue avec ses utilisateurs — pas un projet à figer.
Bonus – Combien coûte une application mobile en 2025 ?
Une bonne app, ça se chiffre. Mais ce qui coûte cher, ce n’est pas le développement en soi. C’est de mal cadrer, mal prioriser, ou de devoir tout reprendre 6 mois plus tard.
Le budget dépend de 3 facteurs :
- La complexité fonctionnelle
- Le nombre de plateformes (iOS, Android, web...)
- Le niveau d’exigence UX / sécurité / scalabilité
Quelques repères réalistes

Ces budgets incluent généralement : design, développement, tests, déploiement, accompagnement au lancement. Mais pas toujours le run (maintenance, itérations, hébergement).
💡 Vous avez 50k€ ? Plutôt que de viser deux plateformes et tout faire à moitié, mieux vaut un MVP chirurgical sur une seule plateforme, mais solide, testé, et itérable. Le bon budget n’est pas le plus gros — c’est celui qui aligne ambition, valeur, et timing.
Conseils pour éviter les mauvaises surprises
- Ne jamais acheter une app “finie” sans prévoir ce qui suit : corrections, évolutions, support. Sinon, le budget explose à la moindre demande.
- Fuir les promesses à 10k€ sur des plateformes low-cost ou avec des freelances non spécialisés. L’économie initiale se transforme vite en dette technique.
👉 Une app qui marche vraiment, ce n’est pas celle qu’on peut payer “au plus bas”. C’est celle qui crée de la valeur sans exploser à l’usage.
Une app qui marche, c’est une app bien pensée — pas juste bien codée
Créer une application mobile en 2025, ce n’est pas “faire une app”. C’est lancer un produit digital qui doit trouver son usage, sa place, sa valeur.
Et ça ne repose pas sur une idée brillante ou une techno dernier cri, mais sur une chaîne de décisions solides :
- Valider un vrai besoin ;
- Cadrer une V1 utile ;
- Choisir la bonne stack ;
- Soigner l’expérience ;
- Anticiper les itérations.
Chaque étape compte. Chaque oubli se paie plus tard — en bugs, en churn, en rework.
Chez Yield, on ne se contente pas de “développer une app”. On accompagne la construction d’un produit mobile qui tient la route, dès le jour 1… et surtout les suivants.
Vous avez un projet d’application ? Parlons produit, pas juste code.
.png)
Je suis Cyrille, co-fondateur de Yield Studio. À travers cette série de contenus, je partage ce que nous vivons au quotidien dans le développement logiciel, web et mobile. L’objectif ? Offrir aux DSI, CTO, responsables digitaux – et à tous ceux qui s’intéressent à la construction de produits numériques – des retours d’expérience concrets, actionnables, ancrés dans la réalité de 2025.
On commence avec un sujet brûlant : la crise du développement logiciel. Pourquoi tant de projets échouent ? Que faut-il changer ? Et comment s’adapter concrètement dans les mois qui viennent ?
1. Comment on constate une crise du développement logiciel ?
Le constat est sans appel. Selon le Standish Group, seuls 29 % des projets IT sont livrés avec succès. Plus de la moitié dépassent les budgets et les délais. Près d’un projet sur cinq échoue complètement. Les entreprises investissent dans leur transformation digitale, mais peinent à livrer des produits rentables.
Plusieurs symptômes traduisent cette crise :
- Des projets hors de contrôle, avec un surcoût moyen de 45 % et des cycles de développement qui s’étendent sur 11,5 mois.
- Une complexité technique croissante qui freine l’innovation : les développeurs passent 42 % de leur temps à gérer la dette technique (Stripe).
- Une pénurie mondiale de talents : d’ici 2030, il manquera 85 millions de développeurs selon Korn Ferry.
- Des logiciels qui ne répondent pas aux besoins utilisateurs, souvent livrés trop tard ou inexploitables.
- Une mutation structurelle avec l’essor du SaaS, du low-code et de l’IA, qui redistribue les cartes.
Le modèle traditionnel ne fonctionne plus. Il doit évoluer rapidement.
2. Les trois causes profondes de la crise du développement logiciel
Une gestion de projet inefficace
De nombreux projets démarrent avec des objectifs flous : "tester une techno", "faire un MVP", sans indicateurs de succès définis. Cela revient à acheter un bien immobilier sans se poser la question de sa rentabilité. Résultat : les équipes naviguent à vue, empilent des fonctionnalités, et peinent à définir une version livrable.
Autre problème : l’explosion incontrôlée du périmètre. Beaucoup d’équipes veulent tout intégrer dès le départ. Ce phénomène, connu sous le nom de "scope creep", transforme un projet de quelques mois en impasse.
Enfin, la dette technique s’accumule rapidement. La pression des délais pousse à faire des compromis sur l’architecture, le code devient difficilement maintenable, et l’innovation ralentit. Ce cycle est auto-alimenté : mauvaise gestion → dette → ralentissement → échec.
Une pénurie de développeurs et des conditions de travail dégradées
Le marché est tendu, mais la crise ne vient pas que du manque de talents. Elle vient aussi des conditions dans lesquelles on leur demande de travailler.
Lors de nos recrutements, les mêmes raisons reviennent : surcharge de travail, délais irréalistes, empilement de fonctionnalités sans vision produit, code legacy impossible à reprendre. Ce contexte pousse les meilleurs profils à partir.
Et chaque départ fait perdre une connaissance précieuse du projet. Les remplaçants peinent à reprendre un code mal documenté. La productivité chute, les délais s’allongent, et les coûts explosent.
Un modèle de développement qui ne répond plus aux attentes actuelles
En 2025, un projet digital ne peut plus attendre deux ans pour prouver sa rentabilité. Pourtant, nombre d’organisations s’accrochent à des méthodologies rigides, des stacks lourdes, des cycles en cascade.
En parallèle, le low-code et le no-code offrent des alternatives viables pour prototyper rapidement. Ce ne sont pas des menaces pour les développeurs, mais des outils complémentaires. Bien intégrés, ils permettent de tester des idées sans alourdir les plannings de développement.
L’IA joue aussi un rôle croissant. Des outils comme GitHub Copilot assistent les développeurs, réduisent le temps passé sur les tâches répétitives, et facilitent la documentation. L’objectif n’est pas de remplacer les humains, mais de leur permettre de se concentrer sur les vrais défis.
3. Ce qui va changer pour les entreprises en 2025
Un pilotage plus rigoureux des projets
Les Proof of Concept devront désormais s’appuyer sur des KPI concrets (utilisateurs actifs, taux d’adoption, impact business). Les cycles d’itération seront courts, ciblés, avec des objectifs mesurables. Finis les projets sans cap clair.
Les budgets IT seront alignés avec les résultats. Chaque ligne de développement devra justifier son retour sur investissement.
Une adoption massive des outils low-code, no-code et IA
Les équipes métiers vont s’équiper d’outils pour créer elles-mêmes des applications simples. Les développeurs devront orchestrer ces outils, intégrer les briques no-code dans des systèmes complexes, et faire des choix technologiques plus productifs.
Chez Yield Studio, par exemple, nous utilisons Laravel avec TallStack (Livewire + FluxUI) pour accélérer la mise en production sans sacrifier la qualité.
Des outils IA qui deviennent des standards dans les équipes techniques
GitHub Copilot, les tests automatisés, la génération de documentation : tout cela va s’industrialiser. Les mises en production devront être plus fréquentes, plus fiables. Les tests automatisés remplaceront les longues campagnes manuelles.
Mais cette rapidité soulève un nouveau défi : la sécurité.
Un cadre réglementaire plus exigeant sur la cybersécurité
Avec l’accélération du développement, les failles de sécurité se multiplient. En 2025, des textes comme DORA, NIS2 ou les normes ISO vont imposer des exigences strictes. Il faudra intégrer la sécurité dès la conception ("Security by Design"), avec des audits réguliers et des architectures Zero Trust.
4. Comment s’adapter concrètement à cette nouvelle époque ?
Voici quatre leviers immédiats à activer.
Se poser les bonnes questions dès le début
Avant d’engager des ressources, identifiez les hypothèses clés à valider, les indicateurs de succès, et les signaux de non-viabilité. Évitez les projets "sympas" mais sans impact.
Tester avant d’industrialiser
Un prototype, même imparfait, permet de valider une idée. Utilisez le no-code ou le low-code pour avoir un retour utilisateur rapide. Ce n’est qu’après validation que vous engagez un vrai budget de développement.
Définir un périmètre clair et le respecter
Priorisez à l’aide de méthodes comme MoSCoW. Mieux vaut livrer une version simple mais fonctionnelle que de viser la perfection… et ne rien livrer du tout.
Aligner toutes les parties prenantes
Tech, produit, métiers : tout le monde doit avancer dans la même direction. Dès le lancement, mettez en place des routines d’alignement, des outils de collaboration, et un processus de décision clair.
Comment mettre tout cela en place ?
Recruter des profils expérimentés
Si vous avez les moyens, constituez une équipe interne avec des profils seniors capables de structurer les projets. Mais ces profils sont rares, chers, et difficiles à retenir.
Faire appel à des experts indépendants
Un regard extérieur peut débloquer une situation, apporter une méthodologie, et accélérer la mise en production.
Travailler avec une équipe structurée
C’est notre approche chez Yield Studio. Nous accompagnons les entreprises dans la structuration, la conception et le développement de logiciels. Notre méthode : lancer vite, livrer un produit qui marche, et itérer à partir du réel.
Conclusion : passez à l’action maintenant
Le monde ne vous attendra pas. Le marché évolue, les outils progressent, et les attentes des utilisateurs aussi. Rester compétitif en 2025 implique d’évoluer. Pas dans six mois. Pas l’année prochaine. Maintenant.
La vraie question n’est plus "faut-il changer", mais "comment allez-vous le faire ?".

