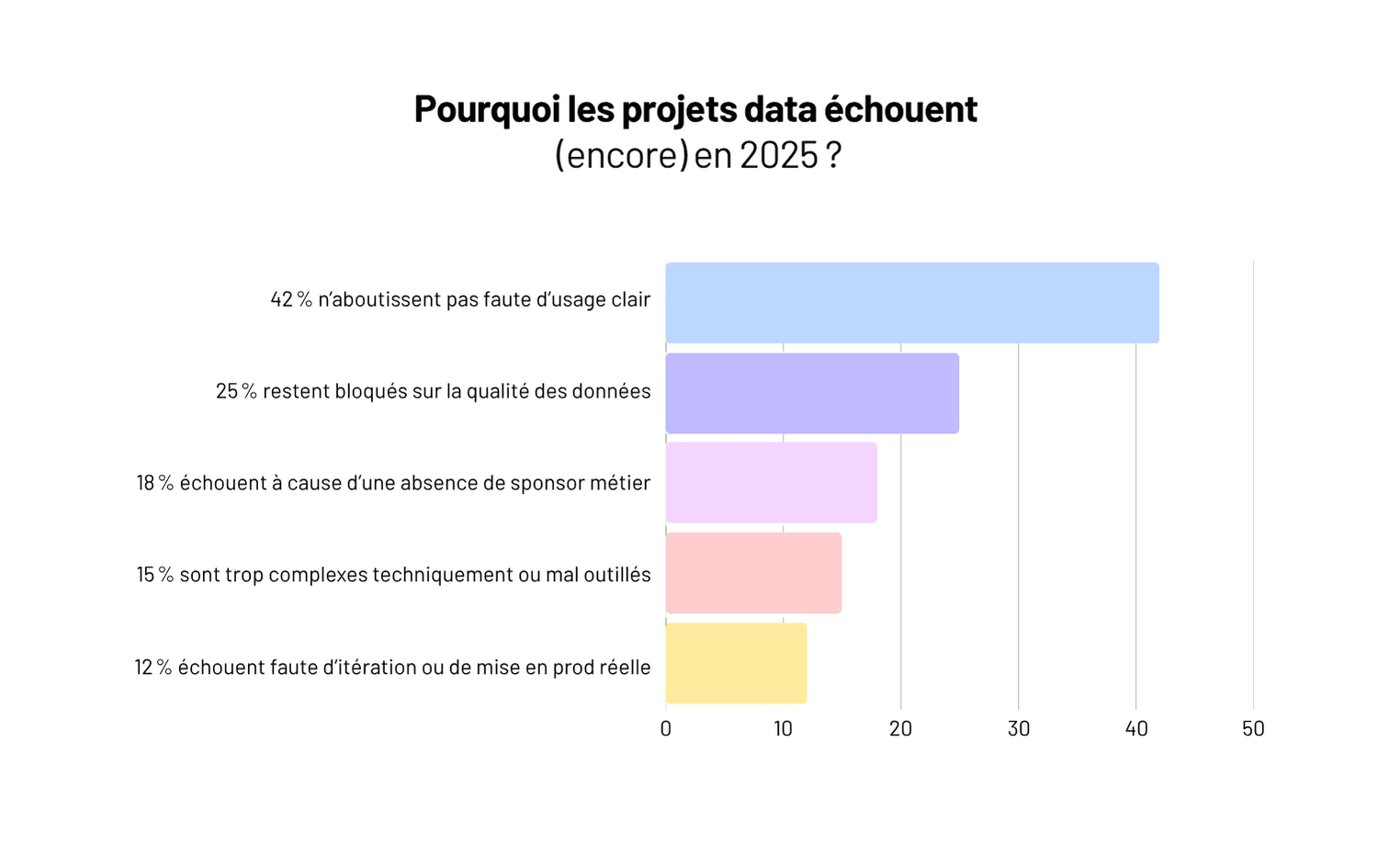
Vos données existent. Elles sont dans votre CRM, votre ERP, vos fichiers Excel, vos outils SaaS, vos bases de production. Le problème n'est presque jamais l'absence de données. C'est l'incapacité à les exploiter de manière fiable, rapide et transverse.
Quand un directeur métier demande un chiffre et que trois personnes donnent trois réponses différentes, ce n'est pas un problème de reporting. C'est un problème d'infrastructure data. Et c'est exactement là que le data engineering entre en jeu.
Pourtant, le sujet reste flou pour beaucoup de décideurs. On confond data engineering et data science. On pense que poser un dashboard suffit. On investit dans un outil de BI sans avoir fiabilisé les données qui l'alimentent.
Dans cet article, on pose les bases clairement : ce qu'est le data engineering, les architectures modernes qui structurent le marché, les outils du modern data stack, et surtout les signaux concrets qui indiquent qu'il est temps d'investir.
Data engineering : de quoi parle-t-on exactement ?
Le data engineering désigne l'ensemble des pratiques, outils et architectures qui permettent de collecter, transformer, stocker et rendre accessibles les données d'une organisation. C'est la plomberie invisible qui permet à tout le reste de fonctionner : dashboards, modèles IA, reporting, automatisations.
Sans data engineering fiable, rien ne tient. Un modèle de machine learning entraîné sur des données incohérentes produit des résultats incohérents. Un dashboard alimenté par des flux cassés affiche des chiffres faux. Une décision prise sur une donnée non fiabilisée est une décision risquée.
Data engineering vs data science : deux métiers, deux temporalités
La confusion est fréquente. Voici la distinction essentielle :
- Le data engineer construit les pipelines, les flux, l'infrastructure. Il s'assure que la donnée arrive au bon endroit, au bon format, au bon moment. C'est un métier d'ingénierie logicielle appliqué à la donnée.
- Le data scientist exploite la donnée pour en extraire des insights, des modèles prédictifs, des algorithmes. Il travaille en aval, sur une donnée déjà structurée et fiable.
En pratique, un data scientist sans data engineer passe 80 % de son temps à nettoyer des données au lieu de les exploiter. C'est le scénario qu'on observe le plus souvent chez nos clients.
"Le vrai goulot d'étranglement sur les projets data, ce n'est presque jamais le modèle. C'est la qualité et la disponibilité des données en amont. Tant que les fondations ne sont pas posées, on construit sur du sable."
-- James, CTO @ Yield Studio
Data engineering vs BI : ne pas confondre le tuyau et le robinet
La Business Intelligence (BI) concerne la visualisation et l'analyse des données : tableaux de bord, rapports, KPIs. C'est la couche visible, celle que les métiers utilisent au quotidien.
Le data engineering, lui, concerne tout ce qui se passe avant : l'extraction depuis les sources, la transformation, le nettoyage, le chargement dans un entrepôt de données. Sans cette couche, la BI ne peut pas fonctionner correctement.
Investir dans un outil de dataviz sans avoir fiabilisé les flux en amont, c'est poser un beau compteur sur un moteur qui cale.
📌 A retenir
Le data engineering est le socle technique sur lequel reposent la BI, la data science et l'IA. Sans lui, ces disciplines restent des promesses théoriques.
Les architectures data modernes : comprendre les options
Quand on parle d'architecture data, on parle de la manière dont les données sont collectées, stockées, transformées et rendues accessibles. Le choix d'architecture conditionne la performance, la scalabilité et le coût de votre infrastructure data.
Quatre grandes approches structurent le marché aujourd'hui.
Le data warehouse : la référence historique
Le data warehouse (entrepôt de données) centralise les données structurées dans un schéma défini à l'avance. Les données sont nettoyées et transformées avant d'être chargées (approche ETL classique).
Forces :
- Performances élevées sur les requêtes analytiques
- Données fiables et cohérentes (schéma imposé)
- Idéal pour le reporting et la BI
Limites :
- Rigide face aux données non structurées (logs, images, texte libre)
- Coûteux à faire évoluer quand les sources se multiplient
- Le schéma doit être défini en amont, ce qui ralentit l'intégration de nouvelles sources
Les solutions cloud comme Snowflake, BigQuery ou Redshift ont modernisé le concept en apportant élasticité et séparation compute/storage, mais la logique reste la même : des données structurées, un schéma strict, une gouvernance forte.
Le data lake : la flexibilité brute
Le data lake stocke les données dans leur format natif, sans transformation préalable. Structurées, semi-structurées, non structurées : tout rentre.
Forces :
- Stockage peu coûteux (object storage type S3, GCS)
- Flexibilité maximale sur les formats de données
- Adapté aux cas d'usage data science et machine learning
Limites :
- Sans gouvernance, le data lake devient un "data swamp" (marécage de données) où personne ne retrouve rien
- Performances analytiques médiocres sans couche de transformation
- Complexité opérationnelle élevée
Le data lake fonctionne bien quand il est couplé à une couche de transformation robuste. Seul, il accumule de la donnée sans créer de valeur.
Le lakehouse : le meilleur des deux mondes
Le lakehouse combine la flexibilité du data lake avec les performances analytiques du data warehouse. C'est l'architecture qui monte en puissance depuis 2022.
Le principe : stocker les données dans un format ouvert (Parquet, Delta, Iceberg) sur un stockage objet, tout en offrant des capacités de requêtage SQL performantes et une gouvernance de type warehouse.
Forces :
- Un seul système pour le reporting, la data science et le machine learning
- Formats ouverts (pas de vendor lock-in)
- Support des transactions ACID sur du stockage objet
- Coûts maîtrisés grâce à la séparation compute/storage
Limites :
- Écosystème encore en maturation sur certains cas d'usage
- Complexité de mise en oeuvre initiale plus élevée
- Nécessite une équipe data engineering compétente
Des solutions comme Databricks (Delta Lake), Apache Iceberg ou Apache Hudi incarnent cette approche. Snowflake a aussi évolué dans cette direction.
Le data mesh : une approche organisationnelle, pas technique
Le data mesh est souvent mal compris. Ce n'est pas une technologie ni un outil. C'est un modèle d'organisation qui décentralise la responsabilité des données vers les équipes métier (les "domaines").
Quatre principes fondateurs :
- Domain ownership : chaque équipe métier est propriétaire de ses données et les expose comme un produit
- Data as a product : les données sont documentées, fiables, accessibles, versionnées
- Self-serve platform : une plateforme interne fournit les outils pour que chaque domaine puisse gérer ses données en autonomie
- Federated governance : des standards communs (formats, qualité, sécurité) appliqués de manière fédérée
Forces :
- Scalabilité organisationnelle : chaque domaine avance à son rythme
- Meilleure qualité des données (les producteurs sont aussi les responsables)
- Réduit les goulots d'étranglement d'une équipe data centrale
Limites :
- Nécessite une maturité organisationnelle forte
- Complexe à mettre en place dans des structures de moins de 200 personnes
- Risque de fragmentation sans gouvernance fédérée solide
⚠️ Attention
Le data mesh n'est pas pour tout le monde. Si vous avez moins de 5 équipes productrices de données, une architecture centralisée sera plus efficace. Le data mesh résout un problème d'échelle organisationnelle, pas un problème technique.
Comment choisir ?
Il n'y a pas de "meilleure" architecture. Le choix dépend de votre contexte :
- PME avec des besoins de reporting : un data warehouse cloud (BigQuery, Snowflake) suffit largement
- Organisation avec des cas d'usage data science + BI : le lakehouse est le bon compromis
- Grand groupe avec de multiples domaines métier : le data mesh mérite d'être exploré, mais pas avant d'avoir un socle technique solide
"L'erreur la plus fréquente qu'on voit chez nos clients, c'est de choisir une architecture trop complexe par rapport à leur maturité data. Un BigQuery bien configuré avec dbt, c'est déjà une machine de guerre pour 90 % des PME et ETI."
-- James, CTO @ Yield Studio
Le modern data stack : les outils qui changent la donne
Le "modern data stack" désigne l'ensemble des outils cloud-native qui permettent de construire une infrastructure data performante, sans gérer de serveurs. C'est l'industrialisation du data engineering rendue accessible.
ELT vs ETL : un changement de paradigme
Historiquement, l'approche ETL (Extract, Transform, Load) imposait des transformations complexes avant le chargement. Le modern data stack a inversé la logique avec l'approche ELT (Extract, Load, Transform) : on extrait les données brutes, on les charge telles quelles dans le warehouse, puis on les transforme directement avec la puissance de calcul du cloud. Plus besoin de serveurs ETL dédiés.
💡 En pratique
L'approche ELT réduit considérablement le time-to-value : les données sont disponibles dans le warehouse en quelques minutes, et les transformations peuvent être itérées rapidement sans impact sur les systèmes sources.
Ingestion : Fivetran, Airbyte, Meltano
La première brique consiste à extraire les données de vos sources et à les charger dans votre warehouse :
- Fivetran : leader SaaS, 300+ connecteurs, plug-and-play. Cher mais fiable.
- Airbyte : alternative open source, self-hosted ou cloud. Plus flexible, moins cher.
- Meltano : 100 % open source, piloté en CLI, idéal pour les équipes orientées code.
Transformation : dbt, le standard de facto
dbt (data build tool) a révolutionné la transformation de données. Au lieu d'écrire des scripts ETL complexes, on écrit des modèles SQL versionnés, testés et documentés.
Ce que dbt apporte :
- Des transformations écrites en SQL pur (accessibles aux analystes)
- Du versioning Git natif
- Des tests de qualité intégrés (unicité, non-nullité, intégrité référentielle)
- Une documentation auto-générée
- Un lineage complet (d'où vient chaque donnée, comment elle est transformée)
dbt a fait pour la transformation data ce que Git a fait pour le code : rendre les changements traçables, réversibles et collaboratifs.
Orchestration : Airflow, Dagster, Prefect
L'orchestration gère le "quand" et le "dans quel ordre" des pipelines data :
- Apache Airflow : standard historique, puissant mais complexe à opérer.
- Dagster : nouvelle génération, centré sur les "assets" plutôt que les tâches. Plus intuitif.
- Prefect : bon compromis simplicité/puissance, excellente DX.
Stockage et compute : Snowflake, BigQuery, Databricks
Le coeur du modern data stack, c'est un warehouse cloud qui sépare le stockage du calcul :
- Snowflake : polyvalent, multi-tenancy, scaling auto, pricing à la consommation.
- BigQuery : serverless total, pricing au scan, idéal pour le prototypage rapide (écosystème Google Cloud).
- Databricks : le meilleur choix lakehouse, combinant data engineering, data science et ML sur une plateforme unifiée.
Un stack type pour une ETI
Pour une entreprise de taille intermédiaire avec 10 à 50 sources de données, voici un stack éprouvé :
- Ingestion : Airbyte (coût maîtrisé, flexibilité)
- Warehouse : BigQuery ou Snowflake
- Transformation : dbt
- Orchestration : Dagster ou Airflow managé (Cloud Composer, MWAA)
- BI : Metabase, Looker ou Power BI
- Qualité : tests dbt + Great Expectations
Ce stack permet de démarrer en quelques semaines et de scaler progressivement, sans dette technique lourde.
Cas d'usage concrets par secteur
Le data engineering n'est pas un sujet abstrait. Voici comment il crée de la valeur concrète dans différents secteurs.
Retail et e-commerce
Le retail génère des volumes massifs de données transactionnelles, comportementales et logistiques. Le data engineering permet de :
- Unifier les données omnicanales (site web, app mobile, magasins physiques, marketplace) dans un référentiel unique
- Construire des pipelines de recommandation alimentés en temps réel par le comportement d'achat
- Optimiser les stocks en croisant données de vente, prévisions météo, tendances saisonnières
Un de nos clients e-commerce B2B avait ses données éclatées entre Shopify, un ERP maison, Google Analytics et Klaviyo. Quatre sources, quatre vérités. En posant un pipeline ELT vers BigQuery avec dbt, on a créé une source de vérité unique et réduit les ruptures de stock de 25 %.
Industrie et manufacturing
L'industrie produit des données IoT, de production et de qualité en continu. Le data engineering permet de centraliser les données machines (capteurs IoT, SCADA, MES) dans un lakehouse, de construire des pipelines de maintenance prédictive et de piloter la qualité en temps réel avec des alertes sur les dérives de production.
Finance et assurance
Le secteur financier impose une traçabilité complète des données (RGPD, DSP2, Solvabilité II). Le data engineering permet d'automatiser le reporting réglementaire, de détecter la fraude en temps réel via des pipelines de streaming et de construire un scoring crédit alimenté par des données fiabilisées.
Santé et pharma
La santé combine données cliniques et données de recherche avec des exigences de confidentialité maximales. Le data engineering permet de créer des data clean rooms, d'alimenter des modèles prédictifs (durée d'hospitalisation, risque de réadmission) et d'automatiser les reportings cliniques.
📌 A retenir
Quel que soit le secteur, le schéma est le même : sans data engineering fiable, les cas d'usage avancés (IA, prédictif, temps réel) restent des POC qui ne passent jamais en production.
Quand investir dans le data engineering : les signaux qui ne trompent pas
Le data engineering n'est pas un investissement qu'on fait "parce que c'est tendance". C'est un investissement qu'on fait quand le coût de ne pas le faire devient supérieur au coût de le faire.
Voici les signaux concrets que nous observons chez nos clients, juste avant qu'ils décident d'investir.
Signal 1 : vos équipes passent plus de temps à chercher la donnée qu'à l'exploiter
Quand un analyste passe trois heures à réconcilier des exports Excel avant de pouvoir répondre à une question business, le problème n'est pas l'analyste. C'est l'absence de pipeline.
Si vos équipes passent plus de 30 % de leur temps sur la préparation des données, vous perdez de l'argent.
Signal 2 : un même chiffre donne des résultats différents selon la source
Le CA du mois : 1,2 M selon le CRM, 1,15 M selon l'ERP, 1,18 M selon le fichier du DAF. Qui a raison ? Personne ne sait. Tout le monde doute.
Cette situation est le symptôme classique d'une absence de source de vérité unique. Et c'est exactement ce que le data engineering résout.
Signal 3 : vos dashboards sont beaux mais personne ne leur fait confiance
Vous avez investi dans un outil de BI. Les dashboards sont en place. Mais les directeurs continuent de demander des exports manuels "pour vérifier". C'est le signe que les données qui alimentent la BI ne sont pas fiables, et donc que la couche de data engineering est insuffisante.
Signal 4 : vous voulez faire de l'IA mais vos données ne sont pas prêtes
Un projet de data science ou d'IA commence toujours par la même question : est-ce que les données existent, sont accessibles et sont fiables ? Dans 70 % des cas, la réponse est non. Et le projet s'enlise dans des mois de nettoyage et de structuration.
Investir dans le data engineering avant de lancer un projet IA, c'est construire les fondations avant de monter les murs.
Signal 5 : vos sources de données se multiplient sans gouvernance
Chaque nouvel outil SaaS ajoute une source de données. Chaque acquisition ajoute un SI à intégrer. Sans architecture data, cette multiplication crée un spaghetti de flux impossibles à maintenir.
"On voit régulièrement des entreprises qui ont 20, 30 sources de données et aucun pipeline structuré. Elles ne manquent pas de données, elles se noient dedans. Le premier réflexe n'est pas d'en collecter plus, mais de fiabiliser ce qui existe."
-- Cyrille, CEO @ Yield Studio
⚠️ Attention
Ne confondez pas "avoir des données" et "être data-driven". Le premier est un fait. Le second nécessite une infrastructure. Le data engineering est le pont entre les deux.
Comment structurer un projet de data engineering
Un projet de data engineering réussi ne commence pas par le choix d'un outil. Il commence par la compréhension du problème métier à résoudre.
Phase 1 : audit et cadrage (2-3 semaines)
Cartographier l'existant : quelles sources, quel état, quels cas d'usage prioritaires, qui consomme la donnée et sous quelle forme. Ce cadrage permet de dimensionner le projet et de choisir l'architecture adaptée.
Phase 2 : MVP data (4-6 semaines)
On ne construit pas en big bang. On commence par un pipeline de bout en bout (de la source au dashboard), 3 à 5 sources intégrées, des transformations dbt testées et un premier jeu de KPIs exploitables. Ce MVP sert de socle pour itérer.
Phase 3 : industrialisation et scaling
Ajout progressif de sources, orchestration, monitoring, tests de qualité automatisés, documentation et gouvernance des données. L'approche itérative est essentielle : les projets data qui essaient de tout construire d'un coup échouent systématiquement.
Ce que Yield Studio apporte sur les projets data engineering
Chez Yield, on n'aborde pas le data engineering comme un sujet purement technique. On le traite comme un problème produit : quel usage métier veut-on servir, avec quelles données, dans quel délai, et pour quel ROI ?
Notre approche combine :
- Un cadrage métier rigoureux : on ne pose pas un pipeline "parce qu'il faut centraliser". On part du problème à résoudre.
- Une stack éprouvée : dbt, Airflow/Dagster, Snowflake/BigQuery, Airbyte. Des outils solides, maintenables, sans vendor lock-in.
- Un delivery structuré : MVP en 4-6 semaines, itérations courtes, utilisateurs embarqués dès le sprint 1.
- Une vision transverse : data engineering, data science, BI et dataviz. On couvre toute la chaîne de valeur data.
Ce qui fait la différence, ce n'est pas la stack. C'est la méthode : cadrer serré, livrer vite, mesurer l'impact, itérer.
"Sur un projet data, la pire erreur est de passer six mois à construire une plateforme sans avoir livré une seule donnée exploitable aux métiers. Chez nous, le premier pipeline tourne en moins de quatre semaines. C'est là que la valeur commence."
-- James, CTO @ Yield Studio
Vous avez des données dispersées, des dashboards auxquels personne ne fait confiance, ou un projet IA qui patine faute de fondations data ? Parlons-en. On peut poser un diagnostic clair en quelques jours et vous proposer un plan d'action concret.
Découvrez aussi notre article sur les meilleures agences data en France pour mieux comprendre ce qui fait un bon partenaire data.
👉 Contactez notre équipe data engineering pour en discuter.