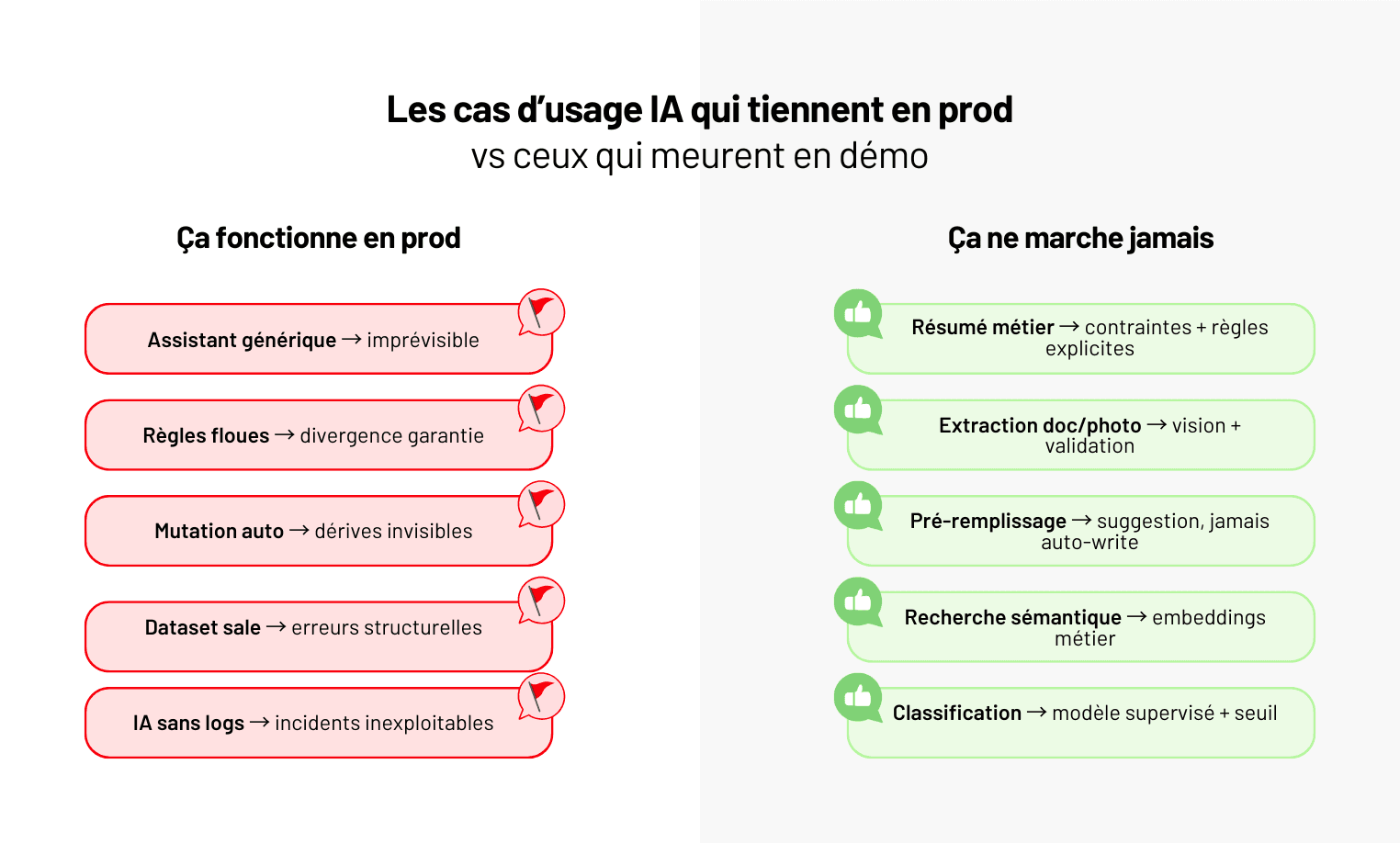
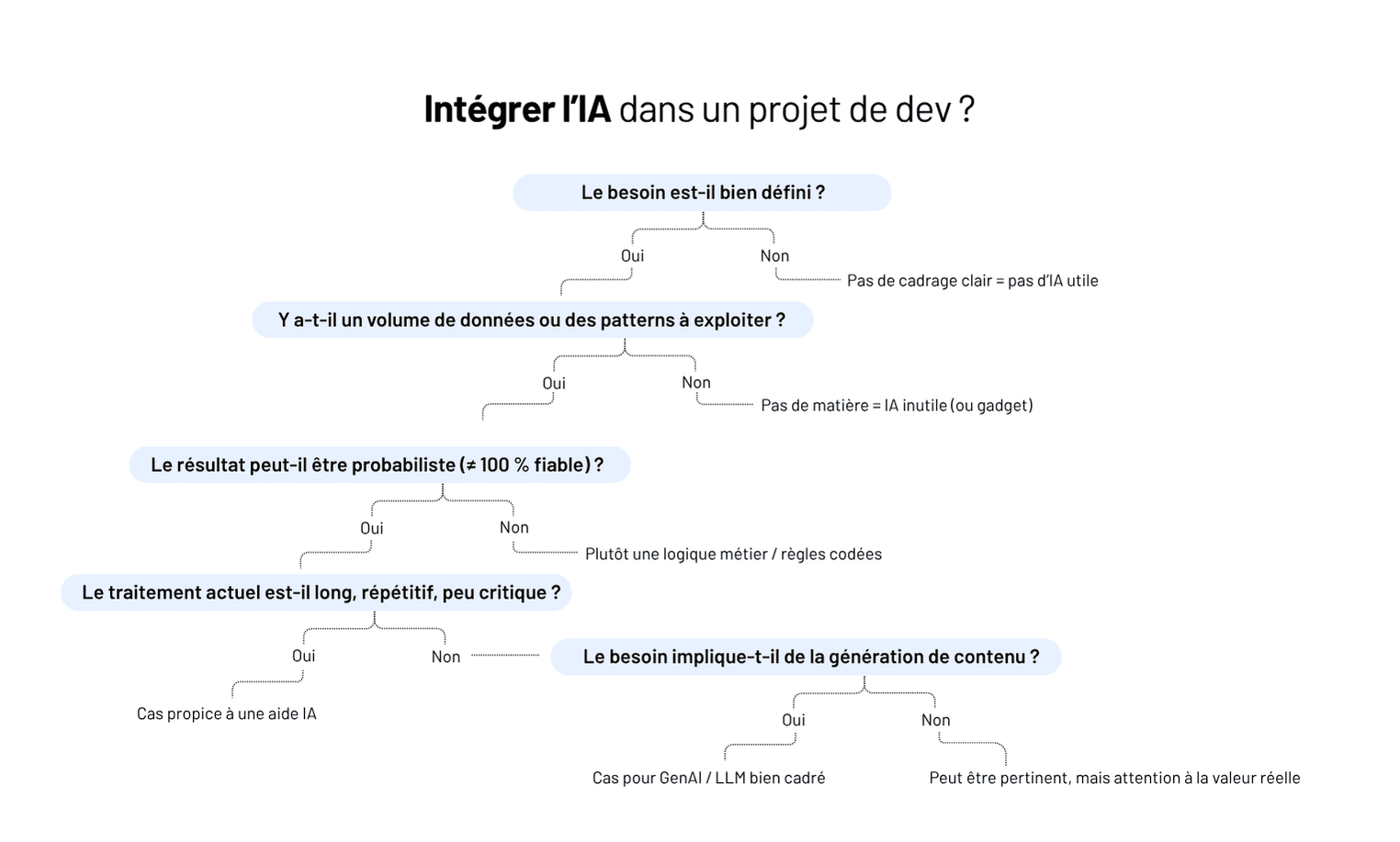
Depuis l'arrivée de ChatGPT, une question revient dans presque toutes les directions techniques et métier : comment exploiter l'IA générative sur nos propres données ?
La réponse la plus robuste aujourd'hui s'appelle RAG : Retrieval Augmented Generation. Derrière cet acronyme se cache une architecture qui permet de connecter un modèle de langage (LLM) à vos données internes, sans avoir à le ré-entraîner.
Le principe est simple : au lieu de demander au modèle de tout savoir, on lui fournit les bonnes informations au bon moment. Il génère sa réponse en s'appuyant sur des documents réels, pas sur sa mémoire statistique.
Sur le papier, c'est séduisant. Sur le terrain, c'est plus nuancé. Le RAG n'est ni magique ni trivial. Il suppose des choix d'architecture, une qualité de données suffisante et une compréhension claire de ce qu'il peut (et ne peut pas) faire.
Dans cet article, on pose les bases : comment fonctionne le RAG, quelles architectures mettre en place, dans quels cas il crée de la valeur, et quelles sont ses limites réelles. Le tout avec un regard pragmatique, orienté entreprise.
Qu'est-ce que le RAG (Retrieval Augmented Generation) ?
Le RAG est un pattern d'architecture qui combine deux mécanismes distincts pour produire des réponses fiables à partir de données spécifiques.
Le problème de base : un LLM ne connaît pas vos données
Un modèle de langage comme GPT-4 ou Claude est entraîné sur des corpus publics massifs. Il connaît beaucoup de choses, mais pas vos documents internes, vos procédures, vos contrats, vos bases de connaissances métier.
Lui poser une question sur votre organisation revient à interroger un expert brillant, mais qui n'a jamais lu un seul de vos documents.
Deux solutions existent pour pallier ce problème :
- le fine-tuning : ré-entraîner le modèle sur vos données (coûteux, complexe, rigide) ;
- le RAG : injecter les bonnes informations dans le prompt au moment de la requête.
Retrieval + Generation : le fonctionnement en deux temps
Le RAG fonctionne en deux étapes distinctes :
1. Retrieval (recherche)
Quand un utilisateur pose une question, le système cherche dans votre base documentaire les passages les plus pertinents. Cette recherche repose sur la similarité sémantique, pas sur des mots-clés exacts. On compare le sens de la question avec le sens des documents.
2. Generation (génération)
Les passages retrouvés sont injectés dans le contexte du LLM, qui génère une réponse en s'appuyant sur ces informations concrètes. Le modèle ne devine plus : il synthétise à partir de sources identifiées.
"Le RAG change fondamentalement la proposition de valeur de l'IA générative en entreprise. On passe d'un modèle qui invente à un modèle qui s'appuie sur vos données réelles. La nuance est énorme."
— James, CTO @ Yield Studio
💡 En résumé
Le RAG ne rend pas le LLM plus intelligent. Il le rend plus pertinent, en lui donnant accès aux bonnes informations au bon moment. C'est un problème d'architecture, pas de modèle.
Architecture technique d'un système RAG
Derrière le concept, un système RAG repose sur plusieurs briques techniques qui doivent fonctionner ensemble. Chacune a ses choix, ses compromis et ses pièges.
Les embeddings : transformer le texte en vecteurs
Pour comparer le sens d'une question avec celui d'un document, il faut d'abord convertir le texte en représentations numériques : les embeddings.
Un modèle d'embedding (comme text-embedding-3-large d'OpenAI ou les modèles open source type Sentence Transformers) transforme chaque passage de texte en un vecteur de plusieurs centaines de dimensions. Deux textes sémantiquement proches produisent des vecteurs proches.
C'est cette proximité mathématique qui permet la recherche sémantique, au-delà de la correspondance exacte de mots.
Le chunking : découper les documents intelligemment
Un document de 50 pages ne peut pas être traité d'un bloc. Il faut le découper en chunks (fragments) suffisamment petits pour être pertinents, mais suffisamment grands pour conserver du contexte.
Les stratégies de chunking varient :
- par taille fixe (ex. 500 tokens avec chevauchement) : simple mais aveugle au contenu ;
- par structure (titres, paragraphes, sections) : plus pertinent pour les documents structurés ;
- sémantique : découpage intelligent basé sur les ruptures de sens.
Le choix du chunking a un impact direct sur la qualité des résultats. Un mauvais découpage produit des fragments hors contexte, et donc des réponses approximatives.
⚠️ Piège fréquent
Un chunking trop fin perd le contexte. Un chunking trop large noie l'information pertinente dans du bruit. Il n'existe pas de taille universelle : il faut tester et itérer selon vos données.
La base vectorielle : stocker et interroger les embeddings
Les vecteurs produits doivent être stockés dans une base optimisée pour la recherche par similarité. C'est le rôle des vector databases.
Les principales options :
- Pinecone : service managé, simple à démarrer, performant en production ;
- Weaviate : open source, riche en fonctionnalités (filtrage hybride, multimodal) ;
- pgvector : extension PostgreSQL, idéale pour les équipes qui veulent rester sur une stack connue ;
- Qdrant, Milvus, ChromaDB : autres alternatives selon les contraintes.
Le choix dépend du volume de données, des contraintes d'hébergement (cloud vs on-premise), et de la maturité de l'équipe.
Le prompt engineering : assembler le contexte pour le LLM
Une fois les passages pertinents récupérés, il faut construire un prompt efficace pour le LLM. Ce prompt contient :
- les instructions système (rôle, contraintes, format de réponse) ;
- les chunks retrouvés (le contexte documentaire) ;
- la question de l'utilisateur.
Le prompt engineering dans un RAG est critique. Il définit comment le modèle utilise (ou ignore) le contexte fourni. Un mauvais prompt peut amener le modèle à halluciner malgré un contexte correct.
L'orchestration : LangChain, LlamaIndex et alternatives
Pour assembler ces briques, des frameworks d'orchestration simplifient le développement :
- LangChain : le plus populaire, très flexible, large écosystème. Parfois critiqué pour sa complexité sur les cas simples ;
- LlamaIndex : plus spécialisé sur l'indexation et la recherche documentaire. Excellent pour les cas RAG purs ;
- Haystack (deepset) : alternative mature, orientée production.
Sur les projets simples, un pipeline custom sans framework peut suffire. Sur les projets complexes avec plusieurs sources de données, un framework devient vite indispensable.
📌 Architecture type d'un RAG
Documents source → Chunking → Embeddings → Vector DB → Requête utilisateur → Recherche sémantique → Contexte + Question → LLM → Réponse augmentée
Cas d'usage concrets du RAG en entreprise
Le RAG prend toute sa valeur quand il est appliqué à des problèmes métier concrets, là où l'accès à l'information est un frein réel. Voici les cas d'usage les plus matures aujourd'hui.
1. Documentation interne et base de connaissances
C'est le cas d'usage le plus naturel du RAG. Les entreprises accumulent des milliers de documents : procédures, guides techniques, politiques internes, wikis, Confluence, Notion.
Personne ne les lit. Tout le monde cherche l'information en demandant à un collègue.
Un système RAG branché sur cette documentation permet aux collaborateurs de poser des questions en langage naturel et d'obtenir des réponses sourcées, avec les références exactes. Au lieu de chercher dans 15 documents, on obtient une synthèse contextuelle en quelques secondes.
Gain concret : réduction du temps de recherche d'information, onboarding accéléré, moins de dépendance aux sachants.
2. Support client augmenté
Les équipes support gèrent des volumes croissants de demandes, souvent répétitives. Le RAG permet de construire des chatbots capables de répondre aux questions fréquentes en s'appuyant sur la documentation produit, les FAQ, les tickets résolus.
Contrairement à un chatbot classique basé sur des arbres de décision, un chatbot RAG comprend les questions formulées librement et peut traiter des cas non prévus explicitement.
Gain concret : réduction du volume de tickets L1, réponses plus rapides et plus complètes, montée en compétence des agents sur les cas complexes.
"Sur un projet de support client, le RAG a permis de passer de 45 % à 78 % de réponses automatisées pertinentes en trois mois. La clé n'était pas le modèle, c'était la qualité de la base documentaire qu'on lui fournissait."
— Julien, Lead Product @ Yield Studio
3. Analyse juridique et réglementaire
Les directions juridiques, conformité et réglementaire croulent sous les textes : contrats, CGV, réglementations sectorielles, jurisprudences. Le RAG permet d'interroger ces corpus en langage naturel.
Un juriste peut poser une question précise ("Quelles sont nos obligations de notification en cas de violation de données selon notre contrat avec le client X ?") et obtenir une réponse contextualisée, avec les clauses exactes citées.
Gain concret : analyse contractuelle accélérée, veille réglementaire plus efficace, réduction du risque d'oubli sur des clauses critiques.
⚠️ Attention
Le RAG ne remplace pas l'expertise juridique. Il accélère l'accès à l'information. La validation humaine reste indispensable sur les sujets sensibles.
4. Knowledge management et capitalisation
Dans les organisations qui produisent beaucoup de savoir (cabinets de conseil, ESN, bureaux d'études), la capitalisation est un enjeu permanent. Les retours d'expérience, les propositions commerciales, les livrables passés sont rarement réutilisés.
Le RAG permet de rendre ce patrimoine interrogeable : "On a déjà travaillé sur un projet similaire dans le secteur bancaire ?", "Quelle approche a été retenue pour la migration cloud du client Y ?"
Gain concret : réutilisation des connaissances, gains de temps en avant-vente, meilleure cohérence des livrables.
5. Autres cas d'usage émergents
Au-delà de ces cas matures, le RAG s'applique aussi à :
- la formation interne : assistant de formation qui répond aux questions à partir des supports pédagogiques ;
- le pilotage de projet : interrogation des comptes-rendus, décisions, risques identifiés ;
- la R&D : exploration de la littérature scientifique et technique.
Pour approfondir comment l'IA s'intègre dans les logiciels métier, nous avons détaillé les approches concrètes dans cet article sur l'IA dans les logiciels métier.
RAG vs fine-tuning : quand choisir quoi ?
C'est la question que posent presque tous les décideurs techniques au moment de lancer un projet d'IA générative. La réponse n'est pas universelle, mais les critères de choix sont clairs.
Le fine-tuning : modifier le modèle lui-même
Le fine-tuning consiste à ré-entraîner un LLM sur un dataset spécifique pour qu'il intègre de nouvelles connaissances ou adopte un style particulier.
Quand c'est pertinent :
- adapter le ton, le format ou le style de réponse (ex. chatbot avec une personnalité de marque) ;
- apprendre un vocabulaire métier très spécifique que le modèle ne comprend pas du tout ;
- quand les données changent rarement et que la performance doit être maximale.
Les limites :
- coûteux en compute et en expertise ;
- nécessite un dataset de qualité ;
- rigide : chaque mise à jour des données impose un nouvel entraînement ;
- risque d'overfitting (le modèle perd en capacité générale).
Le RAG : enrichir le contexte sans toucher au modèle
Quand c'est pertinent :
- les données évoluent fréquemment (documentation, procédures, base de connaissances) ;
- on veut pouvoir citer les sources et tracer l'origine des réponses ;
- on a besoin de résultats rapides sans investir dans l'entraînement ;
- la transparence est un enjeu (conformité, audit).
Les limites :
- la qualité dépend entièrement de la base documentaire ;
- les hallucinations ne sont pas totalement éliminées ;
- la fenêtre de contexte du LLM impose des contraintes de volume.
En pratique : le RAG d'abord, le fine-tuning ensuite
Dans la très grande majorité des projets que nous accompagnons chez Yield Studio, le RAG est le bon point de départ. Il permet de valider rapidement la valeur d'un cas d'usage avec un investissement maîtrisé.
Le fine-tuning intervient dans un second temps, quand le RAG a prouvé sa valeur et que des optimisations spécifiques sont nécessaires.
Pour mieux comprendre les différences entre IA classique, machine learning et IA générative, consultez notre guide complet sur les choix IA.
💡 Règle pragmatique
Commencez par le RAG. Si les résultats sont bons à 80 %, optimisez le pipeline (chunking, prompt, reranking). Ne passez au fine-tuning que si le RAG atteint un plafond que l'architecture seule ne peut pas dépasser.
Les limites honnêtes du RAG
Le RAG est un outil puissant, mais ce n'est pas une solution miracle. Ignorer ses limites, c'est s'exposer à des déceptions coûteuses. Voici les points de vigilance réels.
Les hallucinations résiduelles
Le RAG réduit considérablement les hallucinations par rapport à un LLM utilisé seul. Mais il ne les élimine pas totalement.
Le modèle peut :
- extrapoler au-delà de ce que dit le contexte fourni ;
- mélanger des informations provenant de chunks différents ;
- inventer des détails quand le contexte est insuffisant.
Pour limiter ce risque, il faut travailler le prompt (instructions strictes de ne répondre qu'à partir du contexte), ajouter des mécanismes de vérification, et toujours permettre à l'utilisateur de consulter les sources.
La qualité des données source
Un RAG n'est jamais meilleur que les données qu'on lui fournit. C'est la limite la plus sous-estimée.
Si votre documentation est :
- obsolète ;
- contradictoire ;
- mal structurée ;
- incomplète,
le RAG produira des réponses obsolètes, contradictoires, mal structurées et incomplètes. Avec une mise en forme impeccable qui donne l'illusion de fiabilité.
"Le plus gros chantier sur un projet RAG, ce n'est jamais le pipeline technique. C'est la qualité des données. On passe souvent plus de temps à nettoyer, structurer et mettre à jour la base documentaire qu'à coder le système lui-même."
— James, CTO @ Yield Studio
Les coûts en production
Un système RAG en production a des coûts récurrents qu'il faut anticiper :
- appels au LLM : chaque requête consomme des tokens (entrée + sortie). Sur des volumes importants, la facture grimpe vite ;
- embeddings : le calcul initial est ponctuel, mais chaque mise à jour documentaire nécessite un recalcul ;
- vector database : le stockage et les requêtes ont un coût, surtout sur les services managés ;
- maintenance : mise à jour des documents, monitoring de la qualité des réponses, évolution du pipeline.
Sur un projet d'envergure, il est courant de voir des coûts mensuels de plusieurs milliers d'euros uniquement pour l'infrastructure RAG.
La fenêtre de contexte
Même si les fenêtres de contexte des LLM s'élargissent (128K tokens pour GPT-4, 200K pour Claude), elles restent finies. Plus on injecte de contexte, plus le modèle risque de perdre en précision sur les détails.
Un bon RAG ne cherche pas à injecter le maximum de contexte. Il cherche à injecter le contexte le plus pertinent, en quantité maîtrisée.
La sécurité et la confidentialité
Brancher un LLM sur des données internes pose des questions légitimes :
- où transitent les données ? Quels modèles, quels hébergeurs ?
- qui peut accéder à quelles informations via le RAG ?
- comment gérer les droits d'accès documentaires ?
Ces questions ne sont pas techniques : elles sont organisationnelles et juridiques. Un RAG mal conçu peut devenir un vecteur de fuite d'information si les droits d'accès ne sont pas respectés dans le pipeline.
⚠️ Point critique
Un RAG sans gestion des droits d'accès est un risque de sécurité. Si un utilisateur peut obtenir via le chatbot des informations auxquelles il n'a pas accès directement, vous avez un problème.
Mettre en place un RAG : la stack technique et les bonnes pratiques
Passer du concept à la production suppose des choix techniques clairs. Voici les composants et les pratiques qui font la différence entre un POC convaincant et un système fiable.
La stack type
Un pipeline RAG robuste repose sur ces briques :
- LLM : OpenAI (GPT-4o, GPT-4), Anthropic (Claude), ou modèles open source (Mistral, Llama) selon les contraintes de souveraineté ;
- Modèle d'embeddings : OpenAI text-embedding-3, Cohere embed, ou modèles open source ;
- Vector database : Pinecone, Weaviate, pgvector, Qdrant selon le contexte ;
- Orchestration : LangChain, LlamaIndex, ou pipeline custom ;
- Ingestion : pipeline de traitement documentaire (parsing PDF, extraction de texte, nettoyage).
Les patterns avancés
Au-delà du RAG basique, plusieurs patterns améliorent significativement les résultats :
- Hybrid search : combiner recherche sémantique (vecteurs) et recherche lexicale (BM25) pour couvrir à la fois le sens et les termes exacts ;
- Reranking : après la recherche initiale, utiliser un modèle de reranking pour réordonner les résultats par pertinence réelle ;
- Query expansion : reformuler ou enrichir la question de l'utilisateur avant la recherche pour améliorer le recall ;
- Metadata filtering : associer des métadonnées aux chunks (date, source, catégorie) pour filtrer avant la recherche sémantique.
Les bonnes pratiques terrain
Les projets RAG qui tiennent en production partagent ces caractéristiques :
- Commencer petit : un périmètre documentaire restreint, un cas d'usage précis, des utilisateurs pilotes identifiés ;
- Mesurer la qualité : mettre en place des métriques de pertinence (relevance, faithfulness, answer correctness) et les suivre dans le temps ;
- Itérer sur les données : le plus gros levier d'amélioration n'est pas le modèle ou le framework, c'est la qualité et la fraîcheur de la base documentaire ;
- Prévoir la maintenance : un RAG n'est pas un projet one-shot. Les documents changent, les modèles évoluent, les usages se précisent.
📌 Checklist avant de lancer un RAG
Avant de coder, vérifiez que vous avez : un cas d'usage clair avec un ROI identifiable, une base documentaire de qualité suffisante, un sponsor métier engagé, et une équipe capable de maintenir le système dans la durée.
Conclusion : le RAG est un levier puissant, pas une baguette magique
Le RAG est aujourd'hui l'approche la plus pragmatique pour exploiter l'IA générative sur des données d'entreprise. Il permet de construire des systèmes qui répondent avec pertinence, en s'appuyant sur des sources identifiées, sans ré-entraîner de modèle.
Mais sa réussite repose sur des fondamentaux souvent négligés :
- la qualité des données avant tout ;
- une architecture bien dimensionnée, ni trop simple ni trop ambitieuse ;
- un cas d'usage concret qui justifie l'investissement ;
- une capacité à itérer et à maintenir le système dans la durée.
Chez Yield Studio, on accompagne les entreprises dans la conception et le déploiement de systèmes RAG, du cadrage initial à la mise en production. Pas pour mettre de l'IA partout, mais pour résoudre des problèmes concrets avec une approche maîtrisée.
👉 Vous avez un cas d'usage en tête et vous voulez évaluer si le RAG est la bonne approche ? Parlons-en. On peut vous aider à cadrer le projet, choisir la bonne architecture et éviter les écueils classiques.