

Cyrille
Chief Product Officer & Co-Founder
Articles de Cyrille

Agentforce : le guide complet des agents IA autonomes dans Salesforce
Qu'est-ce qu'Agentforce ? Comment déployer des agents IA autonomes dans Salesforce pour automatiser la qualification de leads, le support client et les relances. Guide complet.

Automatiser Salesforce avec l'IA : Flows, Agentforce et cas d'usage concrets
Comment automatiser vos processus Salesforce avec l'IA : comparaison Flows vs Agentforce, 5 cas d'usage concrets avec ROI, et méthode de mise en place étape par étape.

Intégrateur Salesforce : comment choisir et réussir l'intégration de votre CRM
Comment choisir un intégrateur Salesforce ? Critères de sélection, étapes de migration, budget, pièges à éviter. Guide complet pour réussir votre projet CRM.

Top 10 des agences de développement web en France (2026)
Comparatif des 10 meilleures agences de développement web en France. Yield Studio, Galadrim, Theodo, Hello Pomelo... Notre classement détaillé.

Tableaux de bord BI : outils, méthodes et pièges à éviter
Dashboard BI entreprise : comparatif Power BI, Looker, Metabase et sur-mesure. Méthodes pour choisir vos KPIs, éviter les vanity metrics et construire des tableaux de bord qui servent vraiment vos décisions.
Due diligence IT : ce que les investisseurs vérifient (et comment s'y préparer)
Due diligence informatique : les 8 axes d'analyse vérifiés par les investisseurs (architecture, dette technique, sécurité, RGPD...) et comment préparer votre entreprise avant une levée de fonds ou un M&A.

Combien coute un site e-commerce sur mesure en 2026 ?
Cout d'un site e-commerce en 2026 : SaaS, Prestashop ou full custom. Comparatif des prix, couts caches et criteres de choix pour decideurs.
Prestashop vs Shopify vs sur-mesure : comment choisir sa solution e-commerce
Comparatif détaillé Prestashop, Shopify, WooCommerce et sur-mesure. Prix, flexibilité, scalabilité, SEO, TCO sur 3 ans. Guide pour choisir la bonne plateforme e-commerce.

ERP PME : optimisez vos processus et réduisez vos coûts
Un ERP est redoutablement efficace pour une chose : exécuter un cadre.
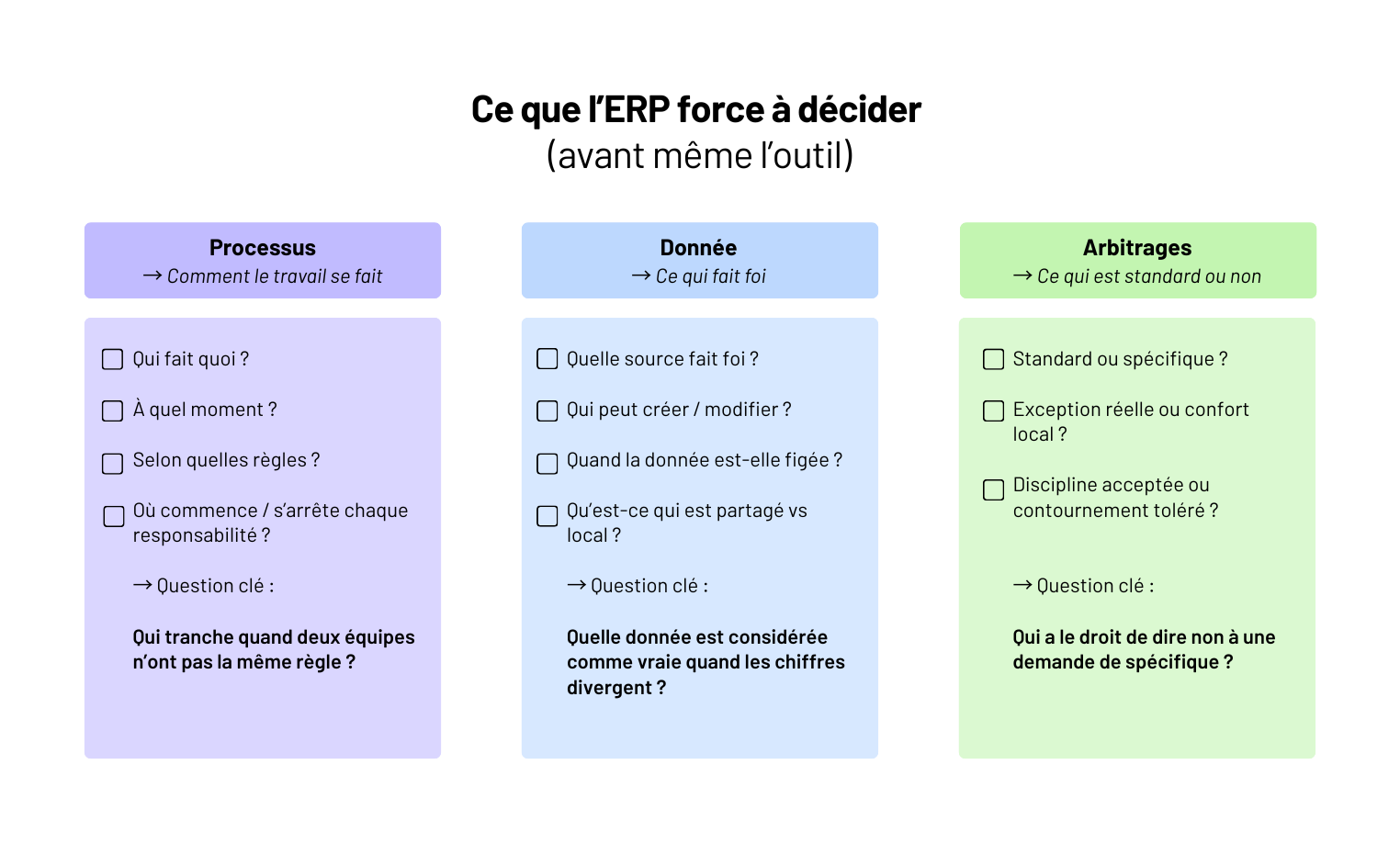
Comment fonctionne la mise en place d'un ERP ?
Mettre en place un ERP, ce n’est pas déployer un outil transverse. C’est transformer des pratiques implicites en règles explicites. Et accepter que certaines façons de faire ne survivront pas au projet.

Kubernetes : c’est quoi, à quoi ça sert, et quand (ne pas) l’utiliser ?
Dans ce guide : ce que Kube est vraiment, ce qu’il apporte, les cas où il sert, ceux où il faut l’éviter - et comment décider sans se tromper.

Pourquoi choisir un logiciel sur-mesure plutôt qu’un SaaS ?
Un SaaS, c’est parfait… tant que votre métier rentre dans son cadre. Dès que vos process deviennent spécifiques, il vous ralentit : rigidité, dépendance, coûts cachés, contournements.

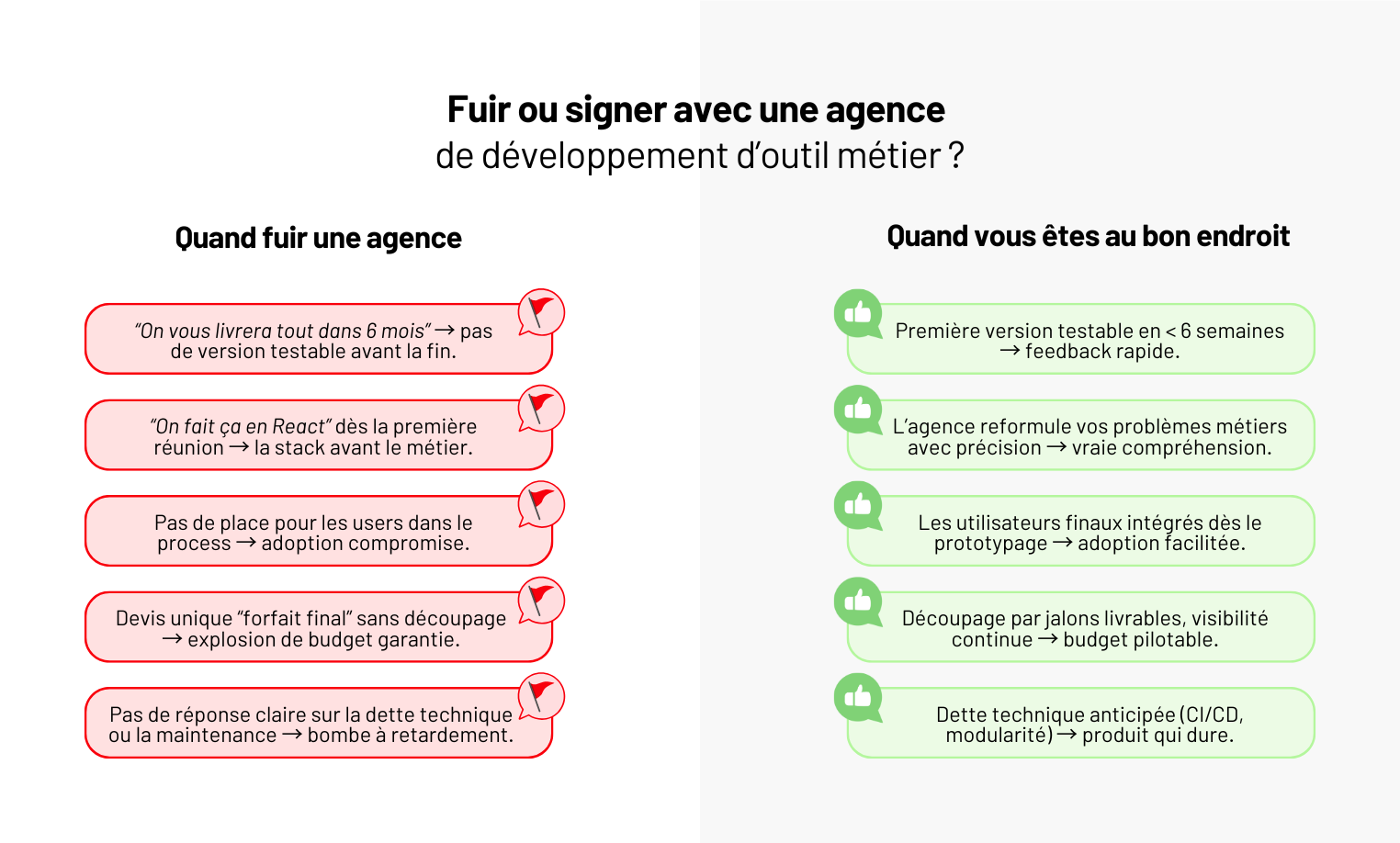
Comment choisir une agence de développement web ?
Dans cet article, on met les mains dans le cambouis : comment éviter les mauvaises agences, repérer les bonnes, comparer deux propositions sans être dev… et surtout choisir un partenaire qui ne fera pas exploser votre budget (ni votre produit).

Comptabiliser un logiciel développé en interne : comment faire
Entre phase de recherche, phase de développement, conditions de capitalisation, amortissement, PCG, TVA, fiscalité… beaucoup d’équipes se retrouvent à naviguer à vue.

Comment amortir un logiciel ? Méthodes et conseils pratiques
Dans cet article, on clarifie à la fois l’aspect comptable (durées, règles, méthodes)… et ce que ça change concrètement pour votre produit.
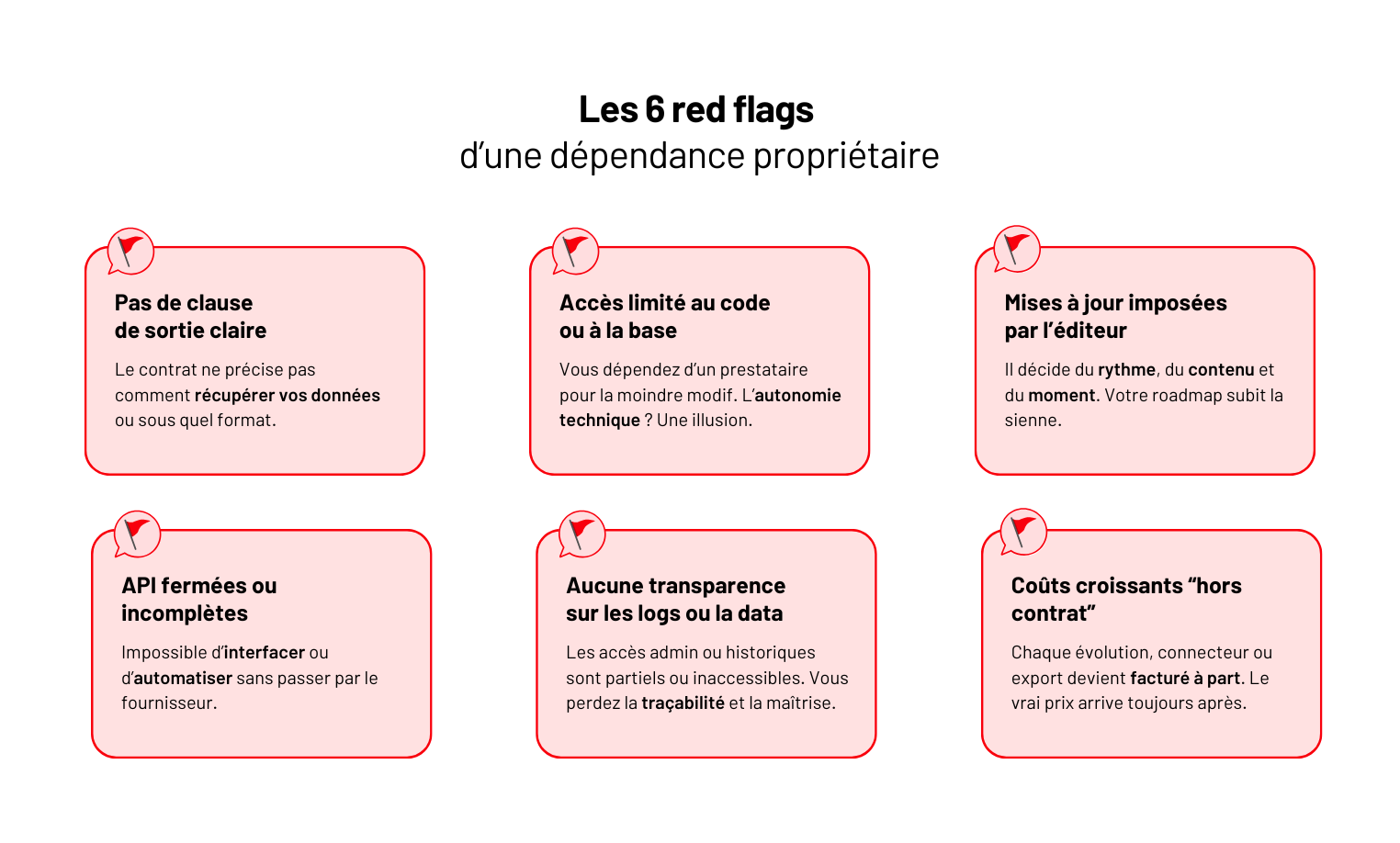
Logiciel propriétaire : Définition et implications pour votre entreprise
Dans cet article, on pose les bases : ce qu’est réellement un logiciel propriétaire, ce qu’il implique pour votre entreprise, et comment garder la main sans tout réinventer.

Micro-frontends et architectures modulaires : l’avenir du développement logiciel d’entreprise
Sur le papier, tout s’aligne.Mais la réalité, on la voit tous les jours chez nos clients : un micro-frontend mal cadré, c’est juste un micro-monolithe. Un puzzle plus complexe, pas un système plus sain.

Budget limité, ambitions fortes : comment réussir son premier produit digital quand on est une PME ou une ETI ?
Dans cet article, on vous donne une méthode concrète pour cadrer, prioriser et livrer utile — même avec des moyens limités.

Logiciel sur-mesure ou SaaS existant : comment faire le bon choix ?
Vous cherchez un outil pour structurer votre activité : CRM, plateforme interne, gestion RH, production… Et très vite, la question arrive : “On prend une solution SaaS du marché, ou on fait développer un logiciel sur-mesure ?”

Qu'est-ce qu'un logiciel sur mesure ?
Cet article clarifie le sujet : ce qu’est un logiciel sur-mesure, dans quels cas il devient pertinent, et surtout comment en sécuriser la conception et la gouvernance.
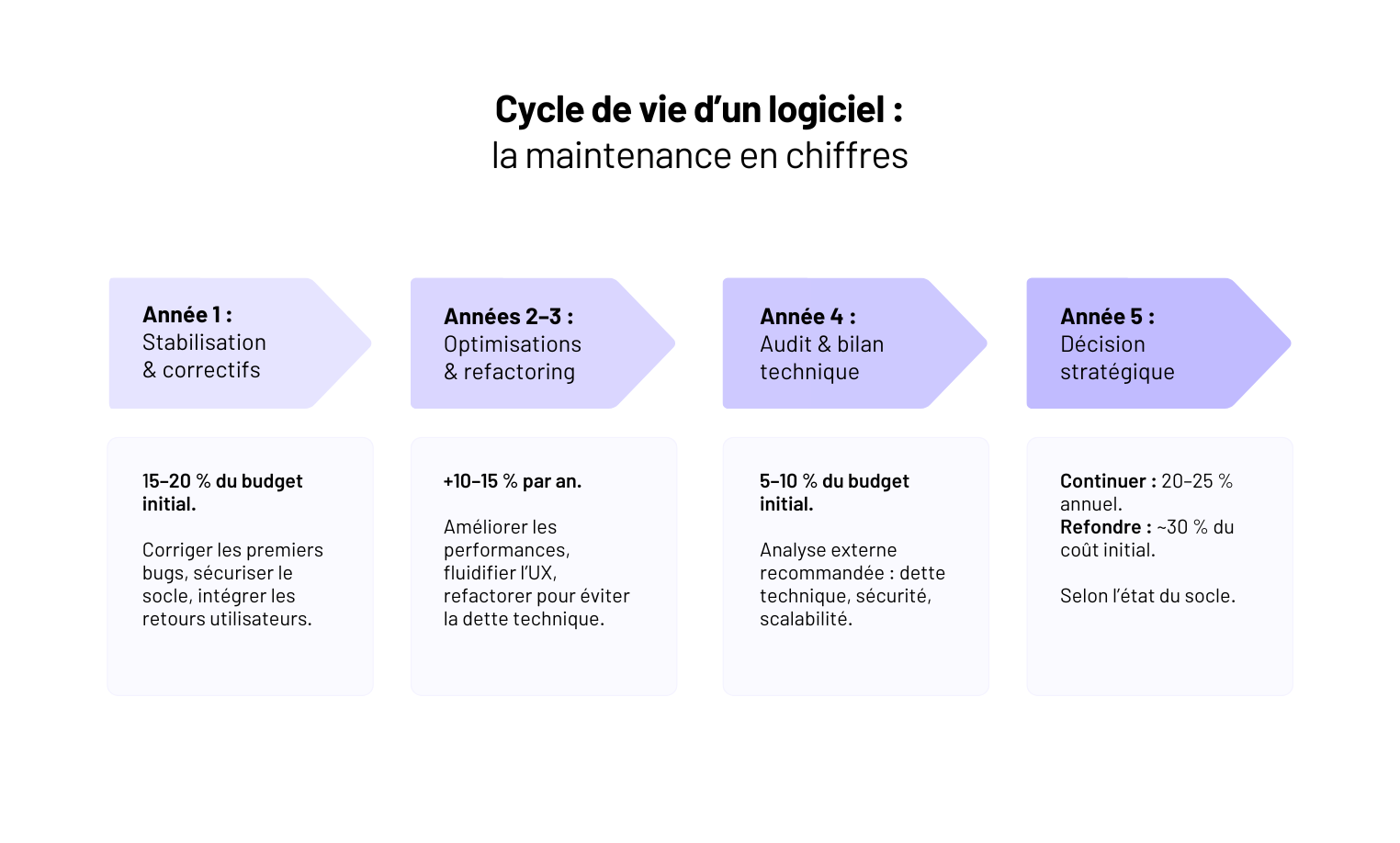
Combien coûte la maintenance d'un logiciel sur-mesure ?
La maintenance reste souvent un angle mort. Les dirigeants budgètent le développement… et sous-estiment les coûts de run. Résultat : dette technique qui explose, mises en production bloquées, ou refontes précipitées qui coûtent 3× plus cher.

Top 5 des meilleures agences web
Le marché est saturé. Des agences vitrines, des usines à sites, des freelances déguisés en studios. Alors comment faire le tri ?
Top 5 des meilleures agences de développement d'application métier
Dans ce top, nous avons retenu 5 agences qui comptent aujourd’hui dans ce domaine. Chacune a son ADN, ses forces, et les contextes où elle excelle.
Top 5 des meilleures agences de développement d'outil métier
Dans ce top, nous avons retenu 5 agences spécialisées dans le développement d’outils métier. Pas les plus “hype”, mais celles qui livrent des produits robustes, adaptés, adoptés. Chacune avec ses points forts, et les contextes où elle fait la différence.
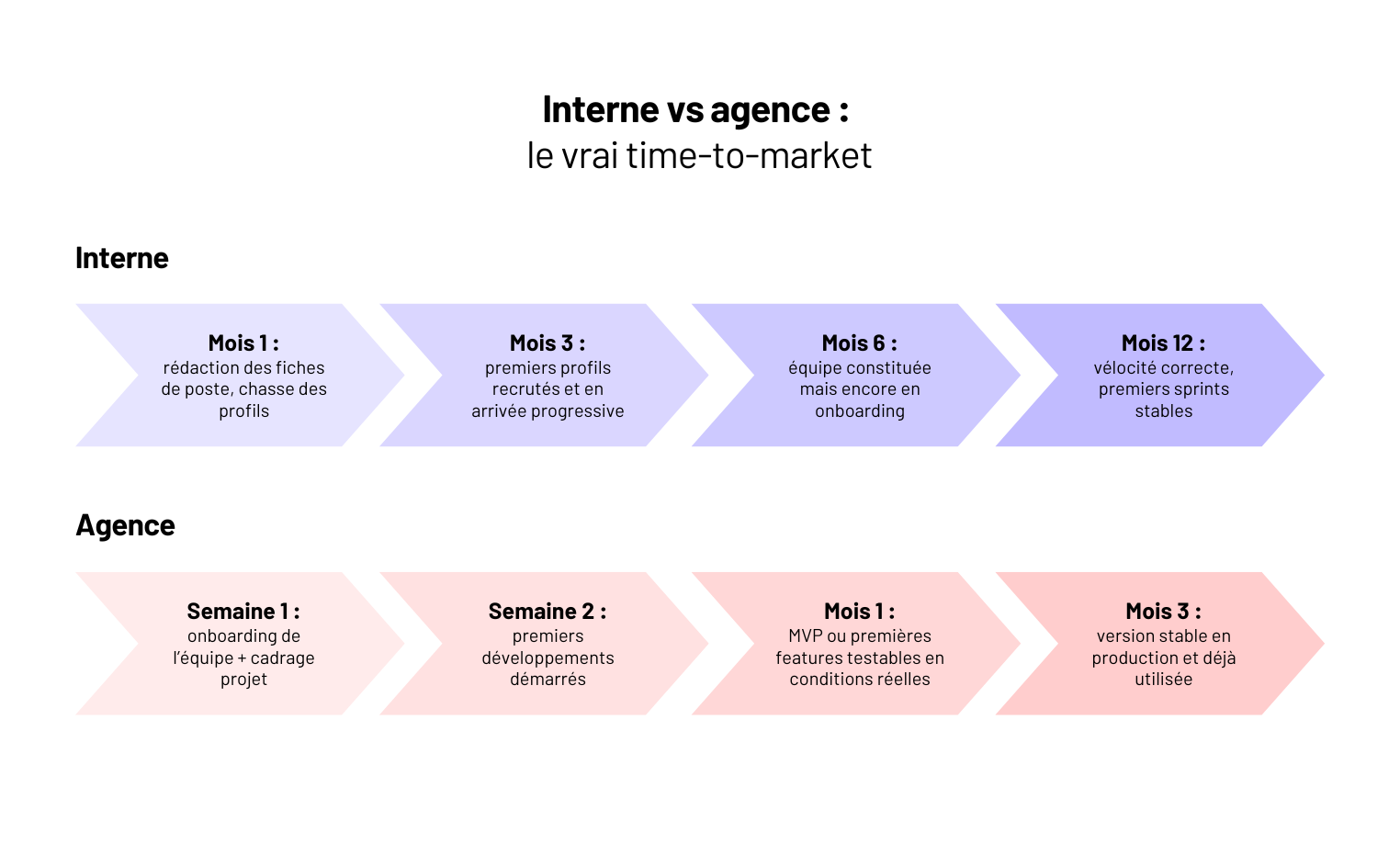
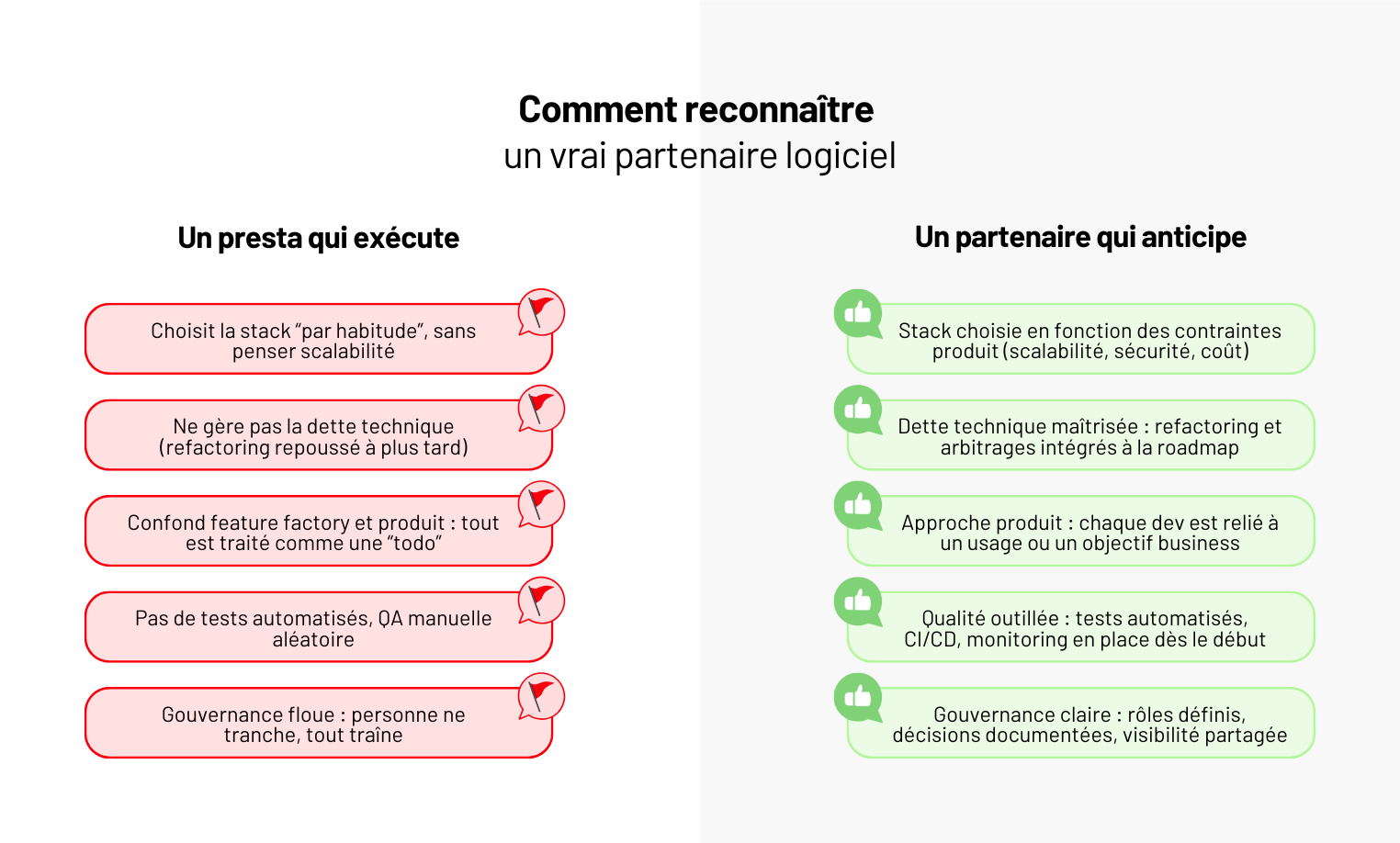
Pourquoi externaliser le développement d’un logiciel à une agence plutôt qu’en interne ?
Externaliser, ce n’est pas déléguer son produit. C’est accélérer sa trajectoire en s’appuyant sur un partenaire qui a déjà fait ce chemin.
Top 5 des meilleures agences de développement logiciel
Ce top 5 ne distribue pas de médailles. Il met en lumière cinq agences qui comptent en France aujourd’hui, chacune avec son ADN, ses forces, et les contextes où elle excelle.
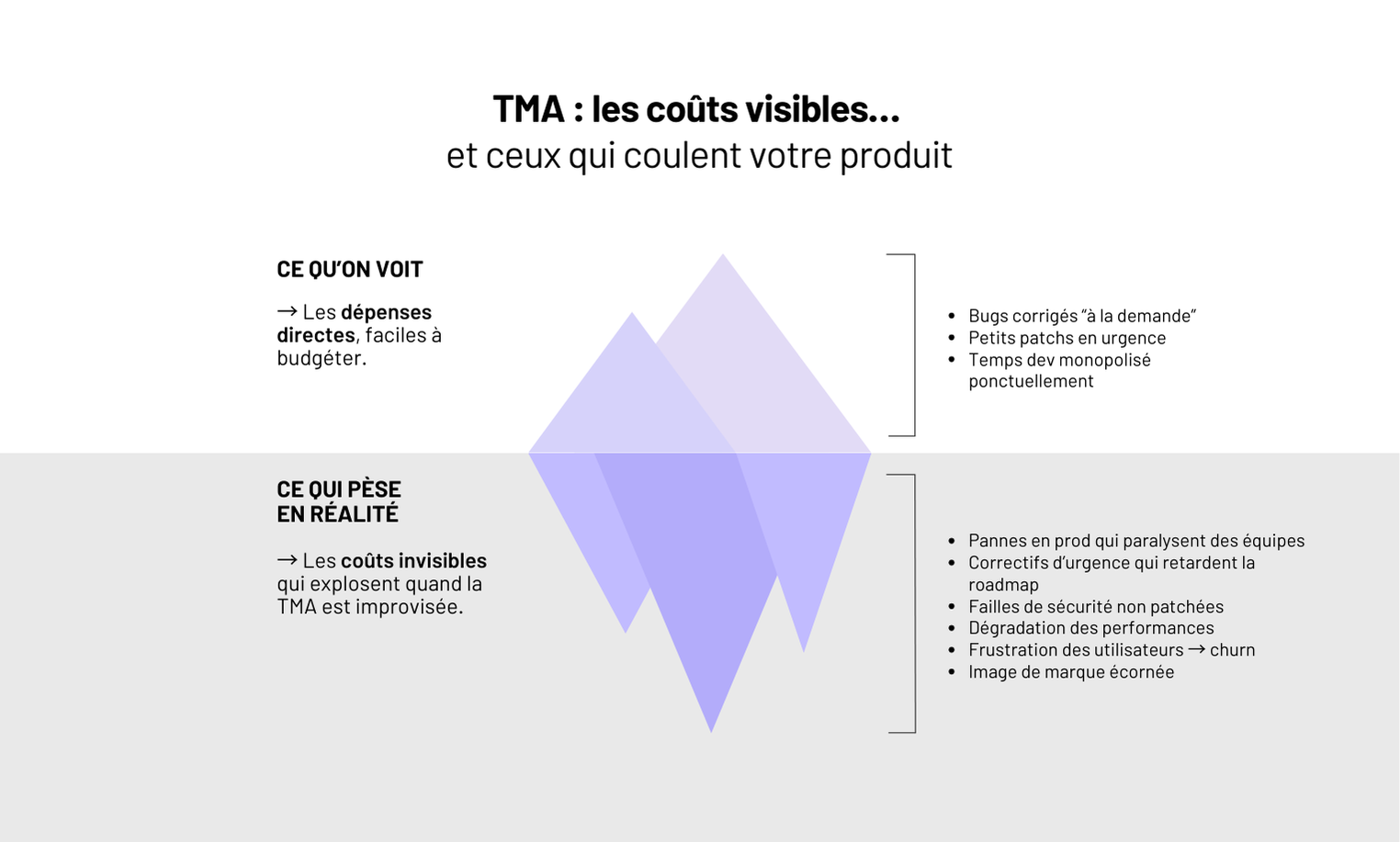
TMA (Tierce Maintenance Applicative) d’une application web : Guide complet
Dans ce guide, on partage notre expérience terrain pour transformer la TMA en avantage compétitif
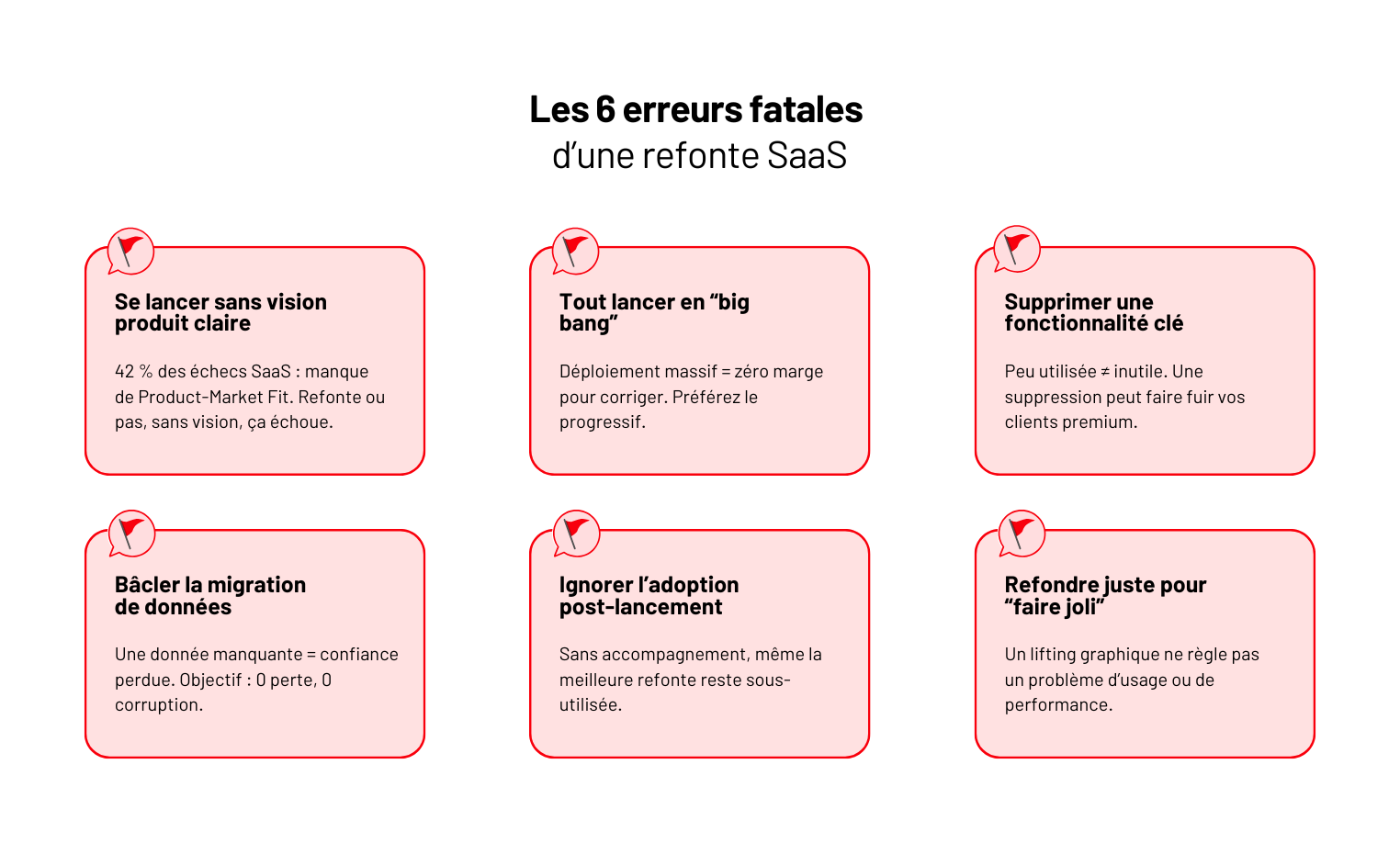
Refonte d'application web (SaaS) : Guide complet
Ce guide propose un chemin structuré, issu de plus de 10 ans de développement d’application web et de refontes menées côté éditeur et côté presta
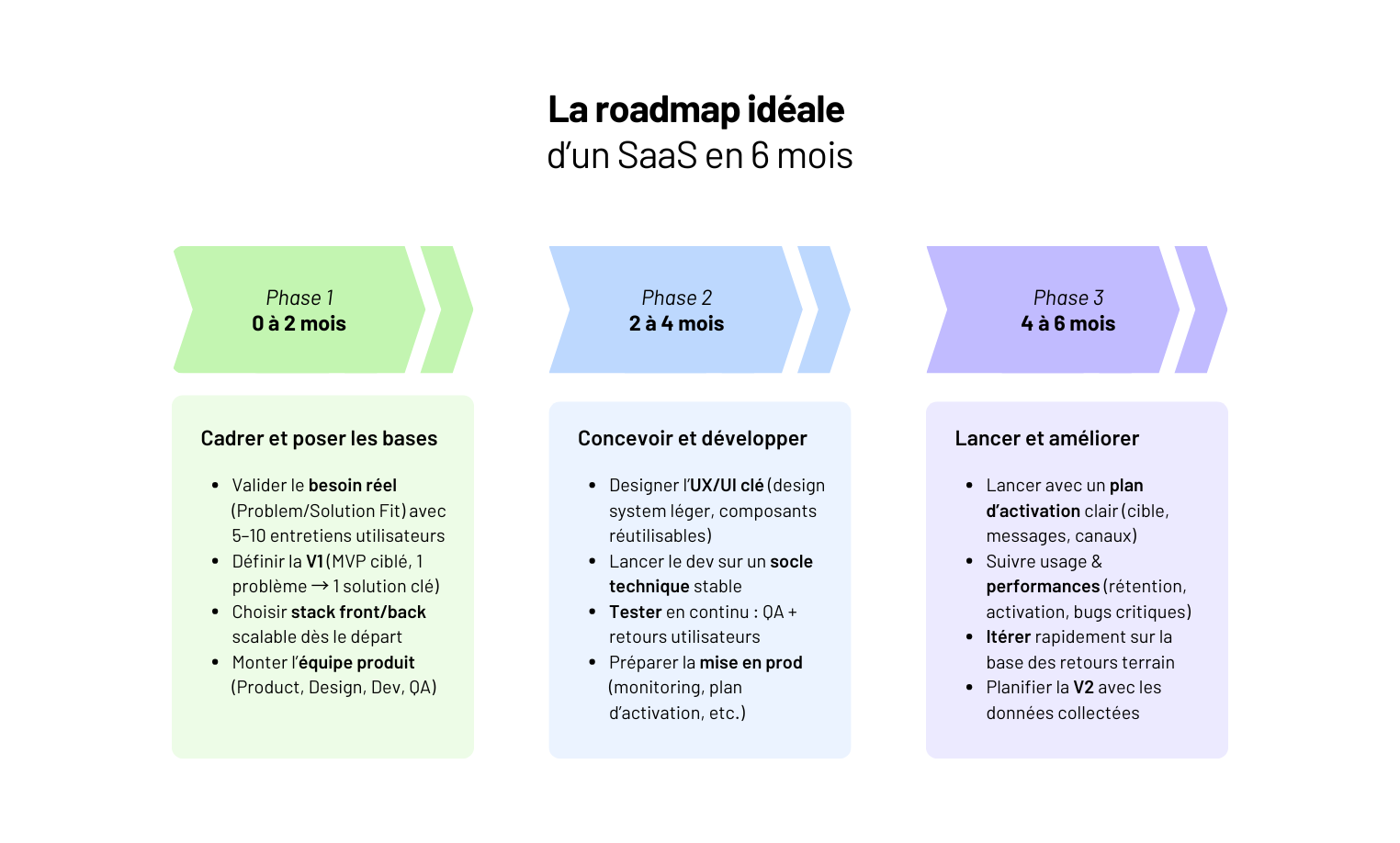
Création d’une application web (SaaS) : le guide complet
Vous donner un plan clair, étape par étape, pour transformer une idée en un produit SaaS robuste, évolutif, et adopté par ses utilisateurs.
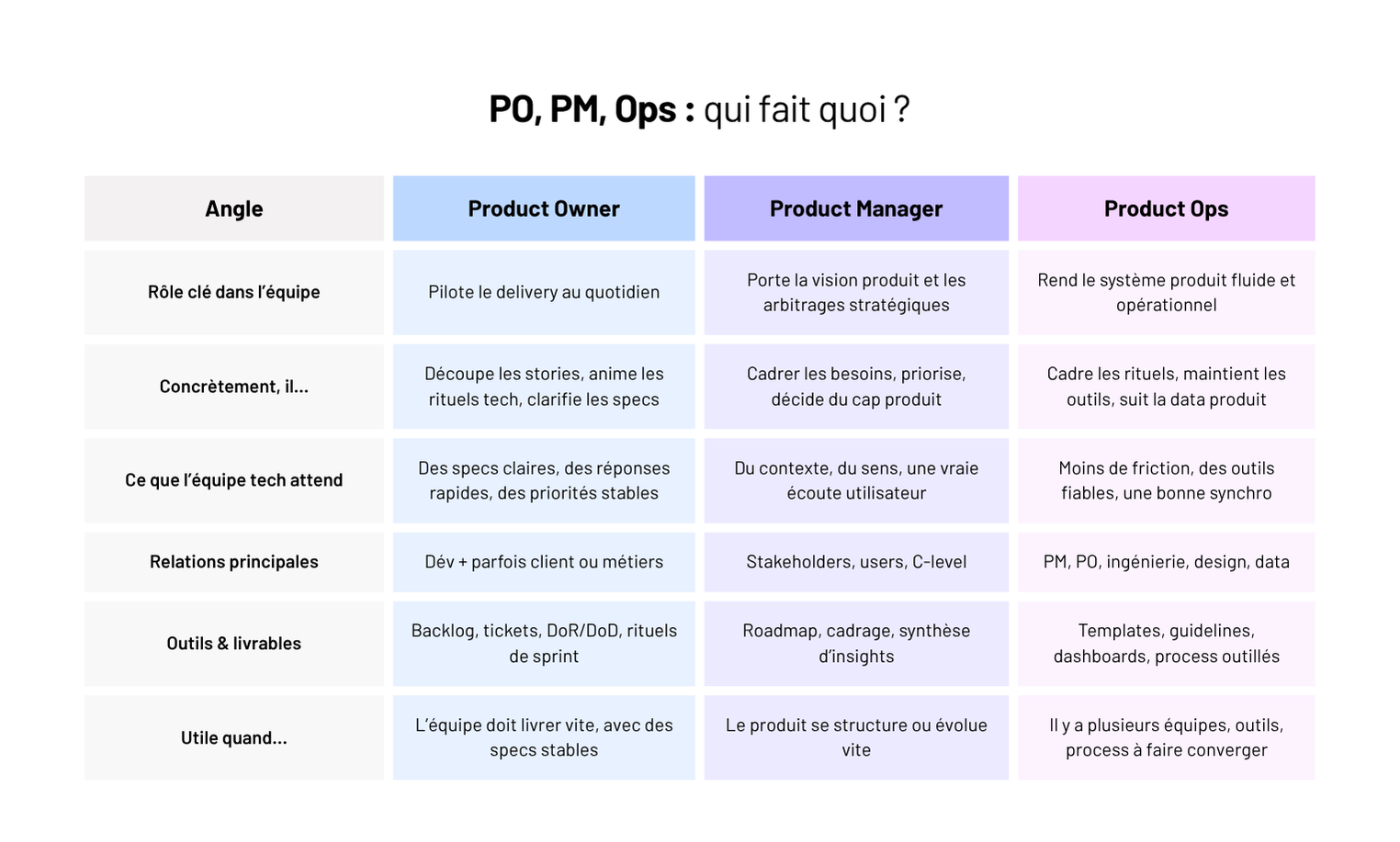
Product Ops, Product Owner, Product Manager : rôles clés et zones de flou dans les projets digitaux
Dans cet article, on fait le tri : rôles réels vs titres flous, zones grises à surveiller dans un projet, et comment structurer une organisation produit-tech plus lisible, plus fluide.
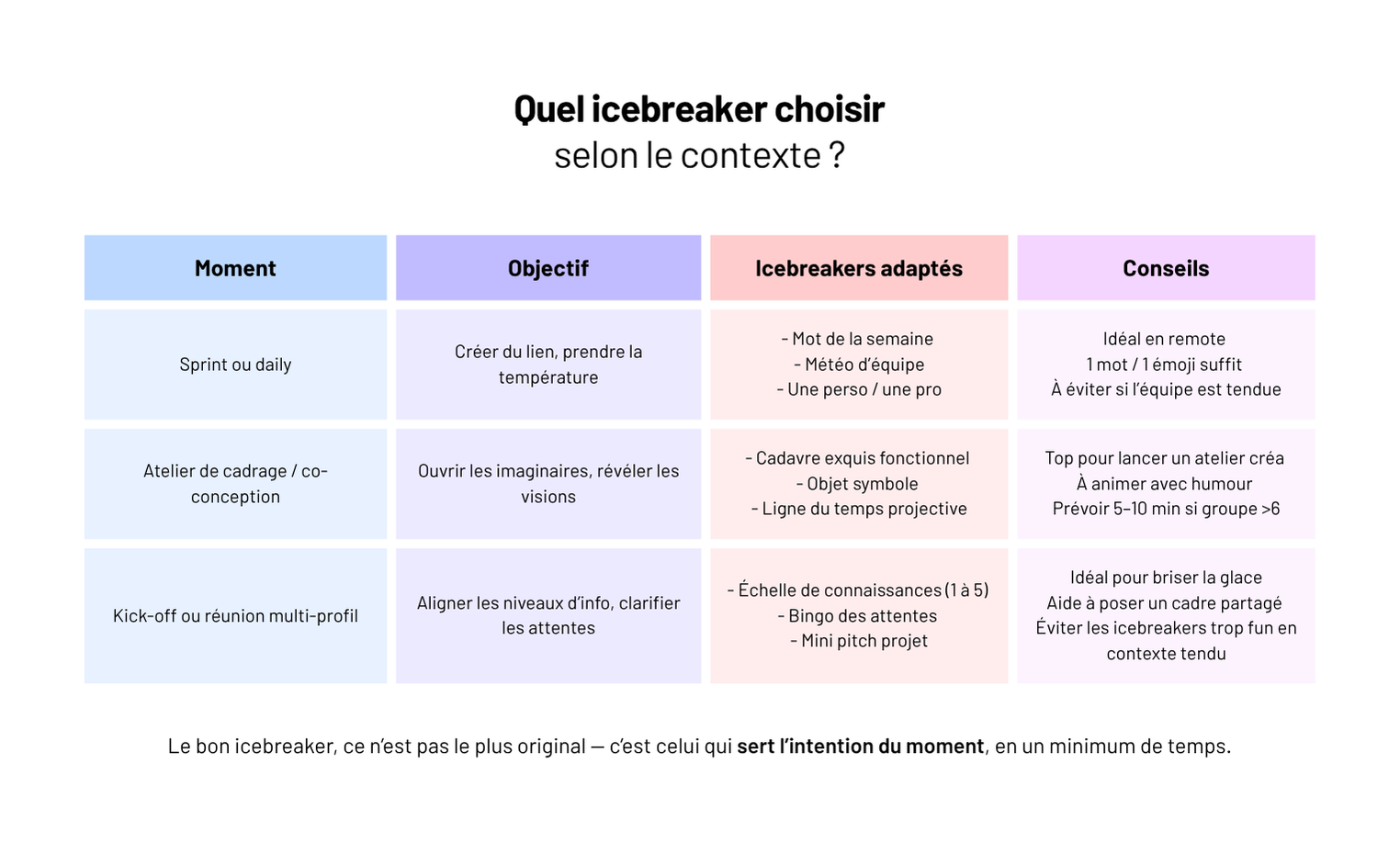
Nos 10 icebreakers préférés pour les débuts de sprint, d'ateliers ou de réunions de cadrage
Dans cet article, on partage nos formats préférés : ceux qui créent un vrai effet d’équipe, ceux qui se lancent en 2 minutes chrono, et ceux qu’on évite — car mal choisis, ils font perdre tout le bénéfice.

Feature Team : une bonne idée, mais pas partout
On l’a tous entendu dans une organisation qui cherche à mieux livrer. Et sur le papier, c’est séduisant : une équipe = une feature = de l’autonomie, du focus, de la vélocité.
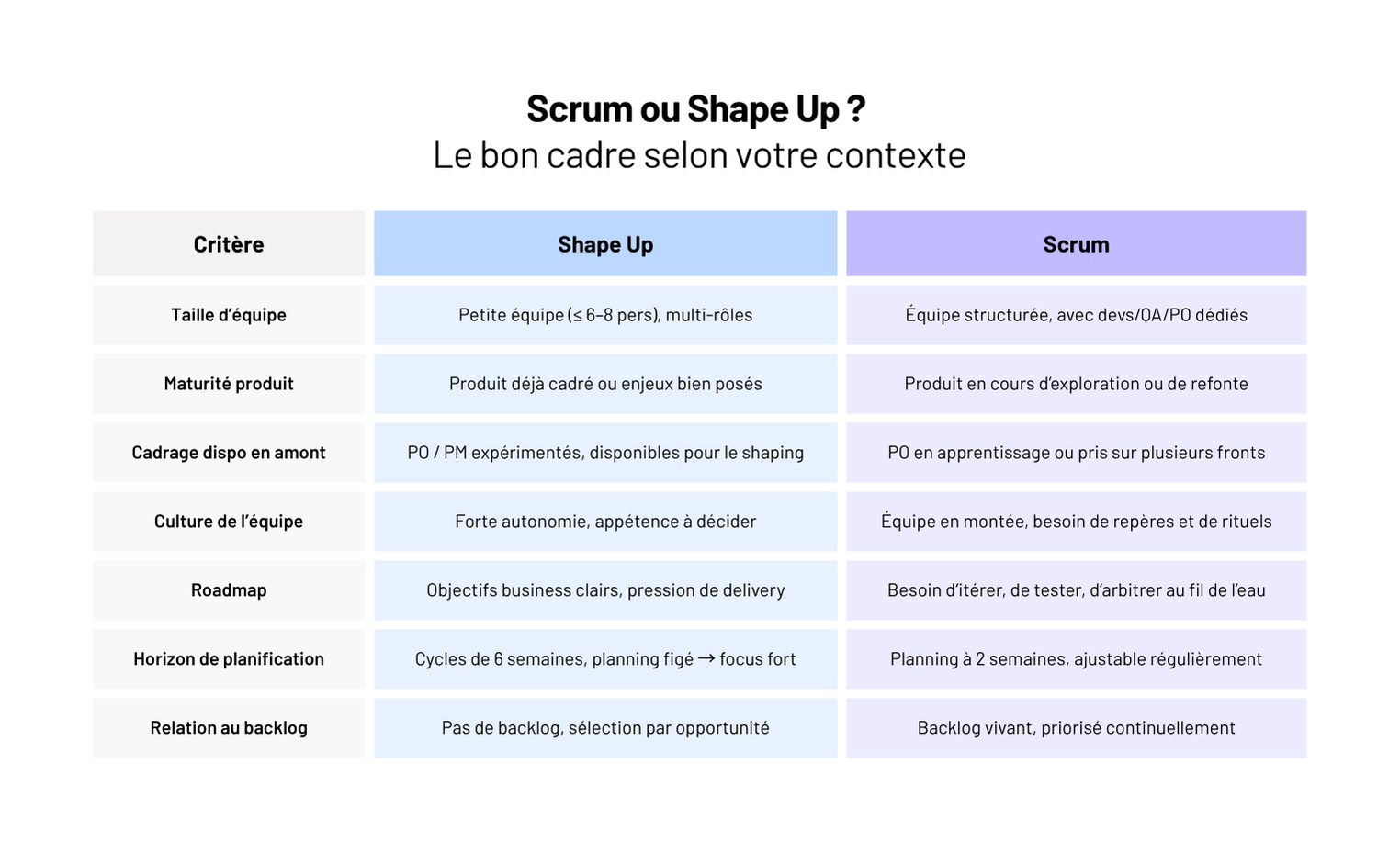
Méthode Shape Up vs Scrum : pour quels projets logiciels ?
Dans cet article, pas de duel Scrum vs Shape Up. Juste une analyse claire pour choisir (et adapter) la bonne approche.

Qu’est-ce qu’un Epic en gestion de produit ? Définition, exemples et anti-patterns
Dans cet article, on vous aide à faire le tri :ce qu’est (et n’est pas) un Epic ; comment le structurer pour qu’il serve vraiment ; les anti-patterns qu’on voit encore trop souvent ; et notre méthode pour l’utiliser comme boussole produit — pas comme backlog poubelle.
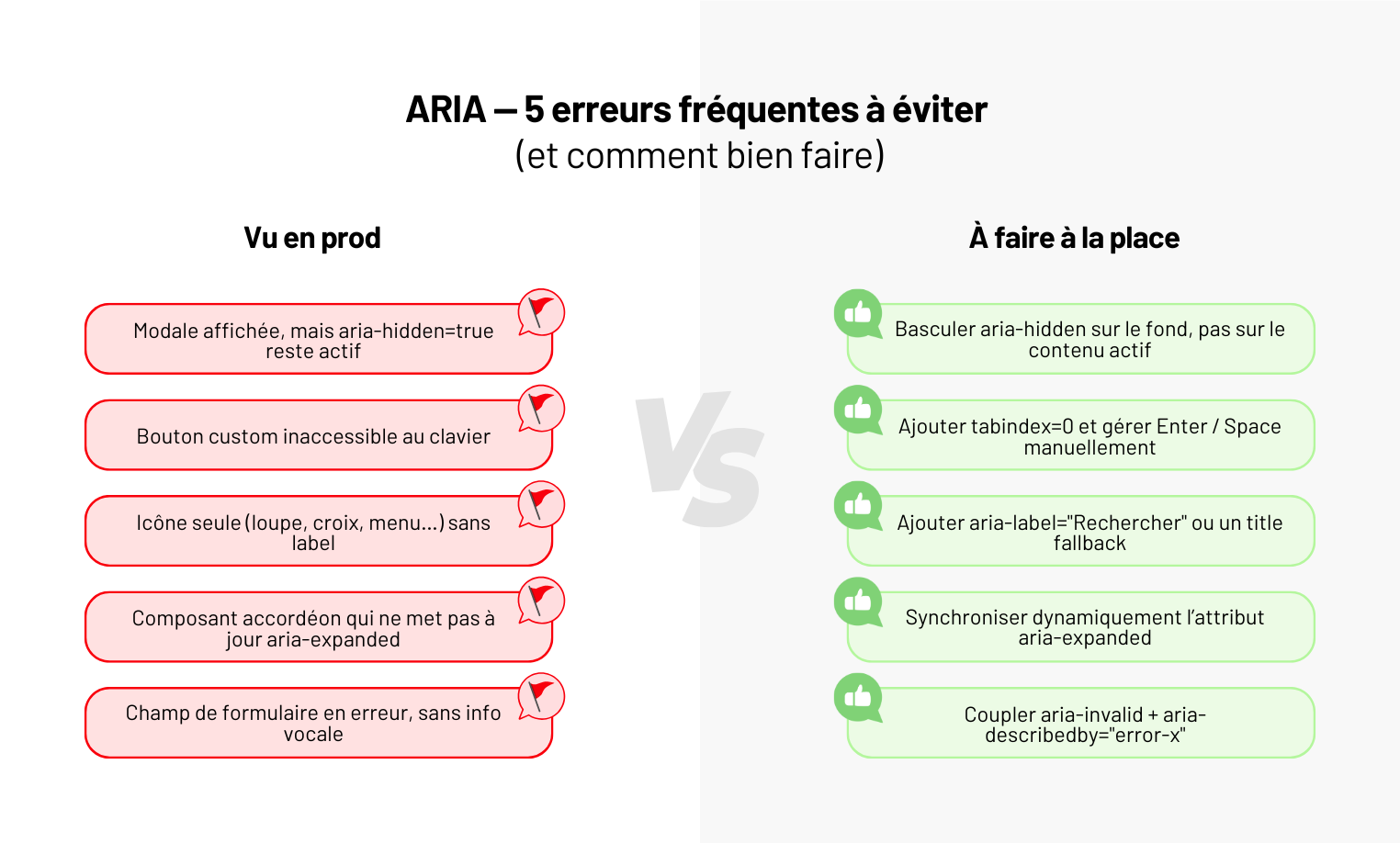
Accessibilité Web & Mobile : intégrer ARIA dans vos apps
Dans cet article, on vous montre quand et comment intégrer ARIA dans vos apps web ou mobiles
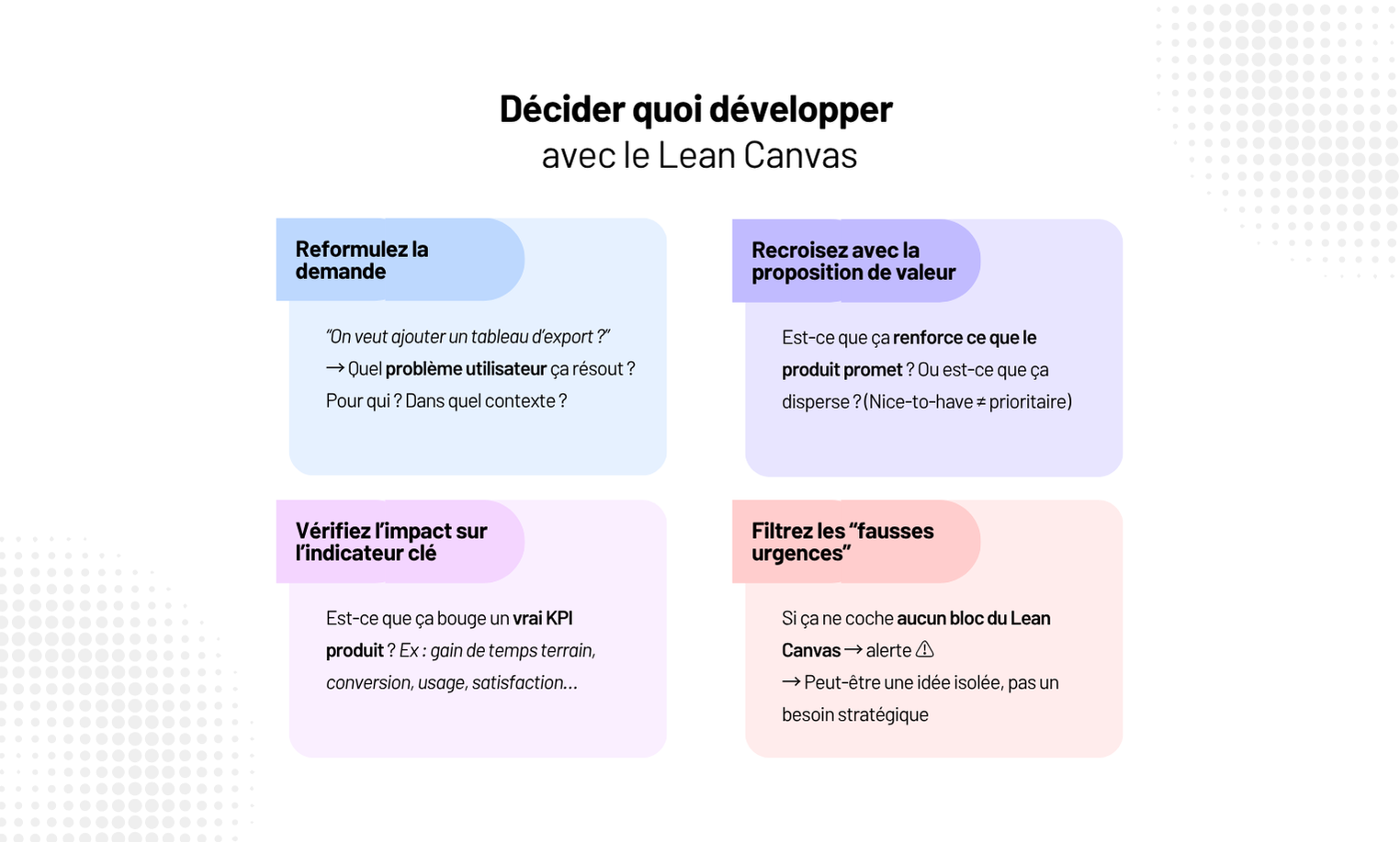
Lean Canvas pour les projets tech : un guide étape par étape
Ce guide, c’est notre méthode terrain : bloc par bloc, avec exemples, retours d’expérience et erreurs à éviter. Pour que votre projet parte vite — mais surtout, qu’il parte bien.
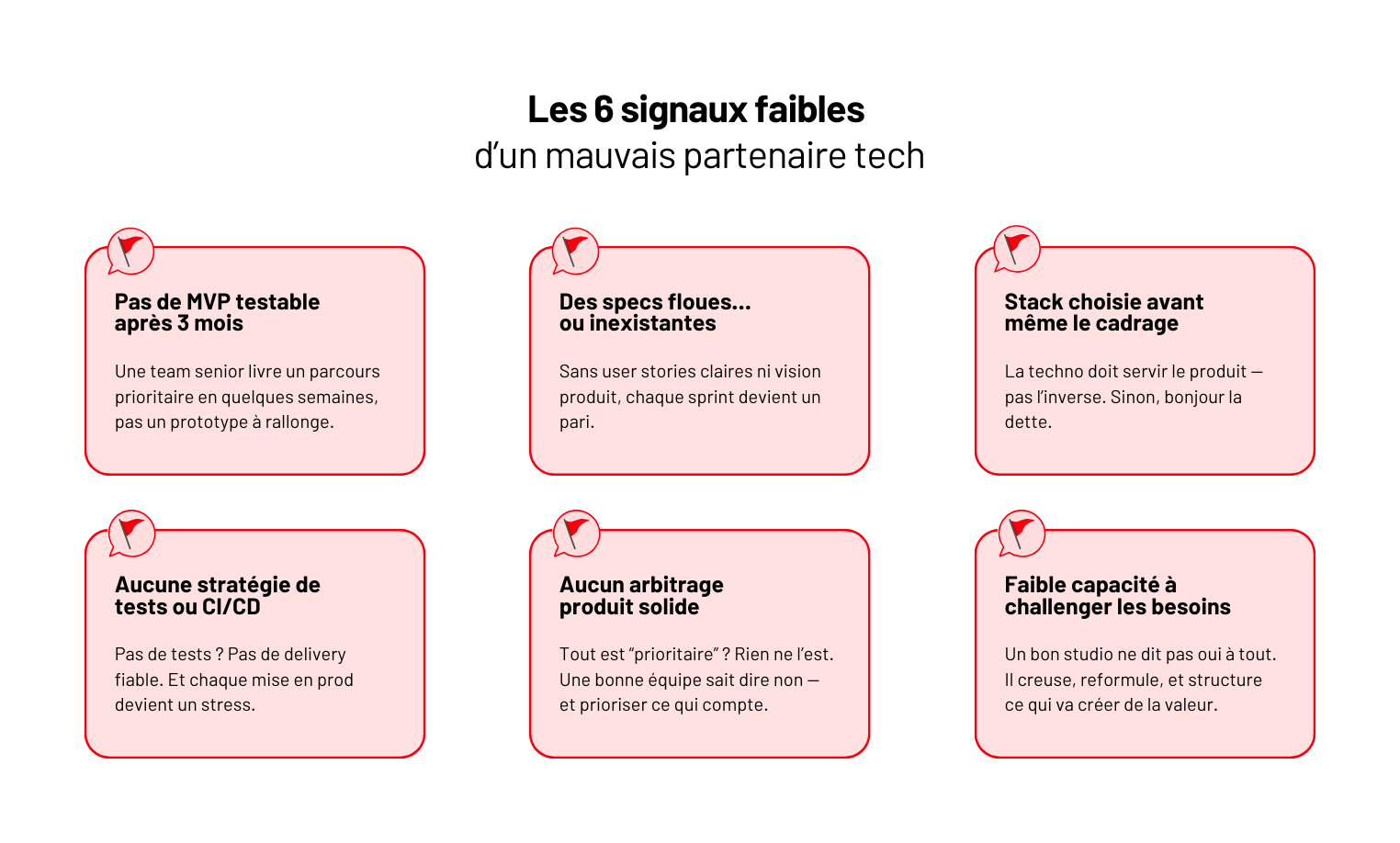
5 agences de développement logiciel qui livrent vraiment (et pas juste du code)
Tout le monde cherche une “boîte de dev” fiable. Mais combien savent vraiment construire un logiciel qui tourne — et qui dure ?

Top 5 des agences d’application mobile à Paris (qui livrent autre chose qu’un prototype)
Dans cet article, on partage 5 agences mobiles à Paris qui savent livrer un produit solide. Pas un prototype. Pas un showcase. Un outil réel, utilisé, qui tient dans la durée.

Piloter un projet web avec l’agile : oui, mais pas n’importe comment
Dans cet article, on vous partage notre méthode terrain — pour vraiment faire de l’agile. Pas pour coller des post-its.

Externaliser ou internaliser son équipe de product manager ?
C’est rarement une décision rationnelle. Parfois, on cherche “quelqu’un à qui confier la roadmap”. Parfois, on temporise parce que “c’est un poste stratégique, on veut prendre le temps de bien recruter.”

Rédiger des user stories utiles en développement sur-mesure : framework, erreurs courantes et exemples
Cet article s’adresse aux Product Owners, PMs, tech leads ou responsables métier qui pilotent un logiciel sur-mesure — outil interne, plateforme métier, SaaS spécifique — et qui veulent des stories utiles, activables, testables.

Top 5 des agences de développement web à Paris
Ce n’est pas une question de langage ou de stack. C’est une question de méthode, de niveau d’exigence, et de capacité à construire un logiciel web qui tient en prod.

Top 5 des meilleurs cabinets de conseil en product management

Logiciel métier : Définition, cas concrets, pièges à éviter
Dans cet article, on vous donne une définition claire, des exemples concrets, et des repères solides pour cadrer (ou recadrer) un projet de logiciel métier. De quoi éviter les angles morts avant d’écrire la moindre ligne de code.

Top 5 des agences web en France
Dans cet article, on vous partage 5 agences web qui savent vraiment construire un site utile. Pas juste une façade. Un outil. Fiable, performant, maintenable.

Qu’est-ce que le développement logiciel ? Pas ce que vous croyez.
Le développement logiciel ne se résume pas à “coder une idée”. C’est un processus complexe, interdisciplinaire, itératif — au service d’un usage réel. Et c’est là que la confusion commence.

Qu’est-ce qu’une application web vs un site web ?
Trop souvent, des entreprises lancent un “site” sans réaliser qu’elles veulent un outil métier. Résultat : un CMS bricolé, une logique métier plaquée, des galères d’usage dès la V1.

Pourquoi 70% des refontes d’application web échouent et comment éviter ça
Une refonte bien menée, ce n’est pas une réécriture. C’est un projet produit. Avec une vision claire. Une roadmap pilotée. Et une exigence : livrer de la valeur plus vite que ce qu’on remplace.

Studio développement web : quels avantages vs agence traditionnelle ?
Certaines agences tentent d’hybrider leur approche – en injectant un peu d’agilité, ou une pincée de discovery. Mais dans les faits, la majorité reste coincée dans une logique “prestataire à qui on confie une spec”. Et dès que le projet est complexe, stratégique, ou mouvant… ça coince.

Agence application web : quels avantages pour votre projet digital ?
Une application web, ce n’est pas juste “un front et une base de données”. C’est un produit digital à part entière : évolutif, monétisable, durable.
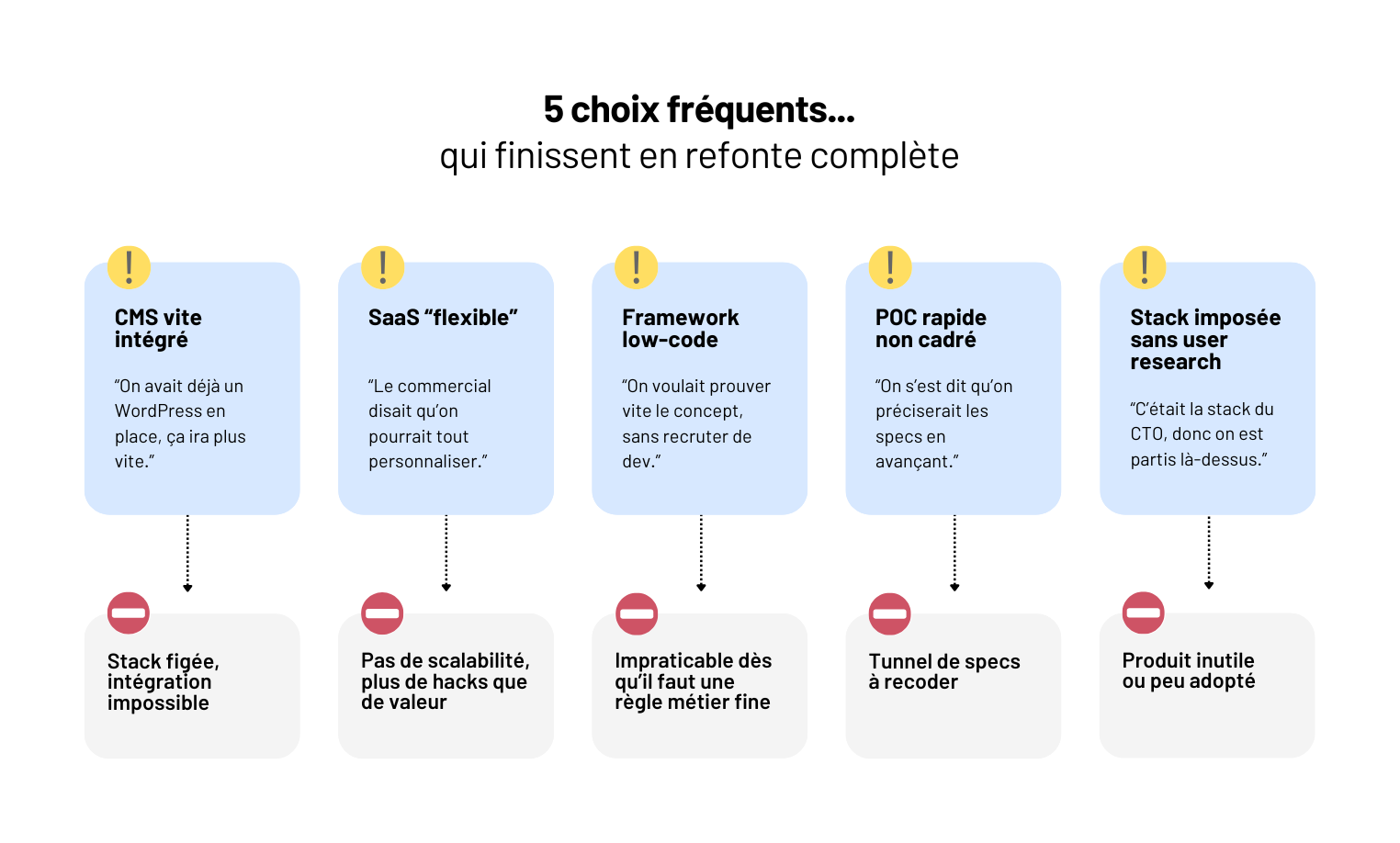
Développement web sur-mesure : quand faut-il l’envisager ?
Vous lancez un premier produit digital (SaaS, plateforme, app web) et vous voulez éviter les pièges du CMS bricolé ou du low-code qui plafonne vite

Application web : ce qu’il vous toujours cadrer avant de se lancer
Ce guide, on l’a conçu comme une checklist opérationnelle : tout ce qu’il faut avoir en tête avant de vous lancer, pour éviter les angles morts - et maximiser vos chances de livrer un produit utile, robuste, et maintenable. Pas dans 12 mois. Dans 6 à 8 semaines.

Comment cadrer un projet de développement web complexe ?
Un projet complexe, ce n’est pas un projet compliqué. C’est un projet où il faut de la méthode. Une méthode qui commence avant le premier sprint, avant le premier écran Figma, parfois même avant le premier dev.

Pourquoi externaliser le développement de votre application web ?
Dans un projet web complexe - SaaS B2B, plateforme métier, portail transactionnel - le risque, ce n’est pas de mal coder. C’est de prendre 12 mois pour valider une idée.

Agence développement web : quelles différences avec une agence web classique ?
Il illustre ce qui arrive quand on confond une agence de développement web avec une “agence web” tout-venant – et c’est exactement le sujet du jour : quelles différences entre les deux, et comment éviter de reproduire ce fiasco ?

Comment se déroule un projet de développement web chez Yield Studio ?
Ce que vous allez lire ici, c’est notre méthode en 8 étapes (et même 9 si vous lancez un produit early-stage), conçue pour transformer un besoin en produit digital utile, monétisable et durable.

Pourquoi faire appel à une agence de développement web ou mobile pour votre projet ?
Découvrez pourquoi faire appel à une agence de développement web comme Yield Studio pour vos projets de création d’applications web et mobiles.

Réussir le développement d'un logiciel en 8 étapes
Ce guide, c’est exactement ça : 8 étapes simples, concrètes, pour construire un logiciel métier qui sert vraiment. Pas un tunnel de dev. Pas une app “concept”. Un produit utile, piloté, livré, utilisé.

TMA (tierce maintenance applicative) mobile : Guide complet
Maintenance, TMA, support produit : peu importe le nom — ce qui compte, c’est de savoir comment vous faites durer votre app.

Création d'une application mobile : Guide Complet
Créer une app, ce n’est plus simplement “mettre une interface dans un store”. C’est construire un produit à part entière — utile, fiable, adopté.

Améliorer la collaboration entre les équipes Produit, Tech et Métier
Dans cet article, on vous montre comment remettre de l’huile dans les rouages. Clarifier les rôles. Aligner les objectifs. Installer des rituels simples mais efficaces. Et surtout : construire un mode de collaboration qui tient dans la durée, pas juste pendant la phase de rush.

Optimiser la performance et la scalabilité d’un logiciel métier
L’optimisation des perfs et la scalabilité, ce n’est pas un “chantier tech” à faire plus tard. C’est une responsabilité produit — à anticiper dès les premières briques, à observer en continu, à tester sans relâche.

Évaluer l’impact business du logiciel et son ROI
Dans un environnement où chaque ressource compte, un produit métier n’a pas droit à l’approximation. S’il ne livre pas de gains concrets — et mesurables —, il est vite abandonné, puis discrédité.

Modèle de Cahier des Charges pour la Création d'un Logiciel
Un bon logiciel métier commence par un bon cadrage. Pas une to-do sur Notion. Pas un brief à la volée. Mais un cahier des charges structuré, vivant, orienté usage — même (et surtout) en agile.

Gérer la dette technique et assurer la maintenabilité d'un logiciel
La dette technique, ce n’est pas du “code sale”. C’est un vrai sujet produit. Et quand elle explose, ce n’est pas juste la stack qui prend. C’est toute la roadmap.

Qu’est-ce qu’un PoC (Proof of Concept) en développement logiciel ?
Selon la Harvard Business Review, plus de 66 % des startups échouent à offrir un retour sur investissement à leurs actionnaires. Quelles sont les raisons de ce taux d’échec si élevé ?

Combien coûte un logiciel sur-mesure en 2025 ?
Un logiciel conçu pour vos process, vos équipes, vos enjeux. Pas un outil générique qu’on tord pour qu’il tienne à peu près la route.

Qu'est-ce qu'un développeur logiciel ? Rôle et compétences clés
Un tunnel de conversion qui plante. Une app mobile truffée de bugs. Un outil métier que personne n’utilise. À chaque fois, c’est la même question : où sont les devs ?

Les 5 étapes pour créer un logiciel : Guide complet
Trois mois après le lancement, premier bilan : 60 % des fonctionnalités ne sont pas utilisées. Les équipes continuent de bricoler sur des outils annexes. Le logiciel est en place, mais il n’a rien changé.

Accompagner les utilisateurs et maximiser l’engagement d’un logiciel métier
Un logiciel métier ne s’adopte pas comme une app grand public. Ici, pas d’utilisateur curieux qui "teste pour voir". Les équipes l’utilisent parce qu’elles y sont contraintes. Et si l’expérience est une galère ? Elles décrochent.
Suivre l’adoption d’un logiciel métier et ajuster les features selon les usages
Vous avez investi l’équivalent de 3 mois de travail… pour une fonctionnalité que seuls 8% de vos collaborateurs utilisent. Les autres ? Ils contournent, ignorent, font autrement.

Définir une stratégie de mise en production progressive pour un logiciel métier
Dans cet article, on vous montre comment structurer vos mises en production pour éviter les sueurs froides et déployer sans risque.

Déployer des tests automatisés et un monitoring efficace pour un logiciel métier
Un bug en production qui coûte 23 000 € ? Ça ne devrait jamais arriver. Et pourtant, faute de tests automatisés, c’est ce qui s’est passé pour une start-up qu’on a accompagnée.

L’avenir des DSI en 2025 : comment passer d’un fournisseur IT à un moteur d’innovation ?
En 2025, une DSI qui se contente de gérer les infrastructures et le support IT sera remplacée par des acteurs externes plus agiles. Pour survivre et prospérer, les DSI doivent se repositionner comme des moteurs d’innovation et de transformation digitale.

Adopter les bonnes pratiques de développement pour un logiciel métier
Dans cet article, on décode les principes essentiels pour un développement efficace, du socle technique à la gestion des priorités.

Mise en place de l’infrastructure et des outils de développement
Une infrastructure mal pensée ne s’effondre pas en un jour. Elle s’alourdit. Chaque mise en production devient plus risquée, chaque évolution prend trois fois plus de temps que prévu.
Pourquoi 70 % des transformations digitales échouent (et comment réussir la vôtre) ?
Les entreprises investissent des millions dans leur transformation digitale, mais 70 % d’entre elles échouent à obtenir des résultats concrets. Pourquoi ?

Définir l’architecture technique et préparer le développement
Un logiciel métier mal conçu ne s’effondre pas du jour au lendemain. Il s’alourdit. Il devient plus difficile à maintenir, plus coûteux à faire évoluer.

Créer un prototype interactif et valider les parcours utilisateurs d’un logiciel métier
Attendre le développement pour découvrir des problèmes, c’est trop tard. Le prototype interactif permet de valider ces choix en conditions réelles, avant qu’ils ne deviennent des blocages.

Traduire les besoins logiciels en wireframes puis en maquettes UI
Un workflow pensé sur le papier, mais impraticable en réel. Un tableau surchargé qui oblige à scanner chaque ligne. Une action clé noyée sous six clics inutiles. Conséquences ? Perte de temps, erreurs à répétition et utilisateurs frustrés.

Concevoir un design system modulaire pour un logiciel métier : structurer sans rigidifier
Un tableau conçu sans logique commune. Une navigation qui diffère d’un écran à l’autre. Résultat ? Des utilisateurs perdus, une adoption freinée, une dette UX qui s’accumule.

Comment cadrer et établir une roadmap pour un logiciel métier
Les équipes sont alignées, le besoin est clair, tout le monde est convaincu de l’intérêt du projet. Et pourtant, six mois plus tard, rien ne va plus. La roadmap s’est étirée, les fonctionnalités se sont multipliées, et la DSI se heurte à des contraintes imprévues. Résultat ? Un logiciel qui peine à sortir, et un terrain qui n’en veut déjà plus.

Comment définir les parties prenantes et les besoins utilisateurs pour un logiciel métier
Tout semblait carré : cahier des charges bouclé, budget validé, planning verrouillé. Mais au moment du déploiement, c’est la douche froide. Les utilisateurs rechignent, la DSI met son veto, les équipes terrain contournent déjà le nouvel outil. Résultat : adoption en chute libre, frustration généralisée, perte de temps et d’argent.

Digital Factory en entreprise : les 4 erreurs fatales qui mènent à l’échec
70 % des Digital Factories ne parviennent pas à générer un impact mesurable. Pourquoi ? Parce qu’elles tombent dans des pièges récurrents qui condamnent leur efficacité.

Comment fixer des objectifs pour mesurer le succès d’un logiciel
Un an de développement. Des dizaines de fonctionnalités. Des milliers d’euros investis. Et au final ? Impossible de dire si le logiciel a réellement amélioré quoi que ce soit.

Construire un logiciel : analyser le travail de vos équipes
Vous avez déjà vu ça : un nouveau logiciel déployé avec enthousiasme, censé révolutionner un process interne… et six mois plus tard, les équipes continuent à bricoler sur Excel ou à contourner l’outil.
DSI vs Digital Factory : quelle organisation choisir pour accélérer l’innovation ?
On analyse les forces et limites des deux modèles et on vous aide à choisir la bonne organisation pour maximiser votre impact digital.

Pourquoi les Digital Factories explosent et comment garantir leur succès ?

Créer une application Android sur le Google Play Store
Découvrez comment créer une application sur Google Play Store. Guide complet pour publier votre application avec succès. Conseils, étapes et astuces.

5 applications web impressionnantes développées avec Laravel
Découvrez comment Laravel transforme le développement web avec 5 exemples d'applications, de la mode à l'éducation.
Pourquoi les Digital Factory sont-elles l'avenir ?
Découvrez dans cet article fascinant pourquoi de nombreuses entreprises optent pour la création de Digital Factory en interne.

Double authentification sur mobile : pour quoi faire ?
Sécurisez vos comptes avec la double authentification sur mobile. Découvrez les méthodes, erreurs à éviter et renforcez votre protection numérique.

Headless CMS : tout ce qu’il faut savoir
Découvrez le monde du Headless CMS : architecture flexible, API Restful et GraphQL, avantages pour les applications mobiles et sites statiques.

Combien coûte une application mobile ?
Découvrez combien coûte une application mobile. De la phase MVP à la mise en production, décrypter les facteurs influençant le prix.

Comment développer une application iOS pour iPhone ?
Découvrez comment développer une application iOS, de la création à la mise en ligne sur l'App Store. Nos conseils pour créer votre application iPhone.

Notre voyage vers une culture adaptée au Télétravail chez Yield Studio
Découvrez comment nous avons adapté nos pratiques pour répondre aux besoins de nos équipes, qu'elles soient en présentiel ou en distanciel, et comment nous continuons à évoluer pour maintenir l'Humain au cœur de tout ce que nous faisons.

Régie vs Forfait : quel type de contrat choisir ?
Quel type de prestation choisir pour créer une application web ou une application mobile ? Que faut-il choisir : le mode Régie ou le mode Forfait ?

Comment créer un cahier des charges pour réaliser mon application ?
Nous recevons beaucoup de demandes de projet chaque jour. Cet article vous aidera à constituer un cahier des charges simple et concis. A choisir, il est potentiellement préférable d'avoir un cahier des charges de quelques lignes avec une problématique à résoudre concrète plutôt qu'une succession de fonctionnalités.

Tests utilisateurs : le succès d'une application
Les tests utilisateurs sont un outil essentiel pour garantir que l'application répond aux besoins des utilisateurs de manière optimale.
.webp)
Le top 5 des agences de Développement React en France
Cet article vous donne un descriptif des 5 meilleurs agences de Développement React en France, pour ne plus avoir à faire de longues recherches !

Le top 5 des meilleures agences de développement web en France
Cet article vous donne un descriptif des 5 meilleurs agences de développement web en France, pour ne plus avoir à faire de longues recherches !
Top 5 agences de développement en React Native en France
Vous cherchez à développer une application mobile en utilisant React Native, mais vous ne savez pas par où commencer ? Ne cherchez plus ! Dans cet article, nous allons vous présenter les 5 meilleures agences de développement en React Native en France.
Top 5 agences développement Laravel en France
Cet article vise à mettre en lumière les cinq meilleures agences de développement Laravel à Paris, chacune se distinguant par son expertise unique, sa capacité d'innovation et la qualité de ses réalisations.
.webp)
Top 5 agences développement Node.js en France
Découvrez notre top 5 des agences de développement Node.js en France.

Le top 5 des Meilleures Agences de Développement d'Application Mobile
Découvrez notre top 5 des meilleures agences de développement mobile, expertes en conception et maintenance, et réussissez votre lancement d’app.

Top 5 des Meilleures Agences de Design UX/UI en France
Ce top 5 des agences de design UX/UI en France vous dévoile des experts en création d'interfaces utilisateurs innovantes. Ces agences sont des références dans le secteur.

Top 5 des meilleures agences de Design Sprint en France
Découvrez le top 5 des agences de Design Sprint en France, expertes en innovation et méthodologies agiles pour transformer vos idées en succès !

Top 5 des Meilleures Agences de Développement PHP en France
Découvrez le top 5 des meilleures agences de développement PHP en France. Expertise, créativité et agilité sont ici pour garantir le succès de vos projets numériques.

Comparatif des meilleures agences Symfony en 2025
Découvrez le Top 5 des Meilleures Agences de Développement Symfony en France. Trouvez un partenaire expert pour vos projets web complexes et innovants.

Top 5 des Meilleures Agences de Développement iOS en France
Découvrez le Top 5 des Meilleures Agences de Développement iOS en France, spécialisées en innovation et solutions mobiles sur mesure.

Top 5 des Meilleures Agences d’Applications Mobile Flutter en France

Top 5 des Meilleures Agences de Développement Android en France
Découvrez le Top 5 des agences de développement Android en France, sélectionnées pour leurs expertise, innovation et résultats exceptionnels. Trouvez votre partenaire idéal ici.

Top 5 des Agences de Développement Angular en France
Découvrez notre Top 5 des meilleures agences de développement Angular en France pour propulser vos projets web avec expertise et innovation.

Top 5 des Meilleures Agences de Développement Next.js en France
Notre sélection des 5 meilleures agences de développement Next.js en France se trouve ici, elles garantissent des solutions web avancées et personnalisées.

Top 5 des Meilleures Agences de Développement Rust en France
Découvrez le top 5 des meilleures agences de développement Rust en France. Ce sont des spécialistes en solutions sécurisées et performantes pour vos projets.

Top 5 des Meilleures Agences de Développement Vue.js en France
Le Top 5 des meilleures agences de développement Vue.js en France est ici. Découvrez les experts en solutions digitales innovantes et boostez votre projet web.

Top 5 des meilleures agences de transformation digitale en France
Découvrez le top 5 des meilleures agences de transformation digitale en France pour booster votre entreprise vers le succès numérique.

Top 5 des Meilleures Agences de Maquettes Figma en France
Identifiez le top 5 des meilleures agences Figma en France pour des maquettes UX/UI innovantes et des designs qui convertissent.

Top 5 des Meilleures Agences de Product Management en France
Voici le top 5 des agences de product management en France, spécialisées en innovation et stratégies digitales qui propulsent vos projets.