Nos experts vous parlent
Le décodeur


Bienvenue dans le monde fascinant de Laravel, le framework PHP qui a révolutionné le développement web avec sa simplicité, son élégance et sa puissance. Que vous soyez un développeur chevronné ou simplement curieux de découvrir comment les applications web modernes sont construites, Laravel est un outil incontournable qui facilite la réalisation de projets complexes grâce à ses fonctionnalités avancées et son code élégant.
Dans cet article, nous allons plonger dans cinq exemples d'applications web exceptionnelles développées avec Laravel, qui illustrent parfaitement la polyvalence et l'efficacité de ce framework. De la préparation aux tests linguistiques avec GlobalExam à l’apprentissage de la conduite avec Ornikar, en passant par la formation logicielle via Lemon Learning ou encore le recrutement en ligne avec HelloWork, préparez-vous à être inspiré par la créativité et l'innovation que Laravel rend possible. Suivez-nous dans ce voyage à la découverte des meilleures applications Laravel et voyez par vous-même pourquoi ce framework est tant plébiscité dans le monde du développement web.
1. GlobalExam : Optimiser la préparation aux tests de langues
GlobalExam est une plateforme innovante qui permet aux utilisateurs de se préparer efficacement à divers tests de langues officiels tels que le TOEFL, le TOEIC, et le DELF. Utilisant Laravel, GlobalExam offre une interface flexible et robuste pour l'apprentissage en ligne, la gestion de contenu dynamique, et un suivi personnalisé des progrès des utilisateurs.
GlobalExam tire parti de Laravel pour développer une interface utilisateur qui facilite l'interaction et l'engagement des apprenants. Laravel aide à structurer des parcours d'apprentissage personnalisés en fonction des besoins spécifiques de chaque utilisateur, intégrant des exercices pratiques, des simulations d'examens, et des analyses de performances.
Exemple de code pour afficher des exercices personnalisés aux utilisateurs :
Ce code PHP illustre comment Laravel peut être utilisé pour récupérer et afficher des exercices adaptés au niveau de difficulté de l'utilisateur, en utilisant l'ORM Eloquent pour une extraction efficace des données correspondantes.

La capacité de Laravel à gérer de grandes quantités de contenu éducatif est essentielle pour une plateforme comme GlobalExam, qui offre des ressources pour une variété de tests dans plusieurs langues. Laravel facilite la mise à jour et l'organisation du contenu, assurant que les informations restent à jour et pertinentes.
Cet exemple montre comment Laravel gère la mise à jour du contenu éducatif, permettant aux administrateurs de la plateforme de maintenir facilement le matériel à jour avec des informations précises et actuelles.
Un aspect crucial de la préparation aux tests est le suivi des performances. Laravel aide GlobalExam à collecter et analyser les données des utilisateurs pour fournir des feedbacks détaillés et des recommandations personnalisées. Laravel offre des outils robustes pour le reporting et les analytics, qui sont essentiels pour optimiser les parcours d'apprentissage.
Ce code démontre l'utilisation de Laravel pour suivre et afficher les progrès des utilisateurs, en permettant un accès facile aux informations historiques et actuelles sur les performances.
GlobalExam est un exemple parfait de la façon dont Laravel peut être utilisé pour développer des applications web complexes, centrées sur l'utilisateur, dans le domaine de l'éducation.
2. Ornikar : Révolutionner l'apprentissage de la conduite
Ornikar est non seulement une auto-école en ligne qui offre des leçons de conduite et des cours de code de la route, mais elle transforme également la façon dont les gens apprennent à conduire en France. Utilisant Laravel, Ornikar offre une plateforme flexible et sécurisée pour que les utilisateurs planifient leurs leçons, étudient le code de la route et passent leurs examens, le tout en ligne.
Laravel permet à Ornikar de proposer une interface utilisateur (UI) fluide qui s'adapte à tous les appareils, essentielle pour les étudiants en déplacement. La facilité d'utilisation est améliorée par Laravel, qui soutient une expérience utilisateur homogène sur le site web, en permettant de réserver des leçons et d'accéder à des matériaux d'étude interactifs.
Exemple de code pour une réservation de leçon dans Laravel :
Ce code Laravel illustre comment une leçon peut être réservée via la plateforme, en s'assurant que toutes les données sont validées avant de procéder à l'enregistrement dans la base de données.

Avec un grand nombre d'utilisateurs accédant à des cours variés, la gestion efficace du contenu est cruciale. Laravel aide Ornikar à organiser et à mettre à jour ses contenus éducatifs de manière dynamique, garantissant que les informations sont toujours actuelles et pertinentes.
Ce morceau de code permet aux administrateurs de mettre à jour facilement le matériel de cours, en utilisant l'ORM Eloquent de Laravel pour une interaction fluide avec la base de données.
Ornikar utilise Laravel pour suivre les progrès des étudiants et analyser les données d'utilisation pour améliorer continuellement leurs services. Cette fonctionnalité est essentielle pour fournir un feedback personnalisé aux étudiants et pour ajuster les méthodes d'enseignement en fonction des besoins des utilisateurs.
Ce code utilise Laravel pour récupérer et afficher les progrès d'un étudiant, aidant les instructeurs et les étudiants à visualiser les améliorations au fil du temps et à identifier les domaines nécessitant une attention supplémentaire.
Ornikar est un exemple éloquent de la manière dont Laravel peut être utilisé pour transformer des industries traditionnelles comme l'éducation à la conduite.
3. Lemon Learning : Transformer la formation logicielle en entreprise
Lemon Learning est une plateforme innovante qui révolutionne la formation logicielle en entreprise en intégrant des guides interactifs directement dans les outils SaaS utilisés par les entreprises. Grâce à Laravel, Lemon Learning offre une solution fluide et intégrée qui aide les employés à maîtriser rapidement et efficacement divers logiciels, en réduisant le temps nécessaire à la formation et en maximisant la productivité.
L'un des défis majeurs pour Lemon Learning était d'assurer une intégration transparente de ses guides interactifs avec une multitude d'applications d'entreprise sans perturber l'expérience utilisateur. Laravel a permis de développer une API robuste et sécurisée qui s'interface facilement avec n'importe quel logiciel d'entreprise utilisé par les clients.
Exemple de code pour une API Laravel gérant les requêtes d'intégration :
Ce code illustre comment Laravel peut être utilisé pour créer des endpoints API qui facilitent l'intégration de la plateforme Lemon Learning avec divers logiciels d'entreprise, permettant des configurations personnalisées pour chaque client.

Laravel aide également Lemon Learning à gérer de manière dynamique et efficace les contenus de formation. La plateforme doit constamment mettre à jour et personnaliser les tutoriels pour s'adapter aux logiciels qui évoluent rapidement. Laravel offre des outils puissants pour la gestion de contenu qui facilitent ces mises à jour régulières.
Ce morceau de code permet aux administrateurs de Lemon Learning de mettre à jour les tutoriels directement via le tableau de bord, en utilisant l'ORM Eloquent pour une interaction efficace avec la base de données.
Un autre aspect crucial de Lemon Learning est le suivi des progrès des utilisateurs et l'analyse des performances des tutoriels. Laravel fournit des capacités sophistiquées de reporting et d'analyse qui permettent à Lemon Learning d'offrir des insights précieux aux entreprises sur l'efficacité des formations.
Ce code utilise Laravel pour recueillir et présenter des données détaillées sur la progression de chaque utilisateur, aidant les entreprises à mesurer l'impact réel de la formation sur la productivité et l'efficacité des employés.
Lemon Learning illustre parfaitement la capacité de Laravel à soutenir des solutions technologiques innovantes dans le domaine de la formation en entreprise.
4. HelloWork : Dynamiser le recrutement en ligne
HelloWork est une plateforme française leader dans le domaine du recrutement en ligne, qui connecte les employeurs aux candidats à travers une interface intuitive et efficace. Utilisant Laravel, HelloWork optimise les processus de recherche d'emploi et de recrutement, facilitant les interactions entre les entreprises et les chercheurs d'emploi grâce à des fonctionnalités avancées et une gestion fluide des données.
La plateforme HelloWork repose sur Laravel pour fournir une expérience utilisateur (UX) riche et interactive, facilitant la navigation, la recherche d'emploi et la gestion des candidatures. Laravel aide à structurer une interface utilisateur qui répond rapidement aux actions des utilisateurs, améliorant ainsi leur engagement et leur satisfaction.
Exemple de code pour afficher les offres d'emploi selon les filtres de l'utilisateur :
Ce code illustre comment Laravel peut être utilisé pour créer des filtres dynamiques qui ajustent les résultats de recherche en fonction des préférences des utilisateurs, rendant la recherche d'emploi plus ciblée et efficace.

Laravel fournit à HelloWork les outils nécessaires pour gérer dynamiquement des milliers d'annonces d'emploi et de profils de candidats. L'ORM Eloquent intégré permet une manipulation aisée des données, assurant une mise à jour et une récupération efficace des informations pertinentes.
Ce morceau de code montre comment les annonces d'emploi peuvent être mises à jour facilement par les employeurs, garantissant que les informations restent actuelles et précises.
La capacité de suivre les candidatures et d'analyser le comportement des utilisateurs est cruciale pour optimiser les stratégies de recrutement. Laravel aide HelloWork à collecter et analyser les données des utilisateurs, fournissant des insights précieux pour les employeurs sur l'efficacité de leurs annonces.
Ce code utilise Laravel pour récupérer et afficher les données sur les candidatures reçues pour un poste spécifique, permettant aux employeurs de mesurer l'intérêt et l'efficacité de leurs annonces.
HelloWork démontre l'efficacité de Laravel dans le développement de solutions de recrutement en ligne.
5. Ecodrop : Faciliter le recyclage pour les professionnels du BTP
Ecodrop est une plateforme innovante qui révolutionne la gestion des déchets de construction en facilitant le recyclage pour les professionnels du BTP en France. Utilisant Laravel, Ecodrop offre une solution efficace pour localiser les points de collecte les plus proches, gérer les déchets de manière responsable, et optimiser la logistique des déchets de chantier.
Laravel aide Ecodrop à fournir une interface utilisateur claire et facile à naviguer, permettant aux professionnels de trouver rapidement des solutions de recyclage à proximité. La plateforme permet également une interaction fluide pour la réservation de collectes de déchets, la consultation des prix et le suivi des transactions.
Exemple de code pour la recherche de centres de recyclage par localisation :
Ce code montre comment Laravel peut être utilisé pour filtrer les centres de recyclage en fonction du code postal fourni par l'utilisateur, simplifiant ainsi la recherche et aidant les professionnels à trouver les options les plus pratiques.

Laravel fournit les outils nécessaires pour gérer efficacement les profils des utilisateurs et les commandes de collecte de déchets. Les professionnels peuvent s'enregistrer, gérer leurs informations, et planifier des collectes en quelques clics.
Ce morceau de code illustre la mise à jour du profil utilisateur avec Laravel, utilisant l'authentification intégrée et l'ORM Eloquent pour une interaction sécurisée et efficace avec la base de données.
Laravel aide Ecodrop à suivre les transactions et à analyser l'efficacité des services offerts. La plateforme collecte des données sur les types et volumes de déchets collectés, permettant des analyses approfondies pour améliorer continuellement le service.
Ce code utilise Laravel pour récupérer les détails d'une transaction spécifique, y compris les informations sur l'utilisateur et le centre de recyclage, facilitant le suivi et l'analyse des services de collecte.
Ecodrop illustre parfaitement comment Laravel peut être exploité pour développer des solutions durables et efficaces dans le secteur du BTP.
En explorant ces cinq applications fascinantes développées avec Laravel - de GlobalExam à Ecodrop, en passant par Ornikar, Lemon Learning, et HelloWork -, il est clair que Laravel ne se contente pas d'être un simple outil de développement web. Il représente une solution complète qui offre flexibilité, efficacité et puissance pour relever les défis du développement web moderne. Chaque exemple met en lumière la capacité de Laravel à transformer des idées ambitieuses en réalités numériques robustes et performantes, offrant des expériences utilisateur riches et intuitives.
Que vous soyez un développeur cherchant à affiner vos compétences ou une entreprise en quête d'innovation, Laravel se présente comme le framework de choix pour créer des applications web qui se distinguent. En définitive, ces cinq exemples ne sont qu'un aperçu de ce qui est possible avec Laravel, ouvrant la porte à un monde de potentiel illimité pour les développeurs et les entreprises du monde entier.

L'univers des applications mobiles évolue à une vitesse fulgurante, où chaque seconde compte et chaque expérience utilisateur peut faire la différence.
Au cœur de cette révolution numérique, React Native, un framework développé par Meta (anciennement Facebook), se distingue comme un outil puissant permettant de créer des applications mobiles performantes et esthétiquement agréables pour iOS et Android à partir d'un seul et même code. Cet article se propose de vous faire découvrir cinq applications innovantes développées avec React Native. De la communication instantanée avec Discord à la gestion de vos inspirations avec Pinterest, en passant par l'amélioration de l'expérience de voyage avec Airbnb, le contrôle de votre véhicule Tesla, et le suivi de vos campagnes publicitaires Facebook avec Meta Ads Manager, ces exemples illustrent parfaitement comment React Native révolutionne le monde des applications mobiles. Découvrons ensemble comment ce framework JavaScript aide les développeurs à réduire les coûts et le temps de développement tout en offrant aux utilisateurs des applications rapides, réactives et visuellement attrayantes.
1. Discord : Un hub de communication unifié
Dans le monde numérique d'aujourd'hui, Discord s'est rapidement imposé comme une plateforme de communication incontournable, offrant chat vocal, vidéo, et texte aux communautés et amis du monde entier. Grâce à React Native, Discord a réussi à étendre son expérience utilisateur unique à des millions d'utilisateurs mobiles sur iOS et Android, tout en maintenant une performance et une qualité exceptionnelles.
React Native a permis à Discord de partager une grande partie de son code entre les plateformes mobiles, réduisant ainsi le temps de développement et les efforts nécessaires pour maintenir l'application. Cette approche a également facilité l'implémentation de fonctionnalités complexes telles que le chat en temps réel, les notifications push, et le streaming vocal en direct, garantissant ainsi que les utilisateurs bénéficient d'une expérience fluide et cohérente, quelle que soit la plateforme qu'ils utilisent.
La gestion des notifications en temps réel sur des appareils multiples était l'un des défis majeurs. React Native a offert à Discord une manière efficace de gérer ce flux de données en temps réel grâce à sa compatibilité native avec les systèmes d'exploitation mobiles. Voici un exemple simplifié de code illustrant comment les notifications push peuvent être gérées dans une application React Native :
Cet extrait montre comment une application React Native peut écouter et réagir aux notifications push, un élément clé pour maintenir les utilisateurs engagés et informés dans l'environnement rapide de Discord.

L'adoption de React Native a permis à Discord non seulement de synchroniser l'expérience utilisateur entre les versions de bureau et mobiles mais aussi d'introduire des mises à jour simultanées sur toutes les plateformes. Cela signifie que les utilisateurs mobiles bénéficient des mêmes fonctionnalités et de la même réactivité que ceux sur PC, contribuant ainsi à renforcer la communauté et l'engagement global sur Discord.
L'utilisation de React Native par Discord est un exemple parfait de la manière dont les technologies modernes peuvent être utilisées pour créer des applications mobiles complexes et performantes.
2. Airbnb : Réinventer l'expérience de voyage
Airbnb, le géant de la location de logements de vacances en ligne, a choisi React Native pour une partie de son développement mobile, cherchant à unifier l'expérience utilisateur sur les plateformes iOS et Android. Cette décision illustre la volonté d'Airbnb d'optimiser et de rendre plus agile le développement de nouvelles fonctionnalités, tout en maintenant une expérience utilisateur homogène et de haute qualité.
La transition vers React Native a été motivée par le besoin d'accélérer le développement de l'application mobile tout en réduisant les coûts. Grâce à React Native, Airbnb a pu réutiliser le code entre les plateformes mobiles et web, optimisant ainsi les ressources et réduisant significativement le temps de développement. Cette approche a également facilité la mise à jour et l'amélioration de l'application, permettant à Airbnb de répondre rapidement aux besoins des utilisateurs.
Un des principaux défis rencontrés par Airbnb était de maintenir une expérience utilisateur fluide et réactive, en particulier pour les fonctionnalités riches en contenu comme les galeries de photos et les cartes interactives. React Native a offert des solutions performantes à ces problématiques, notamment grâce à des composants optimisés et à la possibilité d'intégrer du code natif pour les parties les plus exigeantes de l'application. Voici un exemple de code illustrant l'intégration d'une galerie de photos dans une application React Native :
Cet exemple montre comment un composant de galerie de photos peut être implémenté dans React Native, offrant une expérience fluide et réactive aux utilisateurs souhaitant explorer les images des logements disponibles sur Airbnb.

L'adoption de React Native par Airbnb a significativement amélioré l'expérience utilisateur sur mobile. Les utilisateurs bénéficient désormais de performances optimales et d'une interface utilisateur cohérente sur les différentes plateformes. De plus, React Native a permis à Airbnb de déployer rapidement de nouvelles fonctionnalités, assurant ainsi que l'application répond toujours mieux aux attentes des voyageurs et des hôtes.
L'expérience d'Airbnb avec React Native démontre l'efficacité de ce framework pour le développement d'applications mobiles complexes et performantes.
3. Tesla : Connectivité avancée pour les propriétaires de véhicules
Tesla, pionnière dans l'industrie des véhicules électriques, a également embrassé React Native pour offrir à ses propriétaires une application mobile riche en fonctionnalités, permettant de contrôler et de surveiller leurs véhicules à distance. Cette application représente un élément clé de l'expérience Tesla, reflétant l'innovation et la technologie de pointe de la marque.
L'utilisation de React Native par Tesla montre comment le framework peut être étendu au-delà des applications traditionnelles pour englober des fonctionnalités IoT (Internet of Things) avancées. React Native a permis à Tesla de développer une application performante qui interagit en temps réel avec ses véhicules, offrant des fonctionnalités telles que le contrôle à distance de la température, le verrouillage et déverrouillage des portes, et le suivi de la localisation du véhicule.
Un des défis majeurs pour Tesla était de garantir que l'application puisse communiquer de manière fiable et sécurisée avec les véhicules. Pour cela, Tesla a intégré des interfaces de programmation d'application (API) sécurisées, permettant à l'application React Native de transmettre des commandes et de recevoir des données du véhicule en temps réel. Voici un exemple simplifié de code montrant comment une commande peut être envoyée à un véhicule Tesla à partir de l'application :
Cet exemple illustre comment les propriétaires de Tesla peuvent interagir avec leur véhicule directement depuis leur smartphone, en utilisant React Native pour envoyer des commandes sécurisées via l'API de Tesla.

L'application Tesla, développée avec React Native, enrichit considérablement l'expérience du propriétaire en offrant une interface intuitive pour accéder à une multitude de contrôles et d'informations sur le véhicule. Cette intégration harmonieuse de la technologie mobile et automobile souligne l'engagement de Tesla envers l'innovation et la satisfaction du client, en mettant la technologie de pointe au bout des doigts des utilisateurs.
La réussite de l'application Tesla démontre le potentiel de React Native pour développer des applications mobiles qui vont au-delà du cadre traditionnel, en s'étendant aux domaines de l'IoT et de l'interaction véhicule-utilisateur.
4. Pinterest : Réinventer le partage d'inspirations
Pinterest est une application mobile très populaire utilisée par des millions de personnes pour trouver de l'inspiration, des idées pour leurs intérêts, hobbies et projets. La plateforme a intégré React Native de façon progressive dans son application iOS et Android pour optimiser le développement de nouvelles fonctionnalités et améliorer l'expérience utilisateur sur les deux plateformes.
L'un des plus grands défis de Pinterest était de maintenir une expérience utilisateur fluide et cohérente à travers les différentes plateformes tout en intégrant de nouvelles fonctionnalités de manière rapide et efficace. L'utilisation de React Native a permis à Pinterest de partager une grande partie de son code entre iOS et Android, ce qui a significativement réduit le temps de développement et les coûts associés.
Voici un exemple de composant React Native qui pourrait être utilisé pour afficher une grille de photos inspirantes, typique de Pinterest :
Ce code montre comment un simple composant React Native peut être utilisé pour créer une grille d'images, permettant aux utilisateurs de Pinterest de parcourir visuellement diverses inspirations rapidement et efficacement.

Pinterest utilise également React Native pour améliorer les interactions utilisateur en rendant l'application plus réactive et en réduisant les temps de chargement. Cela inclut l'amélioration des transitions et animations qui rendent l'exploration de contenus plus intuitive et engageante.
Cet extrait de code démontre comment utiliser les animations de React Native pour ajouter un effet de zoom dynamique lorsqu'une image est pressée, améliorant ainsi l'engagement et l'expérience utilisateur sur l'application.
L'intégration de React Native dans l'application Pinterest a non seulement permis d'améliorer la performance et la cohérence entre les plateformes mais aussi de réduire le temps nécessaire pour tester et déployer de nouvelles fonctionnalités.
5. Meta Ads Manager : Optimisation de la gestion publicitaire
Meta Ads Manager (ou Publicité Facebook en français) est un exemple éminent de l'utilisation de React Native pour une application largement utilisée et critique pour les affaires. Conçue pour permettre aux entreprises et aux individus de gérer leurs campagnes publicitaires sur Facebook, cette application illustre parfaitement comment React Native facilite le développement rapide et efficace d'applications complexes et performantes qui nécessitent une gestion de données en temps réel et une interaction utilisateur intensive.
Un défi majeur pour Meta Ads Manager était de fournir une expérience utilisateur cohérente et performante sur les différentes plateformes mobiles, tout en intégrant des fonctionnalités complexes de gestion de campagnes publicitaires. React Native a permis de développer une application unique qui fonctionne de manière fluide à la fois sur iOS et Android, réduisant ainsi les coûts et le temps de développement associés au maintien de deux bases de code séparées.
Exemple de code pour une vue simplifiée de la gestion des campagnes dans Meta Ads Manager :
Ce composant affiche les informations clés d'une campagne publicitaire et permet une interaction rapide pour la modification, illustrant comment React Native peut être utilisé pour créer des interfaces utilisateur dynamiques et interactives.

L'application Meta Ads Manager nécessite non seulement une grande réactivité de l'interface mais aussi une gestion efficace des données en temps réel pour afficher les performances des campagnes publicitaires. React Native offre des outils puissants pour optimiser les performances, comme le chargement paresseux des données et la mise en cache des résultats, qui améliorent significativement l'expérience utilisateur.
Cet exemple montre comment les composants de React Native, tels que ScrollView et ActivityIndicator, peuvent être utilisés pour construire une expérience utilisateur fluide qui gère efficacement les états de chargement des données.
Meta Ads Manager est un exemple brillant de la manière dont React Native peut être exploité pour développer des applications mobiles complexes, largement utilisées et critiques pour le commerce.
En explorant ces cinq applications diverses - de Discord à Meta Ads Manager, en passant par Airbnb, Tesla, et Pinterest – nous avons pu constater la puissance et la flexibilité de React Native comme outil de développement d'applications mobiles. Chacun de ces exemples montre comment React Native permet de créer des expériences utilisateur riches et performantes sur iOS et Android à partir d'un code partagé, simplifiant le processus de développement tout en offrant une excellente qualité et réactivité.
React Native se distingue par sa capacité à réduire les délais de développement, à faciliter la maintenance des applications et à offrir une expérience utilisateur homogène sur différentes plateformes. Que ce soit pour améliorer la connectivité entre les véhicules et leurs propriétaires, fournir une plateforme de bien-être mental accessible, ou encore permettre aux créateurs de gérer leur présence en ligne, React Native se révèle être un choix stratégique pour les développeurs cherchant à innover et à répondre aux besoins des utilisateurs modernes.
Ces exemples d'applications en React Native illustrent parfaitement comment la technologie peut être utilisée pour répondre à des besoins variés et complexes, ouvrant la voie à de nouvelles possibilités dans le monde du développement d'applications mobiles. Avec React Native, le futur des applications mobiles semble prometteur, marqué par une innovation continue et une expérience utilisateur toujours plus enrichie.

Dans l'article précédent nous avons initialisé notre monorepo, la CI, le framework de test et préparé la structure de notre projet et plus précisément de notre Architecture Hexagonale pour la lib core.
Dans ce nouvel article de la série notre objectif va être de mettre en place l'Architecture Hexagonale et de montrer comment grâce à elle nous allons pouvoir développer et créer de la logique métier sans UI (donc sans ouvrir le navigateur ou l'app mobile). Pour cela nous allons travailler en TDD (Test-Driven Development, vous pouvez voir mon article à ce sujet) et utiliser le feedback des tests.
L'Architecture Hexagonale
La structure cible
Pour rappel, voici la structure que l'on va mettre en place à l'issue de cet article :
- src
- wallet
- __ tests __
- wallet.service.test.ts
- domain
- wallet.ts
- wallet.repository.ts
- wallet.service.ts
- infrastructure
- in-memory-wallet.repository.ts
- local-storage-wallet.repository.ts
- mmkv-wallet.repository.ts
- user-interface
- wallet.store.ts
Chose promise, chose due ! Nous allons maintenant rentrer dans le détail de chaque fichier, à quoi ils servent et ce qu'ils contient.
Développer en TDD
Lorsqu'on travaille en TDD on commence par le test et ce test va nous guider vers un objectif. Il va nous assurer qu'on suit le bon chemin à l'aide de la boucle de feedback régulière qu'on obtient à l'aide des tests. Pour en savoir plus sur la méthodologie à suivre pour faire du TDD je vous invite à nouveau à lire mon article à ce sujet.
Nous allons commencer par travailler sur l'entité Wallet qui correspond à un portefeuille qui a un solde négatif ou positif (par exemple on peut avoir le portefeuille "Compte Principal Julien" qui a un solde positif de 1000€).
Voici les tests mis en place pour cette entité :
On peut comprendre via ces tests que les cas d'utilisations de notre entité sont :
- getAll, récupération de tous les portefeuilles
- get, récupération d'un portefeuille en particulier
- create, création d'un portefeuille
- update, mise à jour d'un portefeuille
- delete, suppression d'un portefeuille
Nous allons voir maintenant comme réussir à mettre en place ces tests.
Domain
Nous allons commencé par créer le contenu de la partie Domain. Dans cette partie nous allons retrouver tout ce qui représente le problème à résoudre (problème métier). C'est une partie qui doit être totalement indépendante.
L'entité
Commençons par créer notre entité Wallet correspondant à un portefeuille.
Le repository
Maintenant que notre entité est définie, nous allons définir une interface que l'on appelle également port qui va préciser comment interagir avec cette entité. Nous utilisons ici un modèle de conception d'inversion de dépendances qui nous permet de rester totalement libre sur les outils à utiliser pour respecter cette interface. Nous pourrons très bien implémenté cette interface en utilisant une base de données, une API ou un localStorage par exemple, le domaine s'en fiche.
Le service
Nous avons notre entité et nous savons commencer interagir avec, maintenant nous allons créer un service qui va consumer une implémentation du de notre interface repository (partie suivante dans l'infrastructure).
Infrastructure
L'infrastructure est composée des différentes implémentations des ports du domaine, on les appelle également Adapters. Ici, nous aurons du code spécifique pour consommer une technologie concrète (une base de données, une API, etc.). C'est une partie qui ne doit dépendre uniquement du domaine.
L'implémentation du repository
Nous allons maintenant voir l'une des implémentation possible de notre WalletRepository. Pour commencer nous allons faire du in-memory, pratique notamment pour la mise en place des premiers tests de nos cas d'utilisations.
Comment dis précédemment, il s'agit d'une des multiples implémentation possible de notre WalletRepository. Nous pouvons très bien imaginer plus tard mettre en place un LocalStorageWalletRepository ou bien un SupabaseWalletRepostory.
Vous pouvez consulter mon répertoire public de broney sur GitHub pour voir mon implémentation de ces 2 repository et notamment de comment j'ai adapté ma série de test pour garantir leur bon fonctionnement.
User Interface
La partie user interface est composée de tous les adaptateurs qui constituent les points d'entrée de l'application. Les utilisateurs utilisent ces adaptateurs pour pouvoir interagir avec le coeur de l'application. Dans notre cas nous allons régulièrement utiliser des stores en utilisant la libraire Zustand. Il s'agit d'une libraire JS minimaliste pour la gestion d'états (une solution plus complexe serait par exemple Redux).
Voyons voir comment articuler notre store Zustand pour permettre à l'utilisateur d'interagir avec le coeur de l'application.
Avec ce store on remarque qu'on va pouvoir facilement, dans n'importe quel environnement JavaScript, charger, définir, récupérer, créer, mettre à jour et supprimer des portefeuilles, tout en maintenant un état global pour l'ensemble des portefeuilles et du portefeuille courant.
Conclusion
Nous avons maintenant terminé ce deuxième article de cette série sur le développement d'une application web et mobile avec l'Architecture Hexagonale et le partage de la logique métier et des composants UI.
Dans cette deuxième partie nous avons vu comment travailler en TDD et surtout comment écrire de la logique métier sans avoir à ouvrir une quelque interface à l'exception du terminal pour les retours de tests.
Nous avons également eu un aperçu de comment nous allons interagir avec nos applications avec le coeur de l'application, via notre store Zustand. Nous irons plus loin à ce sujet dans le prochain article, la troisième partie : Partager de la logique métier et des composants entre le Web et le Mobile.
Hola, je vais vous présenter le début d'une nouvelle série d'articles dédiées à la construction d'un projet Web et Mobile en mettant à profit l'Architecture Hexagonale. Durant toute cette série, nous allons explorer comment la logique métier peut être partagée et gérée efficacement à travers différentes plateformes.
Nos objectifs
Nous allons avoir plusieurs objectifs à atteindre au fil de ce projet :
- Apprendre comment développer une application Web et Mobile à la fois en mettant à profit les technologies modernes (Nx, Expo, Remix, Vitest, etc.)
- Comprendre les principes de l'Architecture Hexagonale et comment l'appliquer pour optimiser le partage de la logique métier
- Gagner en compétence et en confiance pour lancer votre propre projet multi-plateforme, tout en développant une base de code propre et maintenable
La structure de la série
Comme je l'ai dis au début de ce premier article, ce projet donnera lieu à une série d'articles qui sera structurée de cette manière :
- Partie 1 (cet article) : présentation du projet et mise en place d'un monorepo avec Nx
- Partie 2 : développer sans UI avec l'Architecture Hexagonale
- Partie 3 : partager de la logique métier et des composants entre le Web et le Mobile
- Partie 4 : refactor serein avec les tests et l'Architecture Hexagonale
- Partie 5 : déploiement Web et Mobile avec Netlify et EAS
Le projet
Le projet qui va nous aider à mettre en avant l'Architecture Hexagonale est un outil de gestion de budget que l'on appellera broney (le bro qui t'aides à gérer ta money 😎). Cet outil sera composé de deux applications, une première, web, développée avec Remix et une deuxième, mobile, développée avec Expo. Nous aurons donc 2 applications React et React Native avec un package TypeScript qui contiendra la logique métier partagée entre ces 2 applications.
Stack
La Stack que j'ai choisi est très subjective, on y trouve quelques frameworks qui mérite selon moi plus de lumière (Remix notamment et Nx face à NextJS et Turborepo). Néanmoins il est important de comprendre que peu importe les frameworks et libraires utilisées, le coeur de l'application sera complètement agnostique et réutilisable dans n'importe quel contexte.
- Monorepo avec Nx
- Application mobile avec Expo
- Application web avec Remix
- Testing avec Vitest
- Style avec Tailwind pour le web et twrnc pour le mobile
- Animation avec Framer Motion pour le web et React Native Reanimated pour le mobile
- Déploiement de l'application web avec Netlify
- Base de données, authentification, etc. avec Supabase
- Formatage du code avec Prettier
- Validation du code avec ESLint
- CI/CD avec les GitHub Actions
- Gestion d'état avec Zustand
- Gestion des formulaires avec React Hook Form
- Validation des types avec Zod
- Logging avec Sentry
- Traductions avec FormatJS
- Utilitaire de date avec date-fns
Fonctionnalités
Pour mettre en avant l'Architecture Hexagonale nous allons avoir besoin de développer quelques fonctionnalités pour avoir de la logique métier. Nous allons nous focus sur les fonctionnalités suivantes :
- Mettre en place le storage : react native mmkv pour le mobile et localStorage pour le web
- Gérer les catégories : lister, ajouter, modifier et supprimer
- Gérer les portefeuilles : lister, ajouter, modifier et supprimer
- Gérer les transactions d'un compte : lister, ajouter, modifier et supprimer
- Authentification avec Supabase
- Dynamiser toute l'app avec Supabase
Modèle de données
Pour mettre en place les fonctionnalités nous allons avoir besoin des entités suivantes :
- Wallet, un portefeuille qui a un solde négatif ou positif (par exemple on peut avoir le portefeuille "Compte Principal Julien" qui a un solde positif de 1000€)
- Category, des catégories servant à préciser le contexte des transactions faites (par exemple on a les catégories "Maison", "Restaurants" et "Divertissements")
- Transaction, les transactions sont liées à un portefeuille et à une catégorie pour savoir où l'argent est transférée (par exemple on a une transaction du portefeuille "Compte Principal Julien" de 50€ sur la catégorie "Restaurants")
Mise en place du monorepo avec NX
Initialisation du projet
Nous allons utiliser les commandes de Nx pour initialiser notre projet.
Avec cette commande nous avons le projet Nx configuré de base et sans libs pour le moment. Nous allons travailler avec le style Package-Based Repos qui nous offre plus de liberté en limitant le couplage avec Nx si jamais on souhaite changer facilement d'outil de monorepo. Cela permet également d'avoir des node_modules différents pour chaque app ou lib du projet. En savoir plus sur les différents style d'implémentation de Nx.
Création de la lib core
Nous allons maintenant ajouter notre première lib, la plus importante : core. En effet, c'est dans cette lib que nous allons mettre notre Architecture Hexagonale et la logique métier qui sera utilisée par nos applications Web et Mobile.
Cette commande nous a généré une lib avec le framework de test Vitest, une config eslint et prettier que l'on peut adapter à nos preferences que je ne détaillerai pas ici.
Il est possible de compiler notre lib avec la commande nx core build et d'executer les tests avec nx core test.
Mise en place de la CI
Maintenant que nous avons les tests setup ainsi que prettier et eslint, il est pertinent de mettre en place une CI pour avoir du feedback régulier sur la bonne tenue du code. Pour la CI nous allons simplement suivre la documentation de Nx et utiliser les GitHub Actions.
Nous allons donc simplement ajouter un fichier .github/workflows/ci.yml assez simple qui peut être étoffé.
Cette simple CI permet vérifier le bon formatage prettier, d'effectuer les validations eslint et de build et de s'assurer que les tests sont sans erreurs.
Structure du projet
Rentrons plus en détails dans ce que l'on vise comme structure de projet une fois les apps mise en place et notre lib core développée avec l'architecture hexagonale.
- apps
- mobile : notre application React Native développée avec Expo
- web : notre application React développée avec React
- libs
- ui : nos composants React et React Native utilisés par les apps web et mobile
- tailwind : notre configuration tailwind utilisée par les apps web et mobile ainsi que la lib ui
- core : notre architecture hexagonale qui contient le coeur de notre application et toute la logique métier réutilisable par les apps web et mobile
Pour aller plus loin, on peut très bien envisager d'avoir une app en plus pour un Storybook.
La lib qui va nous intéresser et la lib core évidemment. Elle sera structurée de cette manière :
- libs
- core
- src
- wallet
- tests
- wallet.service.test.ts : la logique métier testées
- wallet.test.ts : les règles métiers testées
- domain
- wallet.ts : l'entité qui représente les portefeuilles et qui contient des règles métiers
- wallet.repository.ts: le contrat qui détermine comment manipuler l'entité pour lister, ajouter, etc.
- wallet.service.ts : le service qui consume une implémentation de contrat
- infrastructure
- in-memory-wallet.repository.ts : une implémentation du contrat
- local-storage-wallet.repository.ts : idem
- supabase-wallet.repository.ts : idem
- user-interface
- wallet.store.ts : un store zustand vanilla, utilisable dans n'importe quel environnement javascript et qui sera utilisé dans nos apps
- category
- ...
- ...
Nous verrons le contenu de chaque fichiers ainsi que les détails du fonctionnement de ces derniers dans le prochain article !
Conclusion
Nous avons terminé le premier article de cette série sur le développement d'une application web et mobile avec l'Architecture Hexagonale et le partage de la logique métier et des composants UI.
Dans cette première partie nous avons vu comment mettre un place un monorepo et nous avons pourquoi et comment ce monorepo va nous aider à partager la logique métier entre nos différentes applications. Nous avons également bien délimité le périmètre et les fonctionnalités attendues pour notre première version, le MVP, de broney.
Enfin, à la fin de cet article nous avons commencé à entrevoir la structure du projet en mettant en évidence l'Architecture Hexagonale, ce sera le thème de la deuxième partie : Développer sans UI avec l'Architecture Hexagonale.
Découvrons aujourd’hui l'univers captivant de l'architecture hexagonale. Cette approche du développement d'applications mobiles repose sur des principes fondamentaux, offrant une structure robuste et évolutive. Dans cet article, explorez les bases de l'architecture hexagonale, découvrez des exemples concrets sur GitHub et apprenez à l'intégrer avec Spring Boot. Optimisez votre code, maîtrisez l'inversion des dépendances et transformez votre façon de concevoir des applications mobiles.
Bienvenue dans le futur du développement logiciel !
Qu'est-ce que l'architecture hexagonale ?
L'architecture hexagonale redéfinit la conception des applications mobiles. À la base de cette approche novatrice se trouvent des principes clés, sculptant une structure en forme d'hexagone. Cette méthode se distingue par son agilité, son adaptabilité et son aptitude à créer des applications robustes. Découvrons les fondements de l'architecture hexagonale pour comprendre comment elle redéfinit le développement logiciel.
L'architecture hexagonale transcende les schémas conventionnels de développement logiciel. Imaginons-la comme une vue aérienne de votre application, où un hexagone représente le cœur, le noyau de votre système. Plongeons dans les détails de cette approche novatrice.
Au centre de cette structure, nous trouvons l'hexagone central. C'est le cœur, le noyau où réside la logique métier de votre application. Cet espace défini par l'hexagone représente l'essence même de ce que votre application offre à ses utilisateurs.
Les côtés de l'hexagone représentent les couches périphériques. Chacune de ces couches a un rôle spécifique dans l'interaction de l’application avec le monde extérieur. De la gestion des entrées/sorties à la persistance des données, ces couches entourent le noyau central, mais sans créer de dépendances directes avec lui.
Les interactions entre le cœur et les couches périphériques se font à travers des ports et adaptateurs. Les ports définissent des interfaces au sein du noyau, tandis que les adaptateurs fournissent des implémentations concrètes pour ces interfaces. Cette modularité offre une flexibilité essentielle, permettant à l'application de s'adapter sans altérer sa logique métier.
Enfin, l'inversion des dépendances est le principe qui gouverne l'architecture hexagonale. Plutôt que d'avoir des dépendances directes, le cœur de l'application dépend d'abstractions définies par les ports. Cette inversion crée un environnement flexible permettant des modifications sans impacter la stabilité du système.
Pour comprendre pleinement l'architecture hexagonale, explorons des exemples concrets.
L'architecture hexagonale ne se contente pas de suivre les sentiers battus du développement logiciel. Imaginez-la comme une vue aérienne de votre application, où un hexagone représente le cœur, le noyau vibrant de votre système. Plongeons dans les détails pour rendre cette approche plus tangible.
Au cœur, l'hexagone central incarne la logique métier de votre application. C'est là que réside l'essence de ce que votre application offre à ses utilisateurs. Autour de ce noyau, les côtés de l'hexagone représentent les couches périphériques. De la gestion des entrées/sorties à la persistance des données, chaque couche a un rôle précis dans l'interaction de l'application avec le monde extérieur.
Exemples concrets
Imaginons une application de gestion de tâches où le cœur de l'hexagone représente la logique de gestion des tâches, des deadlines, etc. Les côtés de l'hexagone pourraient inclure une couche d'interface utilisateur, une couche de persistance des données, et une couche de services externes.
Les interactions entre le cœur et les couches périphériques s'effectuent à travers des ports et adaptateurs. Les ports définissent des interfaces au sein du noyau, tandis que les adaptateurs fournissent des implémentations concrètes pour ces interfaces. Cette modularité offre une flexibilité essentielle, permettant à l'application de s'adapter sans compromettre sa logique métier.
Supposons que le port "GestionTâchesPort" définisse les opérations nécessaires à la gestion des tâches. L'adaptateur "GestionTâchesAdapter" fournirait l'implémentation concrète de ces opérations, interagissant avec la base de données et les services externes.
Enfin, l'inversion des dépendances règne en maître dans l'architecture hexagonale. Plutôt que des dépendances directes, le cœur dépend d'abstractions définies par les ports. Cette inversion crée un environnement souple, permettant des modifications sans secouer la stabilité du système.
Plutôt que d'avoir des dépendances directes vers la base de données, le cœur dépendrait d'interfaces définies dans le port "PersistancePort", laissant les détails d'implémentation à l'adaptateur "PersistanceAdapter".
En résumé, l'architecture hexagonale offre une vision stratégique du développement logiciel. Elle place la logique métier au centre, entourée de couches flexibles facilitant l'interaction avec le monde extérieur. Cette approche, avec son hexagone central et ses principes fondamentaux, ouvre la voie à des applications mobiles robustes, adaptables et pérennes.
Les principes de l'architecture hexagonale
L'architecture hexagonale repose sur des fondements solides, formant une structure en forme d'hexagone pour créer des applications mobiles robustes. Décortiquons les principes clés qui définissent cette approche innovante :
- L'architecture hexagonale est structurée en couches fondamentales. De la couche d'infrastructure à celle de persistance, chaque strate joue un rôle crucial. Cela offre une organisation claire, favorisant la stabilité et la modularité.
- Le point d'entrée représente l'accès initial à l'application, tandis que la logique métier dicte son fonctionnement interne. Cette dualité assure une expérience utilisateur fluide, équilibrant l'interaction extérieure avec la logique interne.
- Fondamentale à l'architecture hexagonale, l'inversion des dépendances renverse les schémas traditionnels. Cette approche permet à l'application de s'adapter aux changements sans compromettre sa stabilité. Elle crée un environnement où la logique métier guide les détails d'implémentation.
Mise en pratique de l'architecture hexagonale
Découvrons comment concrètement mettre en œuvre l'architecture hexagonale dans le développement d'applications mobiles. Plongeons dans des exemples tangibles pour comprendre son impact réel.
Explorez un exemple concret sur GitHub où le code source d'une application est dévoilé. Chaque composant, de la couche d'infrastructure à la couche de persistance, est clairement défini. Visualisez comment ces éléments s'entremêlent pour former une structure cohérente. Cette transparence simplifie le processus de développement, permettant une compréhension facile et une évolution efficace de l'application.
L'intégration pratique de l'architecture hexagonale est facilitée avec Spring Boot. Cette union offre une approche concrète pour développer des applications mobiles robustes. Elle simplifie la gestion des dépendances et maintient la flexibilité, permettant aux développeurs de se concentrer sur la création plutôt que sur des considérations techniques.
L'architecture hexagonale dans le contexte du Domain-Driven Design
Plongeons dans la synergie puissante entre l'architecture hexagonale et les principes du Domain-Driven Design (DDD), développant ainsi des applications mobiles de plus grande qualité.
L'architecture hexagonale et le Domain-Driven Design (DDD) fusionnent harmonieusement pour définir des modèles de domaine robustes offrant ainsi une approche complète du développement logiciel.
Lorsque nous plongeons l'architecture hexagonale dans le contexte du Domain-Driven Design (DDD), une collaboration symbiotique émerge. Ces deux approches, axées sur la compréhension profonde du domaine métier, se renforcent mutuellement.
1. Collaboration Harmonieuse
Imaginons une application de commerce électronique. Dans l'architecture hexagonale, le cœur de l'hexagone représente la gestion des commandes, des transactions, et des stocks, constituant la logique métier centrale. Dans le contexte du DDD, ces entités deviennent les agrégats du domaine, chacun avec son propre cycle de vie et ses règles métier spécifiques. Ainsi, l'hexagone central et les agrégats du DDD collaborent harmonieusement pour façonner le modèle de domaine.
2. Réflexion sur le Contexte Limité
Poursuivons avec la réflexion sur le contexte limité du DDD. Supposons que notre application de commerce électronique ait également un module de gestion des utilisateurs. Dans l'architecture hexagonale, cela devient une autre zone centrale, avec ses propres ports et adaptateurs. Dans le contexte limité du DDD, ce module représente son propre sous-domaine avec ses règles métier distinctes. Cette approche permet une séparation claire des préoccupations et une meilleure compréhension du modèle de domaine, alignant ainsi l'architecture hexagonale avec les principes du DDD.
3. Alistair Cockburn et les Fondements
Alistair Cockburn, un pionnier du Domain-Driven Design, souligne l'importance de définir des interactions précises entre les entités du domaine. Dans l'architecture hexagonale, cela se traduit par la définition précise des ports et adaptateurs, offrant une interface bien définie pour chaque interaction. Cette synchronicité entre les principes de Cockburn et l'architecture hexagonale garantit une compréhension approfondie du domaine et une mise en œuvre logicielle qui reflète fidèlement la réalité métier.
L'architecture hexagonale et le Domain-Driven Design forment une alliance puissante. En utilisant des exemples concrets, nous avons vu comment ces approches complémentaires collaborent pour créer des modèles de domaine clairs, des contextes limités bien définis, et des applications mobiles riches en fonctionnalités métier.
Nos conseils pratiques et astuces
Explorez des conseils concrets et des astuces judicieuses pour optimiser l'utilisation de l'architecture hexagonale dans le développement d'applications mobiles.
Dans la mise en œuvre de l'architecture hexagonale, privilégiez la clarté. Des noms de classes explicites aux commentaires informatifs, assurez-vous que chaque composant de votre application est compréhensible. La transparence facilite la collaboration et la maintenance à long terme.
Investissez dans des tests unitaires approfondis. L'architecture hexagonale favorise la testabilité, alors profitez-en. Des tests solides garantissent la stabilité de votre application et facilitent l'identification rapide des problèmes potentiels.
Accompagnez votre code d'une documentation complète. Décrivez les choix architecturaux, les interactions clés, et les modèles de domaine. Une documentation détaillée facilite l'intégration de nouveaux membres dans l'équipe et assure une compréhension globale du projet.
Soyez sélectif quant aux dépendances. Limitez-vous aux dépendances nécessaires pour éviter la complexité inutile. Une architecture hexagonale bien conçue privilégie la simplicité, ce qui facilite la maintenance et l'évolutivité.
Adoptez une approche itérative. L'itération continue associée au réajustement est essentielle. Recueillez les retours, identifiez les améliorations possibles, et évoluez constamment. Cette approche flexible s'aligne parfaitement avec les principes de l'architecture hexagonale.
L'architecture hexagonale se révèle comme une approche incontournable pour le développement d'applications mobiles. Avec ses principes solides, sa mise en pratique transparente, et sa synergie avec le Domain-Driven Design, elle offre une solution robuste et flexible.
Priorisez la clarté, investissez dans des tests unitaires approfondis, documentez judicieusement, évitez les dépendances superflues, et adoptez une approche itérative pour un succès continu.
En embrassant l'architecture hexagonale, vous développez des applications mobiles plus résilientes et créez une base pour l'innovation future. Restez agile, apprenez constamment, et évoluez avec votre application.
L'architecture hexagone est le socle sur lequel repose l'avenir du développement logiciel mobile.

Dans l'univers du développement d'applications mobiles, la gestion des versions de Node.js est cruciale. Découvrez ici comment utiliser Node Version Manager (NVM) pour changer, installer des versions LTS, et éviter les conflits. Que vous soyez débutant ou expert, ce guide vous aidera à maîtriser cet outil essentiel.
Comprendre l'importance de Node Version Manager (NVM)
L'utilisation de différentes versions de Node.js peut être délicate. NVM simplifie ce processus en vous permettant de basculer facilement entre les versions. Vous évitez ainsi les conflits et assurez la compatibilité de vos projets.
NVM offre une flexibilité totale pour installer et gérer des versions spécifiques de Node.js en fonction de vos besoins. Son utilisation est simple, même pour les débutants, avec des commandes intuitives. NVM vous protège contre les conflits de versions en isolant les environnements
NVM garantit que vos projets restent compatibles avec la version de Node.js sur laquelle ils ont été développés. Vous pouvez également mettre à jour vos projets en douceur sans crainte de problèmes de compatibilité.
En automatisant la gestion des versions de Node.js, NVM vous permet de vous concentrer sur le développement plutôt que sur la résolution de problèmes de version. C'est un gain de temps précieux.
En comprenant ces points, vous serez mieux préparé à tirer parti de Node Version Manager (NVM) dans votre travail de développement Node.js.
Installation de Node Version Manager
L'installation de Node Version Manager (NVM) est la première étape essentielle pour gérer vos versions Node.js. Cette section vous guidera à travers le processus d'installation sur différentes plateformes :
- Linux : Utilisez la commande wget pour récupérer NVM depuis GitHub. Suivez notre guide étape par étape pour une installation sans faille.
- macOS : Apprenez comment installer NVM sur macOS en utilisant la commande curl. Suivez nos instructions pour garantir une installation réussie.
- Windows : Si vous êtes sur Windows, découvrez comment installer NVM en utilisant des outils tels que Git Bash ou Windows Subsystem for Linux (WSL).
Après l'installation, nous vous montrerons comment configurer NVM pour une utilisation optimale. Vous serez prêt à commencer à gérer vos versions Node.js avec aisance.
Familiarisez-vous avec les commandes de base de NVM, telles que nvm --version pour vérifier la version installée, nvm ls pour afficher les versions disponibles et nvm install pour installer une version spécifique.
Suivez les instructions détaillées dans cette section pour installer NVM sur votre plateforme de choix. Vous serez rapidement opérationnel pour gérer vos versions Node.js de manière fluide.
Utilisation de NVM pour installer la dernière version LTS de Node.js
Maintenant que vous avez installé Node Version Manager (NVM), apprenons comment utiliser cet outil pour installer la dernière version LTS (Long Term Support) de Node.js.
Avant de procéder à l'installation, il est essentiel de savoir quelles versions LTS de Node.js sont disponibles. Vous pouvez le faire en utilisant la commande nvm ls-remote --lts.
Suivez ces étapes simples pour installer la dernière version LTS :
- Exécutez
nvm install --ltspour installer la dernière version LTS disponible. - Pour vérifier que l'installation a réussi, utilisez
node --versionpour afficher la version de Node.js installée.
Si vous souhaitez que la dernière version LTS soit la version par défaut utilisée par NVM, exécutez nvm alias default <version>.
Grâce à ces étapes simples, vous pouvez désormais installer et utiliser la dernière version LTS de Node.js avec facilité en utilisant Node Version Manager (NVM). Cela vous permettra de bénéficier des avantages de stabilité et de support à long terme pour vos projets Node.js.
Gestion de multiples versions de Node.js avec NVM
La gestion de plusieurs versions de Node.js est une nécessité pour de nombreux développeurs. Voici comment utiliser Node Version Manager (NVM) pour gérer efficacement ces versions.
Pour voir toutes les versions de Node.js installées sur votre système, utilisez simplement la commande nvm ls. Vous obtiendrez une liste claire de toutes les versions disponibles.
Pour basculer entre les versions, utilisez la commande nvm use <version>. Cela changera votre environnement de développement pour utiliser la version spécifiée.
Vous pouvez également créer des alias pour des versions spécifiques avec nvm alias <alias> <version>. Cela simplifie encore la gestion des versions.
Avec ces commandes simples, vous pouvez gérer facilement plusieurs versions de Node.js sur votre système, en utilisant Node Version Manager (NVM). Cela vous permet de maintenir la compatibilité de vos projets et de travailler sur des versions spécifiques selon vos besoins.
Mettre à jour Node.js avec NVM
Maintenir votre installation Node.js à jour est crucial pour bénéficier des dernières fonctionnalités et correctifs de sécurité. Voici comment effectuer des mises à jour en utilisant Node Version Manager (NVM).
Pour vérifier si des mises à jour sont disponibles, exécutez nvm ls-remote <version>. Cela affichera les versions de Node.js disponibles à la mise à jour.
Pour mettre à jour Node.js vers la dernière version LTS disponible, utilisez nvm install --lts. Cela installera la dernière version LTS sans affecter vos versions précédentes.
Si vous avez une version spécifique que vous souhaitez mettre à jour, utilisez nvm install <version> pour obtenir la dernière version de cette branche.
En utilisant ces commandes simples, vous pouvez maintenir votre installation Node.js à jour avec facilité, en garantissant que vos projets sont toujours optimisés en termes de performances et de sécurité.
Exemples pratiques et code source
Dans cette section, nous explorerons quelques exemples pratiques d'utilisation de Node Version Manager (NVM) avec des extraits de code source pour une meilleure compréhension.
Exemple 1 : Installation de Node.js LTS

Cette commande installe la dernière version LTS de Node.js.
Exemple 2 : Basculer vers une version spécifique

Utilisez cette commande pour basculer vers une version spécifique de Node.js (dans cet exemple, la version 14.17.6).
Exemple 3 : Créer un alias pour une version

Créez un alias pour définir une version spécifique de Node.js comme version par défaut.
Exemple 4 : Vérifier les versions installées

Cette commande affiche la liste des versions de Node.js installées sur votre système.
Exemple 5 : Mise à jour de Node.js
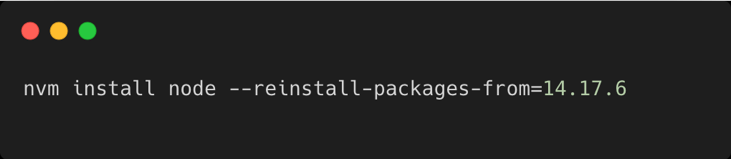
Mettez à jour Node.js vers la dernière version (ici, la version actuelle) tout en conservant les packages de la version précédente.
Utilisez ces exemples pratiques et extraits de code source pour mieux comprendre comment utiliser NVM dans vos projets Node.js. Cela vous aidera à gérer efficacement les versions et à optimiser votre environnement de développement web.
Les meilleures pratiques de gestion des versions Node.js
Pour tirer le meilleur parti de Node Version Manager (NVM) et maintenir un environnement de développement Node.js efficace, suivez ces meilleures pratiques :
- Gardez NVM à jour : Pensez à mettre à jour régulièrement NVM pour bénéficier des dernières améliorations et corrections de bogues.
- Utilisez les versions LTS : Privilégiez les versions LTS (Long Term Support) pour une stabilité à long terme. Cela garantit que vos projets restent stables et sécurisés.
- Créez des alias significatifs : Lors de la création d'alias pour des versions spécifiques, choisissez des noms significatifs pour vous faciliter la gestion.
- Documentez vos projets : Tenez un journal des versions utilisées pour chaque projet afin de garantir une compatibilité continue.
- Gérez les dépendances avec npm : N'utilisez pas NVM pour gérer les dépendances de vos projets. Utilisez npm pour gérer les packages Node.js spécifiques à chaque projet.
- Restez informé : Suivez les annonces de nouvelles versions Node.js et les mises à jour de sécurité pour rester au courant des dernières avancées.
En suivant ces meilleures pratiques, vous optimiserez votre gestion des versions Node.js avec NVM et garantirez la stabilité, la sécurité et la facilité de gestion de vos projets.
Dans cet article, nous avons exploré en détail l'utilisation de Node Version Manager (NVM) pour la gestion des versions Node.js. Que vous soyez un développeur expérimenté ou que vous découvriez Node.js, NVM est un outil essentiel pour maintenir un environnement de développement propre et efficace.
Nous avons abordé les étapes clés, de l'installation de NVM sur différentes plateformes à la gestion de multiples versions de Node.js, en passant par les mises à jour et les meilleures pratiques. En utilisant NVM, vous pouvez facilement basculer entre les versions, maintenir la compatibilité de vos projets et garantir la sécurité de votre environnement de développement.
Les exemples pratiques et les extraits de code source ont été fournis pour vous aider à mieux comprendre comment utiliser NVM dans vos projets. En suivant les meilleures pratiques recommandées, vous pouvez maintenir un environnement de développement Node.js optimal.
En fin de compte, Node Version Manager (NVM) est un outil puissant qui facilite grandement la gestion des versions Node.js. Il vous permet de rester à jour avec les dernières versions, d'adapter vos projets aux besoins spécifiques et de maintenir un flux de travail de développement efficace. Intégrez NVM dans votre boîte à outils de développement Node.js dès aujourd'hui pour une expérience de développement plus fluide et plus productive.
Maintenant que vous savez correctement utiliser NVM, nous vous invitons à consulter notre guide complet sur l’outil de gestion de versions Git.

Dans le domaine de la gestion des données, le choix entre Hard Delete et Soft Delete peut avoir un impact significatif sur la sécurité et la récupération des informations. Ces deux méthodes de suppression de données sont essentielles pour les développeurs et les administrateurs de bases de données.
Dans cet article, nous explorerons en détail ce qu'est le Hard Delete et le Soft Delete, leurs avantages respectifs, et comment choisir la meilleure approche en fonction des besoins spécifiques de votre projet. Nous fournirons également des exemples de code source pour illustrer leur mise en œuvre, afin que même les novices puissent comprendre ces concepts fondamentaux.
Comprendre la différence entre Hard Delete et Soft Delete
La gestion des données supprimées est une composante cruciale de toute application ou système de gestion de bases de données. Comprendre les distinctions entre le Hard Delete et le Soft Delete est le point de départ pour prendre des décisions éclairées.
Hard Delete : La Suppression Définitive
- Le Hard Delete, également connu sous le nom de suppression définitive, signifie que les données supprimées sont éliminées de manière permanente de la base de données.
- Cela signifie qu'une fois que vous avez effectué un Hard Delete, les données sont irrécupérables.
- Exemples de scénarios où le Hard Delete est approprié : suppression de données sensibles ou obsolètes, respect de la conformité légale.
Soft Delete : La suppression réversible
- Le Soft Delete, contrairement au Hard Delete, implique une suppression réversible.
- Les données supprimées sont marquées comme "supprimées" mais restent dans la base de données.
- Cela permet la récupération des données supprimées si nécessaire, offrant une couche de sécurité supplémentaire.
- Utilisation courante du Soft Delete : préservation de l'historique des données, récupération en cas d'erreur de suppression.
En comprenant la différence fondamentale entre le Hard Delete et le Soft Delete, vous pouvez commencer à évaluer quelle méthode convient le mieux à votre projet. La prochaine section examinera les avantages de chacune de ces méthodes pour vous aider à prendre une décision éclairée.
Les avantages du Hard Delete
Le Hard Delete est une méthode de suppression de données qui peut s'avérer essentielle dans certaines situations. Examinons de plus près les avantages qu'il offre :
L'un des principaux avantages du Hard Delete réside dans la sécurité qu'il offre. Lorsque vous effectuez un Hard Delete, les données sont supprimées de manière permanente de la base de données.
Cela garantit qu'aucune trace des données supprimées ne subsiste, réduisant ainsi le risque de divulgation d'informations sensibles.
Dans certains secteurs, comme la santé ou les finances, la conformité légale est cruciale. Le Hard Delete permet de répondre à ces exigences en supprimant irrévocablement les données.
En supprimant définitivement les données, le Hard Delete peut contribuer à améliorer les performances de la base de données en libérant de l'espace et en réduisant la charge de travail du système.
Le Hard Delete simplifie la gestion des données, car il n'est pas nécessaire de gérer un ensemble de données supprimées de manière réversible. Cela peut simplifier les processus de sauvegarde et de restauration.
Pour mieux comprendre la mise en œuvre du Hard Delete, voici un exemple de code SQL montrant comment effectuer une suppression permanente dans une base de données :

Les avantages du Soft Delete
Le Soft Delete, bien que différent du Hard Delete, présente des avantages significatifs dans certaines situations. Examinons en détail les avantages qu'il offre !
L'un des principaux avantages du Soft Delete est la capacité à récupérer des données supprimées par erreur. Les données marquées comme "supprimées" restent dans la base de données et peuvent être restaurées si nécessaire.
Le Soft Delete permet de conserver un historique complet des données, y compris celles qui ont été supprimées. Cela peut être utile pour l'audit, la conformité ou l'analyse des tendances historiques.
En évitant la suppression permanente des données, le Soft Delete offre une couche de protection contre les erreurs humaines, telles que la suppression accidentelle de données critiques.
Lors de la mise en œuvre de nouvelles fonctionnalités ou de modifications de la structure de la base de données, le Soft Delete permet une transition en douceur en conservant les données existantes.
Pour mieux comprendre la mise en œuvre du Soft Delete, voici un exemple de code SQL montrant comment marquer une ligne de données comme "supprimée" sans la supprimer définitivement :

Quand utiliser chacune des méthodes
La décision entre Hard Delete et Soft Delete dépend largement des exigences particulières de votre projet. Voici des conseils pour vous aider à faire le choix approprié :
Choisissez le Hard Delete lorsque la sécurité des données est une priorité absolue. Par exemple, dans les applications de santé ou financières, il est préférable d'opter pour une suppression définitive.
Si la récupération des données supprimées est essentielle, le Soft Delete est la meilleure option. Cela s'applique notamment aux systèmes où les erreurs de suppression peuvent se produire.
Pour respecter les réglementations strictes qui exigent la suppression permanente de données, le choix du Hard Delete est nécessaire.
Si vous avez besoin de conserver un historique complet des données, optez pour le Soft Delete. Cela est particulièrement utile pour l'audit et la conformité.
Si vous souhaitez optimiser la performance de la base de données en réduisant la charge, le Hard Delete peut être plus approprié, car il libère de l'espace.
Envisagez le Soft Delete lorsque vous prévoyez d'introduire de nouvelles fonctionnalités ou des changements structurels dans la base de données, car il permet une transition en douceur.
En évaluant soigneusement les besoins de votre projet en fonction de ces critères, vous pourrez prendre une décision éclairée quant à l'utilisation du Hard Delete ou du Soft Delete. Gardez à l'esprit que dans certains cas, une combinaison des deux méthodes peut également être envisagée pour répondre aux besoins spécifiques de votre application.
Le choix entre Hard Delete et Soft Delete est une décision cruciale dans la gestion des données. Chacune de ces méthodes présente des avantages distincts, et le choix dépend des besoins spécifiques de votre projet.
Le Hard Delete offre une sécurité maximale en supprimant définitivement les données, ce qui le rend idéal pour les applications où la confidentialité et la conformité légale sont essentielles. Cependant, il faut être prudent, car les données sont irrécupérables.
Le Soft Delete, quant à lui, permet la récupération des données supprimées, préservant ainsi un historique complet et offrant une protection contre les erreurs humaines. Il est particulièrement adapté aux systèmes où la récupération des données est une priorité.
Le choix entre ces deux méthodes peut également dépendre des contraintes de performance de votre base de données et de la flexibilité nécessaire pour les futures modifications.
En fin de compte, il n'y a pas de réponse universelle. Il est essentiel d'évaluer les besoins de votre projet et de choisir la méthode qui répond le mieux à ces exigences spécifiques. Dans certains cas, une combinaison des deux méthodes peut également être envisagée pour une gestion des données supprimées plus complète.
Quelle que soit la méthode choisie, la gestion des données supprimées est une composante essentielle de tout système de base de données bien conçu. En comprenant les avantages du Hard Delete et du Soft Delete, vous êtes mieux préparé à prendre des décisions éclairées pour garantir la sécurité et la flexibilité de votre application.
N'hésitez pas à partager vos propres expériences et réflexions sur ce sujet dans les commentaires ci-dessous. La gestion des données supprimées est une discipline en constante évolution, et l'échange d'idées peut bénéficier à l'ensemble de la communauté de développement.

Lorsque l’on développe une solution SaaS, il est nécessaire de bien penser son architecture, surtout si à l’avenir vous réfléchissez déjà à faire découpler plusieurs instances de celle-ci.
Pour imager, prenons pour exemple un site e-commerce.
Vous pouvez faire le choix de partir sur une architecture simple pour votre MVP, avec tout simplement votre boutique à Paris, mais dès lors où le besoin d’avoir plusieurs boutiques se présente, plusieurs questions vont venir à vous.
Ces questions pourraient concerner :
La gestion du stock : est-elle centralisée ? Y-a-t’il un stock par boutique ?
La gestion des produits : est-ce que chaque boutique est indépendante, est-ce qu’elle a ses propres produits ?
La gestion des utilisateurs : est-ce que je stocke les données utilisateurs par boutique ? Est-ce que j’ai une base commune d’utilisateurs ?
Toutes vos réponses vont impacter la façon dont vous allez mettre en place le multi-tenant.
Le multi-tenant
Vous l’avez compris, on parle de multi-tenant lorsque l’on doit gérer plusieurs contextes dans une application, si l’on devait reprendre notre exemple précédent on considèrerait chaque boutique comme un contexte.
.png)
Gestion en single-database
La gestion du multi-tenant au moyen d'une seule base de données présente plusieurs avantages significatifs.
.png)
Tout d'abord, elle simplifie considérablement la maintenance car il n'y a qu'une seule base a gérer en cas de bugs ou de restauration des backups.
De plus, la base de données demeure relativement simple à gérer avec l'utilisation d'un champ tenant_id (store_id) pour distinguer les différents tenants.
Cela offre un avantage financier car il n'y a pas de surcoût au niveau de l'infrastructure.
L'approche du multi-tenant avec une seule base de données comporte également certains inconvénients notables.
Dans le cas de l'utilisation d'un Framework PHP tel que Laravel ou Symfony par exemple, l'adaptation des packages de la communauté ainsi que des requêtes SQL est nécessaire, ce qui peut entraîner des coûts de développements supplémentaires.
En effet, il faudra ajouter un critère à chaque requête pour spécifier le bon tenant à utiliser, un oubli entraînerait des conséquences assez importantes.
De plus, la centralisation des données peut rendre la restauration de données complexe si on a besoin de restaurer les données pour un tenant précis.
Gestion en single-database multi-schema
Une alternative possible dans l'implémentation du multi-tenant consiste à attribuer à chaque tenant ses propres tables au sein de la base de données.
.png)
Cette approche offre une isolation accrue et la gestion des données s'en retrouve simplifiée. Tout comme pour l'implémentation précédente, la restauration des données reste simple. En adoptant cette approche, on ajoute donc une séparation des données de tenants.
Cependant, cette approche présente également quelques inconvénients.
La nécessité de restaurer un tenant spécifique peut être plus compliquée, car il faut sélectionner individuellement chacune des tables lors du backup ou lors de la restauration.
De plus, à mesure que le nombre de tenants augmente, le nombre de tables associées peut devenir considérable, ce qui risque de compliquer la gestion à long terme.
Si des modifications sont apportées à la structure d'une table, chaque table dupliquée pour chaque tenant doit être mise à jour individuellement.
Cela rend également la gestion des migrations compliquées avec des frameworks comme Laravel ou Symfony puisqu'ils n'ont pas été prévu à cet effet.
Gestion en multi-database
L'utilisation du multi-tenant avec une base de données spécifique par tenant offre plusieurs avantages.
.png)
Une simplicité côté développement, où il suffit de spécifier quel tenant est utilisé sans adaptations complexes de packages ou de requêtes SQL. L'implémentation est donc plus rapide et le code plus facile à maintenir.
Pour le backup et la restauration, il suffit de le faire sur la base de données du tenant.
On peut optimiser les performances en ajustant les ressources allouées à chaque tenant en fonction de ses besoins.
C’est également le schéma idéal si dans un projet chaque tenant correspond à un site client et que ces clients souhaitent une confidentialité et isolation de leur données.
Et pour les désavantages de cette implémentation, on peut avoir plus de serveurs ou plus de base de données à maintenir, il faut avoir quelques bases côté infrastructure pour mettre en place et configurer les environnements et le coût d'infrastructure sera plus conséquent.
Conclusion
Chaque architecture a ses avantages et inconvénients, la décision devra se prendre en fonction de vos besoins, de vos coûts, de l’effectif de votre équipe et de nombreux facteurs qui composeront la pérennité de votre projet.
Sur le Framework Laravel, en PHP, plusieurs packages existent pour gérer le multi-tenant. Si on devait en opposer deux, le package Laravel Multitenancy de Spatie propose une implémentation simple et légère qu’il faudra agrémenter de “Tasks” selon le mode de gestion que vous allez choisir, tandis que le package Tenancy d’ArchtechX propose plutôt une architecture plus complexe qui répond à un maximum de besoins avec plus d'opinion.
Il est primordial de s’intéresser à chacune des solutions existantes et de créer des POCs avant de se lancer tête baissée dans l’implémentation du multi-tenant.
Et vous ? Lequel de ces packages choisiriez-vous ?
Si vous hésitez encore pas de panique ! Nous étudierons sans doute plus en détails les différences dans un prochain article.

Le database branching est une approche d’organisation de base de données qui permet de reproduire la dynamique et le fonctionnement des branches Git.
On va alors pouvoir à partir d’une base de données appelé “master” pouvoir dupliquer une “branche” avec un certain nom. Cette nouvelle base de données se vera hériter des données ainsi que des migrations de la branche source.
Les cas d’usages de ce principe sont multiples et variés. Si nous reprenons l’analogie avec Git flow, lorsque vous allez créer une nouvelle branche de feature, vous serez amené à devoir développer puis appliquer une migration de données ou bien tout simplement altérer les données contenues dans cette base. Elle devient à partir de là un bac à sable tout en partant d’un environnement déjà prédéfini.
Grâce à la nouvelle base de données mise en place pour votre feature, vous n’allez impacter aucun environnement de production / staging / dev mis en place et accessible par tous les développeurs.
Votre base de données sera alors unique et éphémère, une fois la feature terminée, celle-ci pourra être supprimée.
Elle peut aussi servir de base de données temporaire pour une démonstration client, alimentée de données bien précises pour cette dite démonstration.
Pour terminer cette introduction, j’ajouterai que le database branching est présent avant tout pour améliorer la “DX” des développeurs au quotidien.
Pourquoi ne pas alors simplement produire une base de données sur ma machine ?
Il est autant possible que l’infrastructure du projet mette à disposition un cluster de base de données sur un serveur ou bien qu’un développeur puisse créer son cluster sur sa machine.
Avec un provisionnement type Docker vous pouvez déployer rapidement une base de données sur votre machine avec un script de seeding permettant d’alimenter cette base en données. Cependant, vous allez perdre une composante essentielle au database branching qui est la synchronisation de la branche Git avec les données. En effet, si vous êtes plusieurs développeurs à intervertir sur cette feature / environnement, aucune manipulations supplémentaires ne sera à faire lors du passage sur la branche Git. Vous récupérez la base de données déjà préparée par le précédent développeur.
Vous allez aussi avoir la problématique d’espace disponible sur votre machine, si vous travaillez sur plusieurs branches en même temps, cela implique de pouvoir posséder un conteneur d’une base de données unique par branche. Donc, une grande quantité de données en local.
Comment s’intègre le Database branching dans le workflow du développeur
Comme n’importe quel outil s’ajoutant sur une stack d’un projet, le database branching viens complexifier quelques aspects techniques de celui-ci.
Alors, il est nécessaire d’automatiser le maximums d’aspects du database branching afin de ne pas augmenter le nombre de tâches à réaliser par les développeurs lors de la création d’une nouvelle feature.
En laissant certaines tâches manuelles, nous risquons de frustrer nos collègues développeurs. En effet, il est très facile d’oublier d’exécuter une certaine commande après un changement de branche.
Dans la deuxième partie de l’article nous nous intéresseront à réaliser un environnement de développement fluide avec l’exemple d’une stack web.
Je dirai alors que le database branching idéal est celui qui est complètement transparents pour les développeurs.
Dans la finalité ce principe est plus ou moins une idéologie, le degrés de l’implémentation peut dépendre de l’envergure du projet et du nombre de développeurs.
Tutoriel: Mise en place du database branching sur une stack Typescript, Prisma
Initialisation du projet et de la base de donnée
La première étape de ce tutoriel sera de se munir d’une base de données avec un utilisateur ayant l’autorisation de créer des database supplémentaires.
Voici plusieurs providers proposant ce service:
Actuellement nous utilisons une base de données hébergée Aurora Serverless hébergée sur AWS déployée depuis Terraform avec le module suivant.
Pour la suite de ce tutoriel nous avons choisis d’utiliser une base de données PostgreSQL. Il est aussi tout à fait possible de l’intégrer sur une base de données MongoDB, MySQL, …
Pour passer rapidement sur les étapes d’initialisation du projet TS avec Prisma je vous redirige vers la documentation officielle de Prisma.
Après toutes ces étapes vous devriez avoir dans la racine de votre projet un fichier d’environnement nommé .env qui possède une url de base de données DATABASE_URL.
À présent nous pouvons remplacer cette url par celle de notre base de données provisionnée un peu plus haut.
DATABASE_URL="postgresql://gabriel:password@db-branching.cluster-xxxxxxx.eu-west-3.rds.amazonaws.com:5432/master?schema=public"
La database pointée (master dans ce cas-là) importe peu, elle sera mise à jour par la suite automatiquement.
Automatisation du changement de branche
Afin de faciliter le passage sur une nouvelle base de données à chaque changement de branche git, il est possible de créer un hook sur le projet git, qui sera exclusivement lancé lors d'une commande git checkout.
Pour celà nous utiliserons un outil facilitant la création de hook git nommé Husky.
Voici les commandes d’installation que vous pouvez retrouver dans la documentation officielle:
.png)
Cette dernière commande va alors créer un script bash dans le dossier suivant.husky/post-checkout.
On ajoutera ces trois lignes de bash permettant de récupérer la branche git lors d’un checkout et de mettre à jour le fichier .env
.png)
Et voilà !
Maintenant à chaque changement de branche en local votre .env sera mis à jour automatiquement.
Il est possible d’aller plus loin en ajoutant l’application automatique des migrations de la base données et/ou le seeding de data.

