Le Data Engineer conçoit les pipelines et architectures de données qui alimentent vos décisions stratégiques et vos applications intelligentes. Un rôle clé.
Ce qu'un Data Engineer apporte à votre projet
Le Data Engineer est le bâtisseur des fondations data de votre organisation. Sans lui, vos données restent des silos isolés, inexploitables et coûteux à maintenir. Avec lui, elles deviennent un actif stratégique capable d'alimenter vos décisions, vos modèles prédictifs et vos applications intelligentes. Dans un contexte où la donnée est souvent qualifiée de « nouveau pétrole », le Data Engineer est celui qui construit les raffineries : les pipelines d'ingestion, de transformation et de distribution qui rendent la donnée brute exploitable à grande échelle.
Concrètement, le Data Engineer intervient pour structurer, fiabiliser et automatiser l'ensemble de votre chaîne de données. Il conçoit les architectures qui permettent de collecter des données depuis des sources hétérogènes (bases de données opérationnelles, API tierces, fichiers plats, flux temps réel, capteurs IoT), de les transformer selon des règles métier précises, et de les rendre disponibles aux équipes qui en ont besoin : analystes, data scientists, équipes marketing, direction financière. Sans cette infrastructure, vos initiatives data science et vos projets d'intelligence artificielle ne peuvent tout simplement pas décoller.
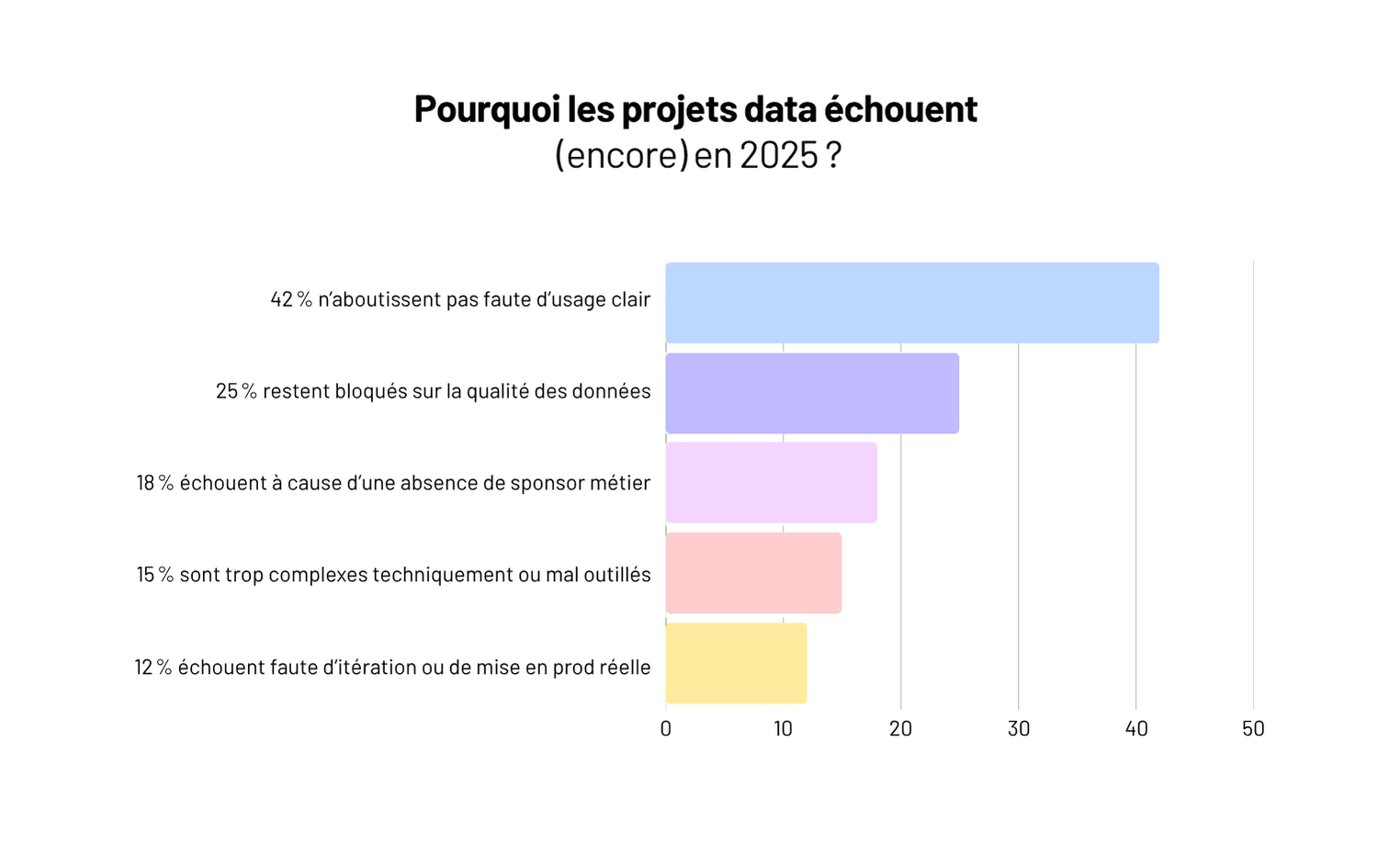
Ce profil devient indispensable dès que votre organisation manipule des volumes de données significatifs ou que vous souhaitez exploiter vos données de manière systématique. Que vous lanciez un projet de business intelligence et dataviz, que vous mettiez en place des systèmes prédictifs, ou que vous souhaitiez alimenter une application en données temps réel, le Data Engineer est le premier profil à mobiliser. Il est la condition préalable à tout projet data ambitieux : sans pipelines fiables, les modèles de machine learning s'entraînent sur des données erronées, les dashboards affichent des chiffres incohérents et les décisions prises sur la base de ces données sont faussées.
Pour mesurer l'impact d'un Data Engineer, considérons le coût de son absence. Les équipes métier passent en moyenne 40 à 60 % de leur temps à chercher, nettoyer et réconcilier des données plutôt qu'à les analyser. Les data scientists consacrent jusqu'à 80 % de leur temps à la préparation des données plutôt qu'à la modélisation. Un Data Engineer élimine ces gaspillages en automatisant les flux de données et en garantissant leur qualité en amont. L'investissement se rentabilise en quelques semaines par les gains de productivité des équipes en aval.
Chez Yield Studio, nous constatons que les projets data les plus réussis sont ceux qui commencent par poser des fondations solides en data engineering. Trop d'organisations investissent dans des outils de visualisation ou des modèles de machine learning avant d'avoir résolu le problème fondamental : la qualité, la disponibilité et la gouvernance de leurs données. Le Data Engineer est le profil qui résout ce problème en premier, permettant ensuite à tous les autres profils data — data scientists, analystes, ingénieurs ML — de travailler efficacement.
Missions concrètes dans un projet client
Chez Yield Studio, le Data Engineer intervient sur des missions structurantes qui couvrent l'ensemble du cycle de vie de la donnée. Voici les missions types qu'il mène au quotidien dans le cadre d'un engagement client :
Conception et construction des pipelines de données
- Ingestion de données multi-sources : le Data Engineer conçoit les connecteurs qui extraient les données depuis vos systèmes opérationnels (ERP, CRM, bases de données transactionnelles), vos API tierces (Google Analytics, réseaux sociaux, partenaires), vos fichiers plats (CSV, Excel, JSON) et vos flux temps réel (événements applicatifs, logs, capteurs IoT). Chaque connecteur est conçu pour être robuste, idempotent et capable de gérer les erreurs sans perte de données.
- Transformation et nettoyage : il implémente les règles de transformation qui convertissent les données brutes en données exploitables. Cela inclut le nettoyage (suppression des doublons, gestion des valeurs manquantes, normalisation des formats), l'enrichissement (jointures entre sources, calculs dérivés, géocodage) et l'agrégation (résumés par période, par entité, par segment). Ces transformations sont versionnées, testées et documentées pour garantir leur fiabilité.
- Orchestration des flux : le Data Engineer met en place un orchestrateur (Apache Airflow, Dagster, Prefect) qui planifie et supervise l'exécution des pipelines. L'orchestrateur gère les dépendances entre les tâches, les retries en cas d'échec, les alertes en cas d'anomalie et le monitoring de la performance des pipelines. Cette orchestration garantit que les données sont fraîches, complètes et disponibles quand les utilisateurs en ont besoin.
- Pipelines temps réel : pour les cas d'usage qui nécessitent une latence faible (détection de fraude, personnalisation en temps réel, monitoring opérationnel), le Data Engineer conçoit des architectures de streaming basées sur Apache Kafka, Apache Flink ou des services managés cloud. Ces architectures traitent les événements au fil de l'eau et alimentent les systèmes en aval en quasi-temps réel.
Architecture des plateformes de données
- Conception du data warehouse ou data lakehouse : le Data Engineer choisit et met en place l'architecture de stockage la plus adaptée à vos besoins. Il conçoit le modèle dimensionnel (schéma en étoile, snowflake) ou le data lakehouse (Delta Lake, Apache Iceberg) qui structure vos données pour des requêtes performantes et une maintenance aisée. Le choix entre ces approches dépend du volume de données, de la variété des cas d'usage et des contraintes de budget.
- Modélisation des données : il définit le modèle de données qui représente fidèlement votre réalité métier. Ce modèle est le contrat entre les producteurs de données et les consommateurs : il garantit que les métriques clés (chiffre d'affaires, nombre de clients actifs, taux de conversion) sont calculées de manière cohérente partout dans l'organisation. Le Data Engineer utilise des approches comme dbt pour versionner et tester ces modèles.
- Gouvernance et qualité des données : il met en place les contrôles de qualité automatisés (tests de schéma, tests de fraîcheur, tests de complétude, détection d'anomalies) qui garantissent la fiabilité des données. Il définit le catalogue de données (data catalog) qui documente chaque table, chaque champ et chaque métrique, permettant aux utilisateurs de comprendre et de faire confiance aux données qu'ils utilisent.
- Sécurité et conformité : le Data Engineer implémente les politiques de sécurité (chiffrement au repos et en transit, contrôle d'accès par rôle, anonymisation des données personnelles) et de conformité (RGPD, rétention des données, droit à l'effacement). Ces aspects sont intégrés dès la conception de l'architecture, pas ajoutés après coup.
Optimisation et scalabilité
- Optimisation des performances : le Data Engineer identifie et résout les goulots d'étranglement dans les pipelines et les requêtes. Il optimise le partitionnement des tables, la stratégie de clustering, les jointures coûteuses et le parallélisme des traitements. Ces optimisations peuvent réduire les temps de traitement de plusieurs heures à quelques minutes, avec un impact direct sur les coûts d'infrastructure cloud.
- Gestion des coûts cloud : il surveille et optimise la consommation des ressources cloud (compute, storage, networking). Sur des plateformes comme BigQuery, Snowflake ou Databricks, une optimisation intelligente des requêtes et du stockage peut réduire la facture de 30 à 50 % sans compromettre les performances.
- Scalabilité horizontale : il conçoit les architectures pour absorber la croissance des volumes de données. Qu'il s'agisse de passer de gigaoctets à téraoctets ou de téraoctets à pétaoctets, le Data Engineer anticipe les besoins de scalabilité et met en place les mécanismes nécessaires (partitionnement, sharding, auto-scaling).
Collaboration et support aux équipes data
- Support aux data scientists : le Data Engineer prépare les datasets d'entraînement pour les modèles de machine learning, met en place les feature stores et garantit la reproductibilité des expérimentations. Il travaille en binôme avec le Data Scientist pour s'assurer que les données sont au bon format, à la bonne granularité et avec la bonne fraîcheur.
- Support aux analystes et métiers : il crée les vues et les tables agrégées qui alimentent les dashboards et les rapports. Il forme les équipes métier à l'utilisation des données et les accompagne dans la formulation de leurs besoins data. Son objectif est de rendre les équipes autonomes dans l'exploitation de leurs données.
- Documentation et transfert de connaissances : il produit une documentation technique exhaustive (architecture, pipelines, modèle de données, runbooks opérationnels) et forme les équipes internes pour assurer la pérennité des solutions mises en place.
Compétences et stack technique
Hard skills indispensables
Un Data Engineer performant maîtrise un ensemble de compétences techniques qui couvrent l'ensemble de la chaîne de données :
- Langages de programmation : maîtrise avancée de Python pour le scripting, les transformations de données et l'intégration avec les frameworks de data engineering. Connaissance approfondie de SQL pour la modélisation et la manipulation des données relationnelles. Familiarité avec Scala ou Java pour les écosystèmes Spark et Kafka.
- Frameworks de traitement de données : expertise sur Apache Spark (PySpark) pour le traitement batch à grande échelle, Apache Kafka pour le streaming, dbt pour la transformation en SQL versionné et testé, et les outils ETL/ELT modernes (Airbyte, Fivetran, Meltano).
- Bases de données et stockage : connaissance approfondie des bases relationnelles (PostgreSQL, MySQL), des data warehouses cloud (BigQuery, Snowflake, Redshift), des bases NoSQL (MongoDB, Cassandra, DynamoDB) et des formats de stockage colonnaire (Parquet, Delta Lake, Apache Iceberg).
- Cloud et infrastructure : maîtrise des services data des principaux cloud providers (AWS : S3, Glue, Redshift, Kinesis ; GCP : BigQuery, Dataflow, Cloud Storage, Pub/Sub ; Azure : Synapse, Data Factory, Data Lake Storage). Capacité à architecturer des solutions cloud-native optimisées en coût et en performance.
- Orchestration : expertise sur Apache Airflow, Dagster ou Prefect pour l'orchestration des pipelines. Capacité à concevoir des DAG complexes avec gestion des dépendances, des retries, du monitoring et des alertes.
- DevOps et Infrastructure as Code : connaissance de Docker, Kubernetes, Terraform et des pipelines CI/CD pour automatiser le déploiement et la maintenance des plateformes de données.
- Data governance : compréhension des principes de catalogage, de lignage (data lineage), de qualité des données et de conformité réglementaire (RGPD).
Soft skills qui font la différence
- Rigueur et fiabilité : la moindre erreur dans un pipeline de données se propage à tous les systèmes en aval. Le Data Engineer fait preuve d'une rigueur exemplaire dans la conception, le test et le monitoring de ses pipelines. Il anticipe les cas limites et les modes de défaillance.
- Communication transversale : il dialogue aussi bien avec les équipes métier (pour comprendre les besoins) qu'avec les data scientists (pour livrer les bons datasets) et les équipes infrastructure (pour optimiser les ressources). Cette capacité à parler plusieurs langages est essentielle dans un rôle qui fait le pont entre des univers très différents.
- Pensée systémique : il comprend comment chaque composant de l'architecture de données interagit avec les autres et anticipe les effets de bord d'une modification. Cette vision holistique est ce qui distingue un Data Engineer senior d'un développeur qui fait du data engineering.
- Curiosité technique : l'écosystème data évolue rapidement. Le Data Engineer entretient une veille permanente sur les nouvelles technologies, les patterns d'architecture émergents et les bonnes pratiques de la communauté.
- Sens de l'optimisation : il recherche en permanence les gains de performance et les réductions de coût. Un pipeline plus rapide et moins coûteux est un pipeline meilleur, et le Data Engineer a cette obsession de l'efficience ancrée dans sa pratique quotidienne.
Outils du quotidien
- Apache Airflow / Dagster : orchestration des pipelines de données, planification des tâches, monitoring et alerting.
- dbt (data build tool) : transformation des données en SQL versionné, testé et documenté. dbt est devenu le standard de l'industrie pour la couche de transformation.
- Apache Spark / PySpark : traitement distribué de grands volumes de données en batch et en streaming.
- BigQuery / Snowflake : data warehouses cloud qui combinent stockage et calcul à la demande pour des requêtes analytiques performantes.
- Docker / Kubernetes : conteneurisation et orchestration des services de données pour un déploiement reproductible et scalable.
Comment Yield Studio intègre ce profil
Chez Yield Studio, le Data Engineer est le premier profil mobilisé dans tout projet impliquant de la donnée. Notre conviction est simple : sans fondations data solides, aucun projet d'IA ou d'analytics ne peut tenir ses promesses. C'est pourquoi nous investissons dès le démarrage dans la qualité de l'architecture de données.
La méthode Lean Lab appliquée au data engineering
En phase de Discovery, le Data Engineer réalise un audit de votre patrimoine data existant. Il cartographie vos sources de données, évalue leur qualité, identifie les lacunes et les incohérences, et propose une architecture cible alignée sur vos objectifs business. Cette phase de cadrage, souvent sous-estimée, permet d'éviter les refontes coûteuses en cours de projet. Le Data Engineer produit un schéma d'architecture, un inventaire des sources et un plan de migration qui servent de feuille de route pour la suite du projet.
En phase de Build, le Data Engineer construit les pipelines et l'infrastructure de données de manière itérative. Chaque sprint livre un incrément fonctionnel : un nouveau connecteur, une nouvelle table dans le data warehouse, un nouveau contrôle de qualité. Cette approche incrémentale permet de livrer de la valeur rapidement — les premières données exploitables sont disponibles en quelques semaines — tout en construisant progressivement une architecture robuste et scalable.
En phase de Growth, le Data Engineer optimise les performances, réduit les coûts d'infrastructure et met en place les mécanismes de monitoring qui garantissent la pérennité de la plateforme. Il forme les équipes internes à l'exploitation et à la maintenance des pipelines, et documente l'ensemble de l'architecture pour assurer un transfert de compétences complet.
Collaboration avec les autres profils
Le Data Engineer travaille en binôme étroit avec le Data Scientist pour préparer les données nécessaires aux modèles de machine learning. Il collabore avec l'ingénieur Machine Learning pour mettre en production les modèles entraînés et garantir la fiabilité des prédictions en conditions réelles. Il s'appuie sur le développeur Python pour les composants applicatifs qui interagissent avec la plateforme de données.
Ce modèle de collaboration en équipe data intégrée — Data Engineer, Data Scientist, ingénieur ML — est au coeur de notre approche en data engineering. Chaque profil apporte une expertise complémentaire qui, combinée, permet de livrer des solutions data de bout en bout : de la collecte des données brutes à la mise en production des modèles prédictifs, en passant par la construction des dashboards et des API de données.
Intégration dans l'équipe client
Le Data Engineer Yield Studio s'intègre dans votre organisation comme un membre à part entière de votre équipe data. Il participe à vos rituels, utilise vos outils et communique avec vos parties prenantes. Cette immersion est essentielle pour comprendre le contexte métier et les contraintes spécifiques de votre domaine. Le Data Engineer ne se contente pas de construire des pipelines techniques : il comprend la signification business des données qu'il manipule, ce qui lui permet de détecter les anomalies et de proposer des améliorations pertinentes.
Questions fréquentes
Quelle est la différence entre un Data Engineer et un Data Scientist ?
Le Data Engineer conçoit et maintient l'infrastructure de données : pipelines d'ingestion, transformations, data warehouse, orchestration, qualité des données. Il s'assure que les données sont disponibles, fiables et exploitables. Le Data Scientist, quant à lui, exploite ces données pour en extraire des insights et construire des modèles prédictifs. Il travaille sur l'analyse statistique, le machine learning et la visualisation. Ces deux rôles sont complémentaires et indissociables : sans Data Engineer, le Data Scientist passe 80 % de son temps à préparer les données ; sans Data Scientist, les données collectées par le Data Engineer restent sous-exploitées.
À quel moment de mon projet ai-je besoin d'un Data Engineer ?
Le Data Engineer doit intervenir dès le cadrage de tout projet impliquant de la donnée. Il est le premier profil data à mobiliser, car il construit les fondations sur lesquelles reposent tous les autres travaux. Si vous envisagez un projet de data science, de machine learning ou de business intelligence, commencez par évaluer l'état de votre infrastructure de données avec un Data Engineer. Un audit de quelques jours suffit pour identifier les chantiers prioritaires et dimensionner l'effort nécessaire.
Faut-il un Data Engineer à temps plein ou à temps partiel ?
Cela dépend du volume de données et de la complexité de votre architecture. Pour une PME avec quelques sources de données et des besoins d'analytics simples, un Data Engineer à temps partiel (2-3 jours par semaine) peut suffire pour mettre en place les fondations et assurer la maintenance. Pour une entreprise avec des dizaines de sources, des volumes importants et des cas d'usage avancés (machine learning, temps réel), un engagement à temps plein est recommandé pendant la phase de construction, suivi d'un passage à temps partiel pour la maintenance évolutive.
Quelles technologies le Data Engineer Yield Studio utilise-t-il ?
Nos Data Engineers maîtrisent un large éventail de technologies et recommandent la stack la plus adaptée à votre contexte. Pour le stockage, nous travaillons avec BigQuery, Snowflake, PostgreSQL et Delta Lake. Pour la transformation, nous utilisons dbt, Apache Spark et Python. Pour l'orchestration, Apache Airflow et Dagster. Pour le streaming, Apache Kafka et les services managés cloud. Le choix de la stack dépend de vos contraintes : volume de données, latence requise, compétences internes, budget et cloud provider existant.
Comment le Data Engineer garantit-il la qualité des données ?
Le Data Engineer met en place une stratégie de qualité des données à plusieurs niveaux. Au niveau des sources, il valide les schémas et détecte les changements de format. Au niveau des transformations, il implémente des tests unitaires et d'intégration avec dbt ou Great Expectations. Au niveau du data warehouse, il surveille la fraîcheur, la complétude et la cohérence des données. Et au niveau du monitoring, il met en place des alertes automatiques qui préviennent les équipes dès qu'une anomalie est détectée. Cette approche proactive de la qualité des données est ce qui distingue une plateforme data professionnelle d'un assemblage de scripts fragiles.
Quel est le coût d'un projet de data engineering ?
Le coût varie considérablement en fonction de la complexité du projet. Un audit data et la mise en place d'une architecture de base (quelques sources, un data warehouse, des pipelines simples) représente un investissement de quelques semaines. Un projet complet de plateforme de données (dizaines de sources, streaming, gouvernance, monitoring) s'étend sur 3 à 6 mois. L'investissement se rentabilise rapidement par les gains de productivité des équipes data et par la qualité des décisions prises grâce à des données fiables. Contactez-nous pour obtenir une estimation adaptée à votre contexte.