L'ingénieur Machine Learning met en production vos modèles d'IA avec fiabilité et scalabilité. Il transforme les prototypes data science en systèmes robustes.
Ce qu'un Ingénieur Machine Learning apporte à votre projet
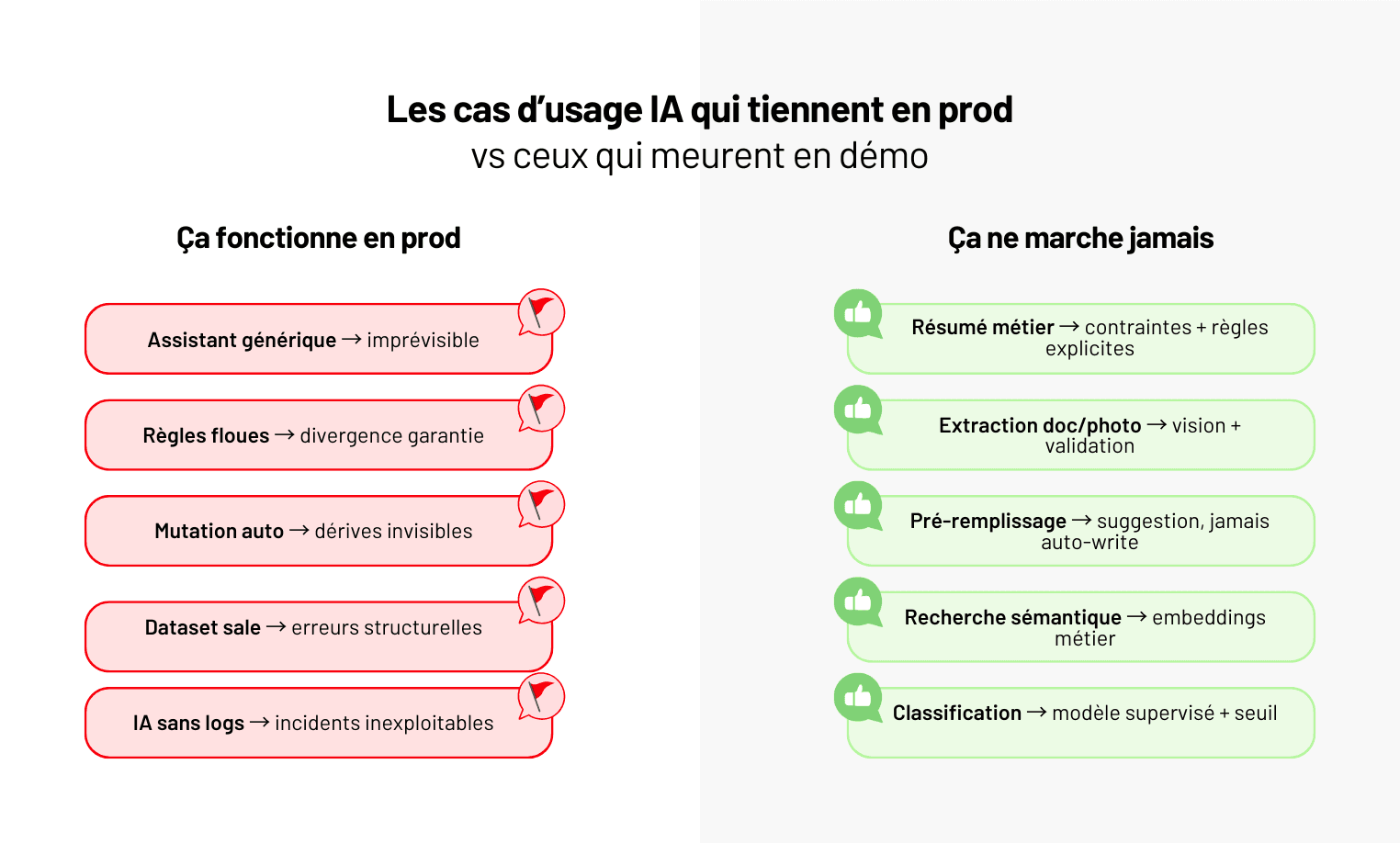
L'ingénieur Machine Learning (ML Engineer) est le profil qui fait le pont entre l'expérimentation data science et la production industrielle. Dans beaucoup d'organisations, les modèles de machine learning restent bloqués au stade du prototype dans un notebook Jupyter, sans jamais atteindre la production. L'ingénieur ML est celui qui résout ce problème : il transforme les modèles expérimentaux en systèmes robustes, scalables et maintenables qui génèrent de la valeur en continu.
Le fossé entre un prototype de data science et un système ML en production est considérable. Un modèle qui fonctionne dans un notebook avec des données statiques doit, en production, gérer des millions de requêtes par jour, répondre en quelques millisecondes, traiter des données imparfaites et variables, résister aux pannes, être mis à jour régulièrement et être monitoré en permanence. L'ingénieur ML maîtrise l'ensemble de ces défis et construit l'infrastructure qui transforme un prototype prometteur en un système de production fiable.
Ce profil est indispensable dès que vous souhaitez déployer un modèle de machine learning en production, que ce soit pour alimenter une API de recommandation, automatiser une classification de documents, intégrer de la prédiction dans votre application métier ou déployer un système de computer vision sur une chaîne de production. L'ingénieur ML intervient en aval du Data Scientist, qui a conçu et entraîné le modèle, et travaille en étroite collaboration avec le Data Engineer qui fournit les données.
Pour donner un ordre de grandeur du problème, une étude de Gartner estime que seulement 53 % des projets de machine learning passent du prototype à la production. Les causes principales de cet échec sont techniques : manque d'infrastructure MLOps, incapacité à gérer le versioning des modèles, absence de monitoring de la performance en production, pipelines d'entraînement non reproductibles. L'ingénieur ML adresse chacune de ces causes et maximise vos chances de transformer un investissement en data science en valeur business tangible.
Chez Yield Studio, nous considérons l'ingénieur ML comme un profil essentiel dans toute équipe data qui vise l'impact. Nos projets de machine learning intègrent systématiquement ce profil pour garantir que les modèles développés par nos data scientists atteignent la production dans des conditions optimales de fiabilité et de performance. Cette approche intégrée, qui couvre l'ensemble du cycle de vie du modèle — de l'expérimentation au monitoring en production — est ce qui distingue une prestation de machine learning professionnelle d'une prestation purement exploratoire.
Missions concrètes dans un projet client
L'ingénieur Machine Learning chez Yield Studio intervient sur des missions qui couvrent l'ensemble du cycle de vie opérationnel d'un système de machine learning.
Mise en production des modèles (MLOps)
- Containerisation et packaging des modèles : l'ingénieur ML encapsule les modèles dans des containers Docker reproductibles, avec toutes leurs dépendances. Cette containerisation garantit que le modèle se comporte de manière identique en développement, en staging et en production, éliminant les problèmes de « ça marche sur ma machine ». Il crée des images Docker optimisées pour minimiser la taille et le temps de démarrage.
- Déploiement d'API de serving : il expose les modèles via des API REST ou gRPC qui permettent aux applications clientes de soumettre des requêtes et de recevoir des prédictions en temps réel. Il choisit le framework de serving le plus adapté (FastAPI, TorchServe, TensorFlow Serving, Triton Inference Server) en fonction des contraintes de latence, de débit et de complexité du modèle.
- Pipelines d'entraînement automatisés : il construit des pipelines reproductibles qui automatisent l'ensemble du cycle d'entraînement : récupération des données, preprocessing, entraînement, évaluation, validation et déploiement. Ces pipelines permettent de re-entraîner les modèles de manière régulière et automatisée, sans intervention manuelle.
- Versioning des modèles et des données : il met en place un système de versioning qui trace chaque version du modèle (architecture, hyperparamètres, poids), les données d'entraînement utilisées et les métriques de performance obtenues. Ce versioning est essentiel pour la reproductibilité, l'audit et le rollback en cas de régression.
- CI/CD pour le machine learning : il construit des pipelines d'intégration et de déploiement continus spécifiques au ML, qui incluent des étapes de validation automatique (tests unitaires, tests d'intégration, tests de performance, tests de non-régression) avant chaque déploiement en production.
Optimisation des performances
- Optimisation de l'inférence : l'ingénieur ML réduit la latence et le coût d'inférence des modèles en appliquant des techniques d'optimisation : quantification (réduction de la précision des poids), pruning (suppression des neurones peu contributifs), distillation (transfert des connaissances d'un grand modèle vers un modèle plus petit et plus rapide), et compilation pour des runtimes optimisés (ONNX Runtime, TensorRT).
- Scaling horizontal et vertical : il configure l'infrastructure pour absorber les variations de charge. En période de pointe, le système scale automatiquement pour maintenir des temps de réponse acceptables ; en période creuse, il réduit les ressources pour minimiser les coûts. Il utilise Kubernetes et des auto-scalers pour gérer cette élasticité de manière transparente.
- Batch processing vs real-time : selon le cas d'usage, l'ingénieur ML choisit la stratégie de serving la plus adaptée. Pour les recommandations produit, un traitement batch quotidien peut suffire. Pour la détection de fraude, une inférence en temps réel est nécessaire. Pour la modération de contenu, une approche asynchrone est souvent le meilleur compromis. Il conçoit l'architecture qui répond aux contraintes de latence et de coût spécifiques à chaque cas d'usage.
- Optimisation des coûts GPU/CPU : il sélectionne le type d'instance le plus adapté (GPU vs CPU, type de GPU, spot instances) et optimise l'utilisation des ressources pour minimiser la facture cloud tout en maintenant les performances requises. Pour les modèles qui ne nécessitent pas de GPU en inférence, il met en place des optimisations CPU qui réduisent drastiquement les coûts.
Monitoring et maintenance des systèmes ML
- Monitoring de la performance des modèles : l'ingénieur ML met en place des dashboards qui suivent en continu les métriques de performance du modèle en production (accuracy, latence, débit, taux d'erreur). Il configure des alertes qui préviennent l'équipe dès qu'une métrique dépasse un seuil critique, permettant une intervention rapide avant que la dégradation n'impacte les utilisateurs.
- Détection du data drift et du concept drift : il surveille la distribution des données d'entrée (data drift) et la relation entre les features et la cible (concept drift). Quand les données en production divergent significativement des données d'entraînement, le modèle peut perdre en précision. L'ingénieur ML détecte ces dérives en temps réel et déclenche un ré-entraînement automatique si nécessaire.
- A/B testing des modèles : il met en place l'infrastructure pour comparer les performances de différentes versions du modèle en production (shadow mode, canary deployment, A/B testing). Cette approche permet de valider qu'une nouvelle version est effectivement meilleure que la précédente avant de la déployer pour tous les utilisateurs.
- Logging et auditabilité : il enregistre chaque prédiction (input, output, timestamp, version du modèle) pour permettre l'audit, le debugging et l'analyse post-hoc. Cette traçabilité est essentielle dans les domaines réglementés (finance, santé) et pour l'amélioration continue des modèles.
Intégration dans les applications
- Intégration avec les systèmes existants : l'ingénieur ML intègre les prédictions du modèle dans les workflows métier existants. Que ce soit dans un CRM, un ERP, une application mobile ou un site e-commerce, il conçoit les interfaces (API, webhooks, événements) qui permettent aux systèmes existants de consommer les prédictions de manière transparente.
- Feature stores : il met en place un feature store qui centralise et sert les features nécessaires aux modèles en temps réel. Le feature store garantit la cohérence entre les features utilisées à l'entraînement et celles utilisées en inférence, éliminant un source majeure de bugs dans les systèmes ML.
- Edge deployment : pour les cas d'usage nécessitant une inférence locale (IoT, mobile, embarqué), l'ingénieur ML optimise et déploie les modèles directement sur les devices. Il utilise des frameworks comme TensorFlow Lite, ONNX Runtime Mobile ou CoreML pour exécuter les modèles dans des environnements à ressources contraintes.
Compétences et stack technique
Hard skills indispensables
- Ingénierie logicielle : l'ingénieur ML est avant tout un ingénieur logiciel solide. Il maîtrise les principes de clean code, de design patterns, de tests automatisés et de CI/CD. Cette rigueur d'ingénierie est ce qui différencie un système ML en production d'un script de data science : le premier est maintenable, testable et fiable ; le second ne l'est pas.
- Python et écosystème ML : maîtrise experte de Python et des frameworks de ML (PyTorch, TensorFlow, scikit-learn) avec un focus sur les aspects production : serialisation des modèles, optimisation de l'inférence, gestion de la mémoire, parallélisation.
- MLOps et infrastructure : expertise sur les plateformes MLOps (MLflow, Kubeflow, Vertex AI, SageMaker), les frameworks de serving (FastAPI, TorchServe, Triton), les outils de monitoring (Prometheus, Grafana, Evidently) et les orchestrateurs (Kubernetes, Docker).
- Cloud computing : connaissance approfondie des services ML des cloud providers (AWS SageMaker, GCP Vertex AI, Azure ML) et capacité à concevoir des architectures cloud-native optimisées pour les workloads ML.
- Optimisation de modèles : maîtrise des techniques de quantification, pruning, distillation et compilation de modèles pour optimiser la latence et le coût d'inférence. Connaissance des runtimes d'inférence spécialisés (ONNX Runtime, TensorRT, vLLM).
- Data engineering de base : compréhension des architectures de données (data lakes, data warehouses), des formats de données (Parquet, Avro, Protocol Buffers) et des outils de traitement (Spark, Kafka) suffisante pour construire des pipelines de données ML robustes.
- Sécurité et conformité ML : connaissance des risques spécifiques au ML (adversarial attacks, data poisoning, model extraction) et des mesures de protection appropriées. Compréhension des enjeux réglementaires (AI Act, RGPD) et capacité à concevoir des systèmes conformes.
Soft skills qui font la différence
- Pragmatisme et sens des priorités : l'ingénieur ML sait distinguer l'essentiel de l'accessoire. Il ne cherche pas à construire la plateforme MLOps parfaite dès le premier jour, mais met en place une infrastructure minimale viable qui peut être enrichie progressivement. Il optimise les modèles là où les gains sont les plus significatifs et ne perd pas de temps sur des micro-optimisations sans impact.
- Capacité de communication : il dialogue efficacement avec les data scientists (pour comprendre les modèles et leurs contraintes), les ingénieurs logiciels (pour intégrer les modèles dans les applications) et les décideurs (pour expliquer les compromis entre performance, coût et latence).
- Orientation fiabilité : l'ingénieur ML a une culture SRE (Site Reliability Engineering) appliquée au ML. Il pense en termes de SLO (Service Level Objectives), de résilience et de recovery. Son objectif est que les systèmes ML fonctionnent de manière fiable, 24h/24, sans intervention manuelle.
- Apprentissage continu : l'écosystème MLOps évolue rapidement. L'ingénieur ML se tient à jour sur les nouvelles techniques d'optimisation, les nouveaux outils de serving et les nouvelles architectures cloud. Il évalue régulièrement si les choix technologiques actuels sont toujours optimaux.
- Esprit d'équipe : l'ingénieur ML travaille à l'intersection de plusieurs disciplines (data science, ingénierie logicielle, infrastructure). Il comprend les contraintes et les priorités de chaque discipline et facilite la collaboration entre des profils aux cultures différentes.
Outils du quotidien
- MLflow / Weights & Biases : tracking des expérimentations, versioning des modèles, gestion du registry de modèles et orchestration du cycle de vie ML.
- Docker / Kubernetes : containerisation des modèles, orchestration du déploiement, auto-scaling et gestion de l'infrastructure.
- FastAPI / TorchServe : frameworks de serving pour exposer les modèles via des API performantes et scalables.
- Prometheus / Grafana : monitoring des métriques de performance (latence, débit, erreurs) et des métriques ML (accuracy, drift) en production.
- Terraform / Pulumi : Infrastructure as Code pour provisonner et gérer l'infrastructure cloud de manière reproductible et versionnée.
Comment Yield Studio intègre ce profil
Chez Yield Studio, l'ingénieur Machine Learning est un profil clé dans tous nos projets qui impliquent du ML en production. Notre conviction est que la valeur d'un modèle de machine learning se mesure en production, pas dans un notebook. C'est pourquoi nous intégrons l'ingénieur ML dès les phases amont du projet, pour que les choix de modélisation du Data Scientist soient compatibles avec les contraintes de production dès le départ.
La méthode Lean Lab appliquée au MLOps
En phase de Discovery, l'ingénieur ML évalue l'infrastructure existante, identifie les contraintes techniques (latence, débit, disponibilité, conformité) et définit l'architecture MLOps cible. Il estime les coûts d'infrastructure et les compare à la valeur business attendue pour valider la viabilité économique du projet. Cette évaluation précoce évite les mauvaises surprises : il est plus simple de choisir un modèle adapté aux contraintes de production dès le départ que de découvrir après 3 mois de data science que le modèle choisi est trop lent ou trop coûteux à déployer.
En phase de Build, l'ingénieur ML travaille en parallèle du Data Scientist. Pendant que le Data Scientist affine ses modèles, l'ingénieur ML construit les pipelines d'entraînement, l'infrastructure de serving et les systèmes de monitoring. Dès qu'un modèle atteint un niveau de performance satisfaisant, il est mis en production en quelques heures grâce à l'infrastructure préparée en amont. Cette approche parallèle réduit considérablement le time-to-production.
En phase de Growth, l'ingénieur ML met en place les boucles d'amélioration continue : monitoring de la performance, détection de drift, ré-entraînement automatique, A/B testing des nouvelles versions. Il optimise les coûts d'infrastructure et la latence pour maximiser le ratio valeur/coût du système ML. Il forme les équipes internes à l'exploitation de la plateforme MLOps pour assurer une prise en main autonome.
Collaboration avec les autres profils
L'ingénieur ML fait le lien entre le monde de la data science et le monde de l'ingénierie logicielle. Il collabore quotidiennement avec le Data Scientist pour comprendre les modèles, leurs dépendances et leurs contraintes. Il travaille avec le Data Engineer pour accéder aux données d'entraînement et de serving. Et il s'appuie sur le développeur Python pour les intégrations applicatives.
Cette collaboration transversale est structurée autour de rituels spécifiques : des revues de modèle où le Data Scientist présente ses expérimentations et l'ingénieur ML évalue leur déployabilité, des sessions d'architecture où les choix d'infrastructure sont discutés collectivement, et des post-mortems quand un incident de production survient pour en tirer les enseignements.
Questions fréquentes
Mon Data Scientist peut-il aussi faire le travail d'un ingénieur ML ?
C'est une configuration fréquente dans les petites équipes, mais elle présente des limites. Un Data Scientist peut mettre en production un modèle simple, mais il n'a généralement pas l'expertise en ingénierie logicielle, en infrastructure cloud et en monitoring nécessaire pour construire un système ML fiable à grande échelle. Si votre modèle est critique pour le business (il influence des décisions importantes, il est utilisé par un grand nombre d'utilisateurs), investir dans un ingénieur ML dédié est fortement recommandé. Le Data Scientist sera également plus productif s'il peut se concentrer sur la modélisation plutôt que sur les problèmes d'infrastructure.
Quelle est la différence entre un ingénieur ML et un ingénieur DevOps ?
Un ingénieur DevOps se concentre sur l'infrastructure applicative classique : CI/CD, monitoring, scalabilité, sécurité. Un ingénieur ML partage ces compétences mais y ajoute une expertise spécifique au machine learning : versioning des modèles, gestion du data drift, optimisation de l'inférence, pipelines d'entraînement, feature stores. Le ML pose des défis uniques (reproductibilité des expérimentations, dépendance aux données, dégradation silencieuse des performances) que l'ingénierie DevOps classique ne couvre pas.
Quand ai-je besoin d'un ingénieur ML plutôt que d'un Data Scientist ?
Vous avez besoin d'un ingénieur ML dès que vous souhaitez passer du stade expérimental (notebooks, rapports) au stade production (API, intégration applicative, automatisation). Si votre Data Scientist a développé un modèle prometteur et que vous voulez l'intégrer dans votre application ou vos processus métier, c'est le moment de faire appel à un ingénieur ML. Plus tôt il intervient, plus les choix de modélisation seront compatibles avec les contraintes de production.
Combien coûte l'infrastructure MLOps ?
Le coût de l'infrastructure MLOps varie considérablement en fonction de la complexité du système : nombre de modèles en production, volume de requêtes, exigences de latence, besoin en GPU. Pour un premier modèle en production avec un volume modéré, les coûts cloud se situent entre quelques centaines et quelques milliers d'euros par mois. L'ingénieur ML optimise systématiquement ces coûts en sélectionnant les bons types d'instances, en utilisant des spot instances quand possible et en optimisant l'inférence pour réduire la consommation de ressources.
Comment l'ingénieur ML gère-t-il les modèles de type LLM et IA générative ?
Les modèles de type LLM (Large Language Models) et d'IA générative posent des défis spécifiques en termes de déploiement : taille des modèles (plusieurs gigaoctets), coût d'inférence élevé (GPU nécessaire), latence importante (génération token par token) et gestion des prompts. L'ingénieur ML met en place des architectures adaptées : caching des réponses fréquentes, streaming de la génération, quantification des modèles pour réduire les coûts, orchestration des appels API vers les providers (OpenAI, Anthropic, modèles open source). Il met également en place le monitoring spécifique aux LLM : détection des hallucinations, suivi de la qualité des réponses, gestion des coûts par token.
L'ingénieur ML travaille-t-il uniquement avec Python ?
Python est le langage principal de l'écosystème ML, mais l'ingénieur ML utilise également d'autres technologies selon les besoins : Go ou Rust pour des services de serving à très haute performance, SQL pour les requêtes de données, YAML/HCL pour l'Infrastructure as Code, Bash pour l'automatisation. L'essentiel est que l'ingénieur ML choisisse le bon outil pour chaque tâche plutôt que de tout faire en Python.